
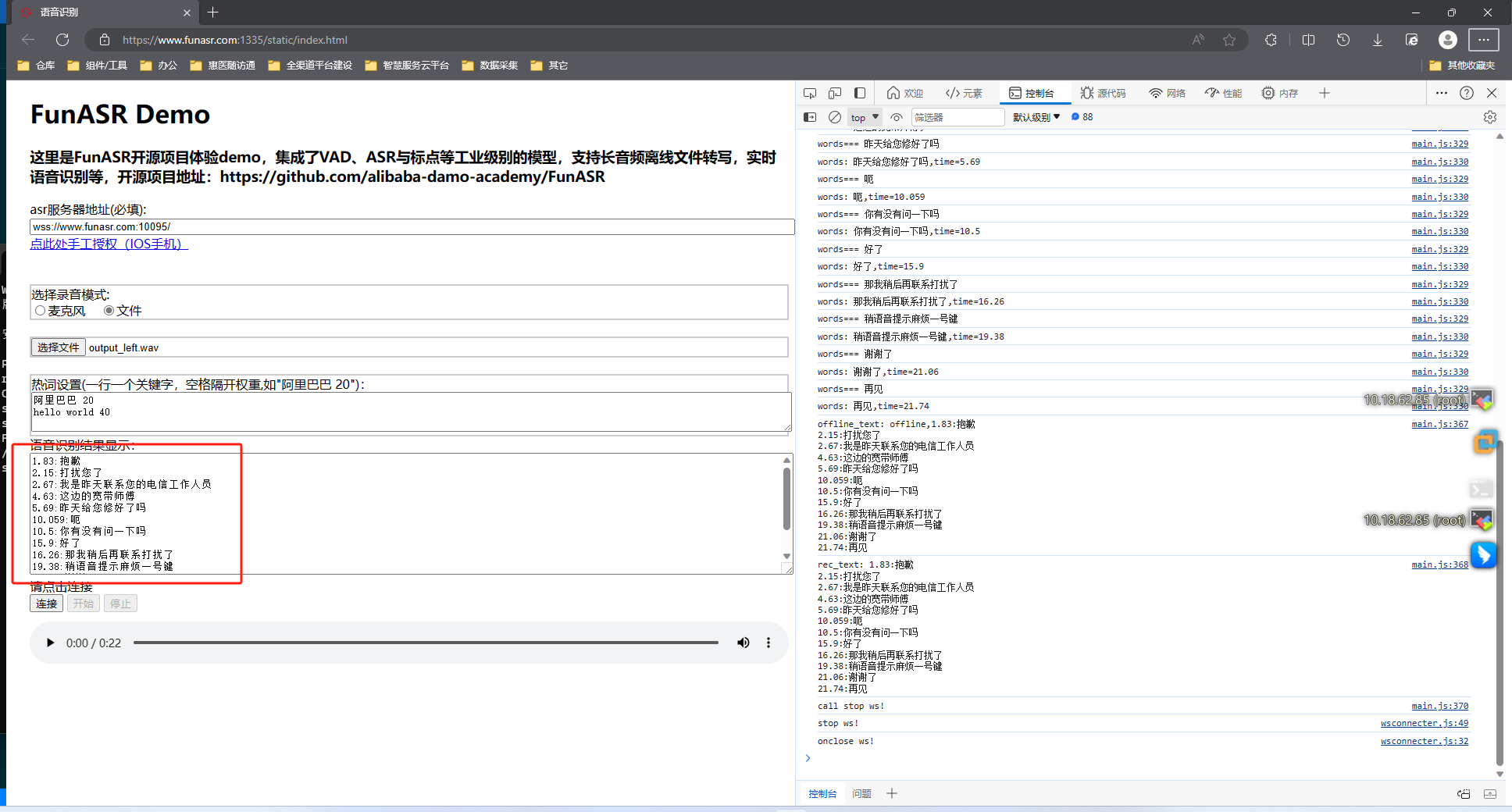
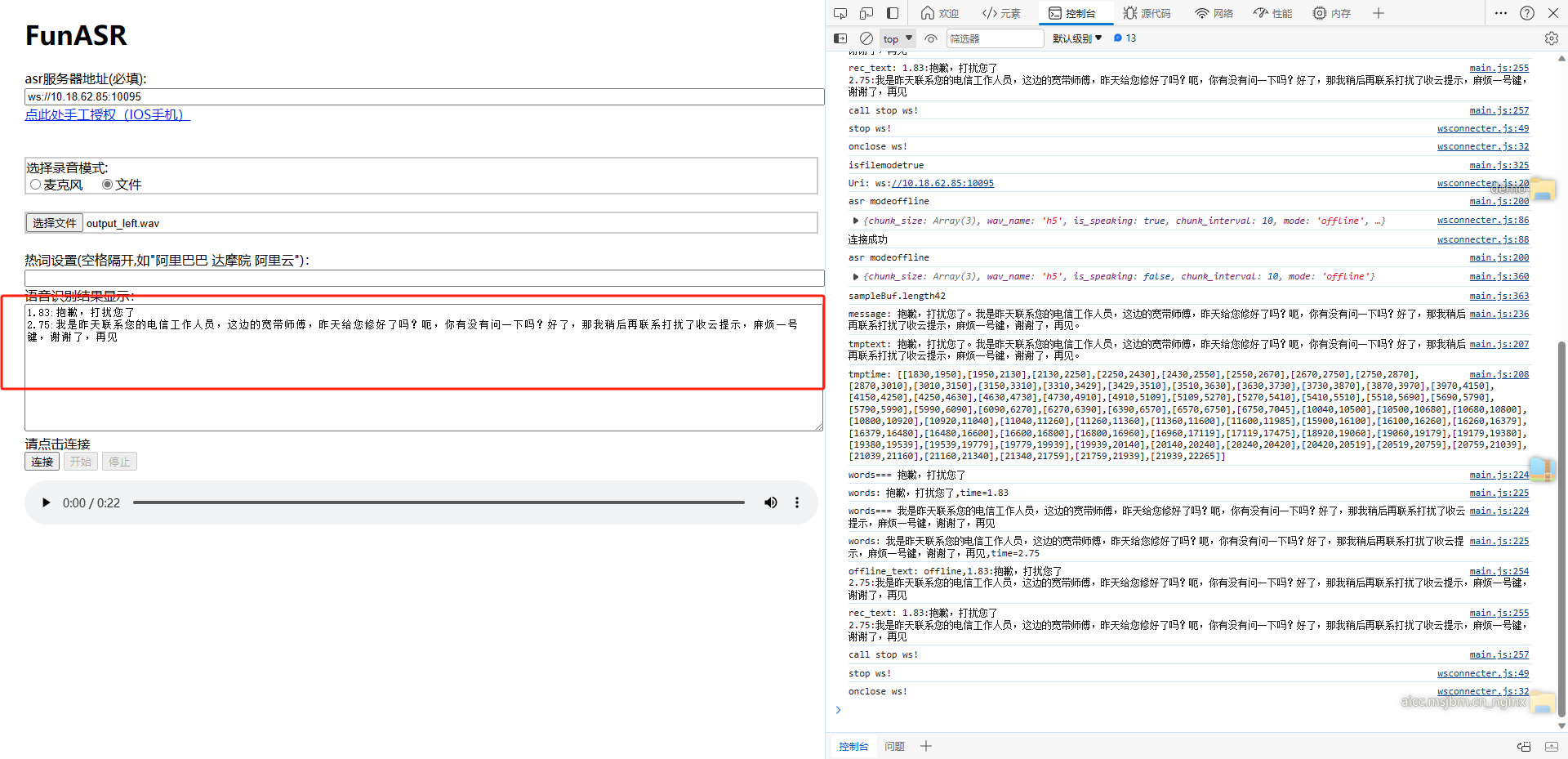
modelscope-funasr本地部署0.3.0时间戳模型后,时间戳切的和官网的不太一样,怎么像官网一样多切几段呢?
在本地部署 ModelScope 的 FunASR 模型(如时间戳模型 0.3.0 版本)后,如果发现时间戳切分结果与官网的示例不一致,可能是因为模型配置或参数设置存在差异。以下是如何调整配置以实现更细粒度的时间戳切分的专业指导:
确保您使用的模型版本和配置与官网一致。根据知识库中的说明,部署时需要明确指定 MODEL_ID、TASK 和 REVISION 参数。例如: - MODEL_ID: 确保使用的是 FunASR 时间戳模型的正确 ID。 - REVISION: 确保版本号为 v0.3.0 或其他官方推荐的版本。
如果模型版本不一致,可能会导致时间戳切分逻辑不同。建议重新获取正确的模型配置并重新部署。
FunASR 模型的时间戳切分行为通常由推理时的参数控制。您可以尝试调整以下关键参数以获得更细粒度的切分结果:
max_segment_duration该参数控制每个时间戳段的最大持续时间。降低此值可以生成更多、更短的时间戳段。例如:
{
"max_segment_duration": 5.0 // 单位:秒
}
将 max_segment_duration 设置为较小值(如 5 秒),可以让模型生成更短的切分段。
min_silence_duration该参数定义了静音段的最小持续时间。如果静音段过短,模型可能会将其忽略,从而导致时间戳切分不够细致。例如:
{
"min_silence_duration": 0.3 // 单位:秒
}
将 min_silence_duration 设置为较小值(如 0.3 秒),可以检测到更短的静音段,从而增加切分点。
