文字识别OCR这个识别,咋都跑偏了,而且非常不准,请问,如何改善?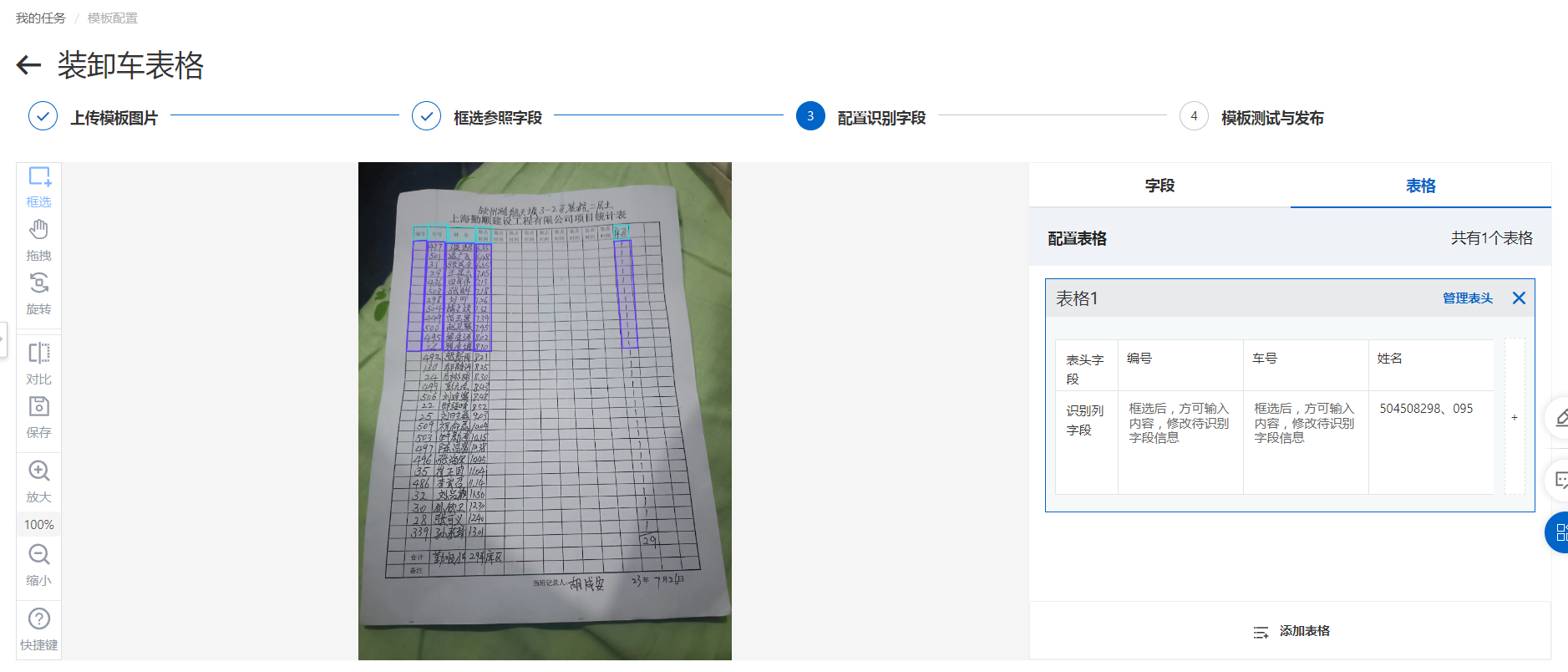
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,阿里云文字识别OCR在使用中确实可能会出现一些误识别的情况,如何改善呢?
