
文字识别OCR有一个【表格信息抽取】创建模型后,就一直卡住了,能帮忙看下吗?
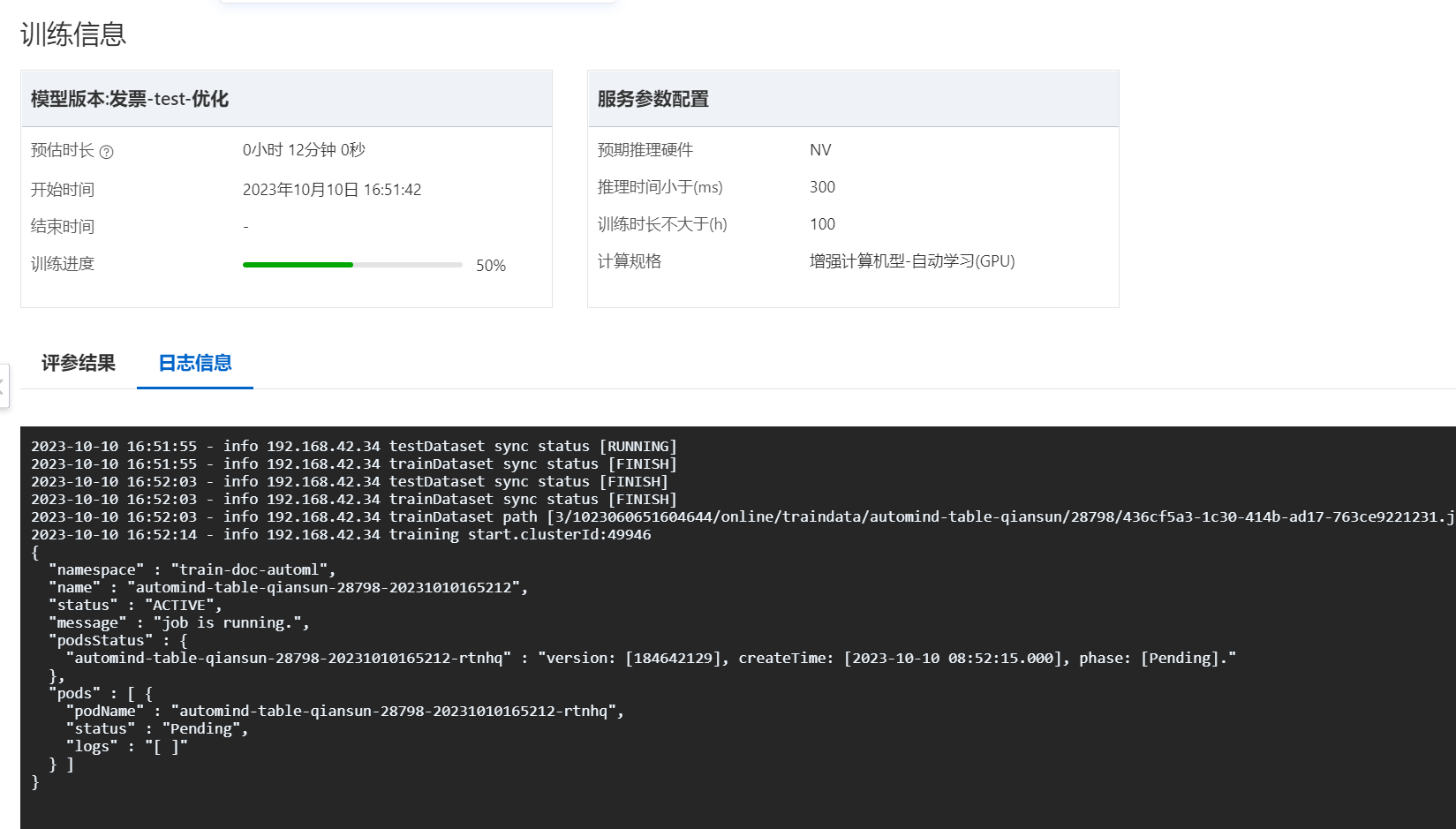

数据是上方发票样式的 20个
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
表格信息抽取https://help.aliyun.com/document_detail/603351.html?spm=a2c4g.11186623.0.i5#83b71210a9o05
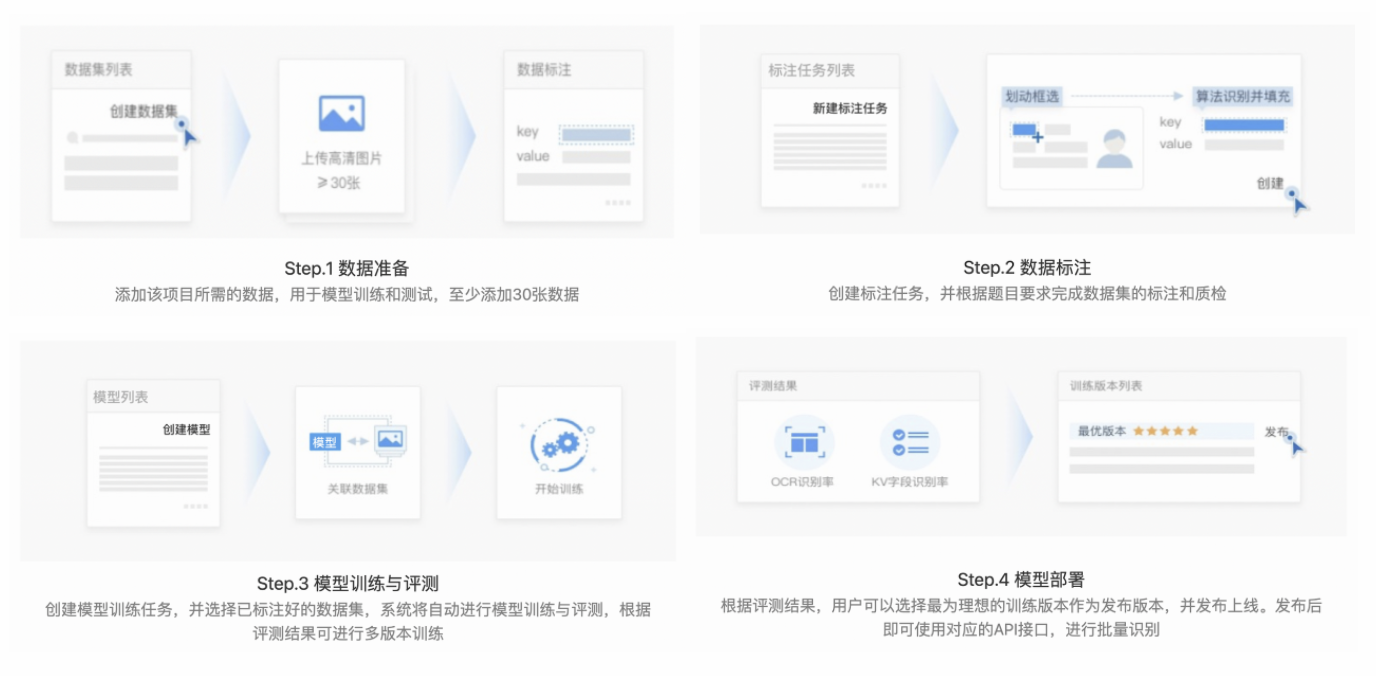
创建「表格信息抽取」流程如下图,开始模型训练需要至少 20 个训练数据。
提示建议:
数据准备有什么具体要求?
数据集可上传图片、文档、压缩包;
文档,支持不超过20M且后缀为pdf的文件,仅支持单页pdf;
图片,支持不超过10M且后缀为jpg、jpeg、png的文件;
压缩包,仅支持zip格式,且单zip包不超过20M。
单张图片最长边不超过8192像素,最短边不小于15像素。当长边超过1024像素时,长宽比不超过50 :1。
至少准备20-30份以上同类任务的数据用于模型训练与评测。
如何获得更好识别效果?
在产品功能范围的任务,数据质量越高,识别与抽取效果越好,字迹清晰端正的数据能有更高的准确率。
单字大小保持在10-50像素内,以获得较好的识别效果。
数据来源于真实业务场景,且类型与版式完整覆盖。