speech_threshold该参数用于控制语音活动检测的灵敏度。较低的阈值会检测到更多的语音片段,从而生成更多的时间戳段。例如:
{
"speech_threshold": 0.4
}
在调整参数后,可以通过以下步骤验证模型服务是否按预期工作:
如果您通过 PAI 平台部署了模型,可以使用 WebUI 进行测试: 1. 在 WebUI 页面左侧的测试内容文本框中输入音频数据。 2. 单击执行测试,观察右侧返回的时间戳切分结果。 3. 根据结果进一步调整参数。
如果通过 API 调用模型服务,可以构造请求数据并发送 POST 请求。例如:
curl -XPOST http://localhost:8000/inference \
-H "Content-Type: application/json" \
-d '{
"audio_file": "path/to/audio.wav",
"max_segment_duration": 5.0,
"min_silence_duration": 0.3,
"speech_threshold": 0.4
}'
检查返回的 JSON 数据,确认时间戳切分是否符合预期。
如果调整参数后仍然无法达到官网示例的效果,建议对比以下内容: - 输入数据: 确保测试音频文件与官网示例一致。 - 模型版本: 确保本地部署的模型版本与官网一致。 - 默认参数: 查阅官网文档,确认是否有其他未公开的默认参数影响了时间戳切分。
通过以上步骤,您可以逐步调整本地部署的时间戳模型,使其切分结果更接近官网示例。如果问题仍未解决,建议联系 ModelScope 技术支持团队,提供详细的配置和测试数据以获取进一步帮助。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352