图片处理优化:尝试使用图像处理技术,对图片进行优化,可以提高识别准确率。例如:调整亮度、对比度、去除噪声等。
图片分辨率:尽量使用高分辨率的图片,这样能够提高识别准确率。
字体选择:使用OCR识别时,应尽量选择一些常见的字体,这样识别准确率会更高。
增加样本:为了提高识别准确率,可以增加样本量,这样能让OCR算法更加智能化。
调整参数:针对不同的图片,可以调整阿里云OCR识别API的参数,来达到更好的识别效果。
选择合适的API:阿里云OCR识别API有多种类型,根据需要选择合适的API,例如身份证识别、营业执照识别、银行卡识别等。
总之,OCR识别是一项复杂的任务,需要多方面的优化来提高识别准确率。
如果文字识别(OCR)的识别结果偏离预期且准确性非常低,以下是一些改善OCR识别准确性的建议:
图像质量优化:确保输入的图像质量良好。清晰、高分辨率的图像通常能提供更好的识别结果。避免模糊、光照不足、倾斜或变形等问题。可以尝试使用图像处理工具对图像进行增强、去噪或调整亮度/对比度。
字体和字号匹配:确保OCR系统能正确匹配文本所使用的字体和字号。如果文本使用非常特殊或不常见的字体,OCR系统可能无法正确识别。尽量使用OCR系统支持的常见字体和字号。
文本区域标注:如果OCR系统在识别时无法正确定位文本区域,可以尝试手动标注或提供更明确的文本区域信息。使用框或多边形标注要识别的文本区域,以帮助OCR系统准确定位和识别。
训练数据优化:某些OCR系统允许通过自定义训练模型来提高识别效果。您可以收集并提供更多与您的应用场景和文本类型相似的训练数据,以帮助OCR系统更好地适应您的需求。
多样性数据集:确保使用的训练数据集具有多样性。包括不同字体、大小、颜色、背景和布局的图像,以增加OCR系统的适应性。
OCR引擎选择:尝试使用不同的OCR引擎或服务,因为不同的引擎可能在不同场景下具有不同的表现。您可以尝试使用多个OCR引擎并比较其识别结果。
后处理和纠错:OCR识别结果可能包含错误或识别偏差。您可以使用后处理技术,例如文本校正、语言模型或规则来纠正和修复识别结果。
可以尝试以下方法来改善识别质量:
图像质量:确保输入的图像质量良好。清晰、高分辨率的图像通常能提供更准确的识别结果。避免模糊、倾斜、过暗或过亮的图像。
图像预处理:在进行OCR之前对图像进行适当的预处理。例如,可以进行图像去噪、灰度调整、二值化、平滑等操作,以减少干扰和噪声,并增强文字的可读性。
字体和样式:确保OCR系统熟悉并支持所使用的字体和样式。有些OCR系统可能对某些特殊字体或样式的文字识别效果不佳。在选择OCR服务时,了解其对各种字体和样式的支持情况很重要。
语言和字典:确保OCR系统配置正确的语言和字典设置。如果输入的文本是特定语种或领域的专业术语,可能需要配置相应的语言模型或字典。
训练和优化:对于一些OCR服务,你可以通过自定义训练和优化来提高识别准确性。这可能涉及到提供更多的训练数据、标注字符或文字样本,并进行模型调整和优化。
后处理和校正:对于OCR结果,可以应用后处理技术来进一步提升准确性。例如,使用自然语言处理(NLP)技术进行文字校正、语法纠错和上下文理解。
经验调优:根据实际情况和需求,不断尝试优化参数设置和配置,以获得更好的识别结果。这可能包括调整图像处理、字体匹配、语言模型等方面的参数。
提高图像质量:OCR技术依赖于图像质量,如果图像模糊、噪声大或者光线不足,识别准确率就会降低。因此,您可以尝试使用更清晰、更干净的图像来提高OCR的识别效果。
调整模板:根据OCR识别的结果,调整模板的大小、位置、角度等,以提高识别准确率。
调整参数:OCR技术需要一些参数来控制识别的效果,例如阈值、最小字体大小等,可以尝试调整这些参数,以提高识别准确率。
使用深度学习技术:深度学习技术可以提高OCR的识别准确率,例如卷积神经网络、循环神经网络等,可以尝试使用这些技术来改进OCR的识别效果。
您好,文字识别OCR文档自学习表格信息抽取模型,如果想要提高识别准确率的话,首先您需要保证上传的表格图片满足以下条件:
1.单张图片最长边不超过8192像素,最短边不小于15像素。当长边超过1024像素时,长宽比不超过50 :1;
2.单字大小保持在10-50像素内,以获得较好的识别效果;
3.字迹清晰端正的数据能有更高的准确率。
另外模型训练至少准备20-30份以上同类任务的数据用于模型训练与评测,从而提高表格信息抽取的准确率。
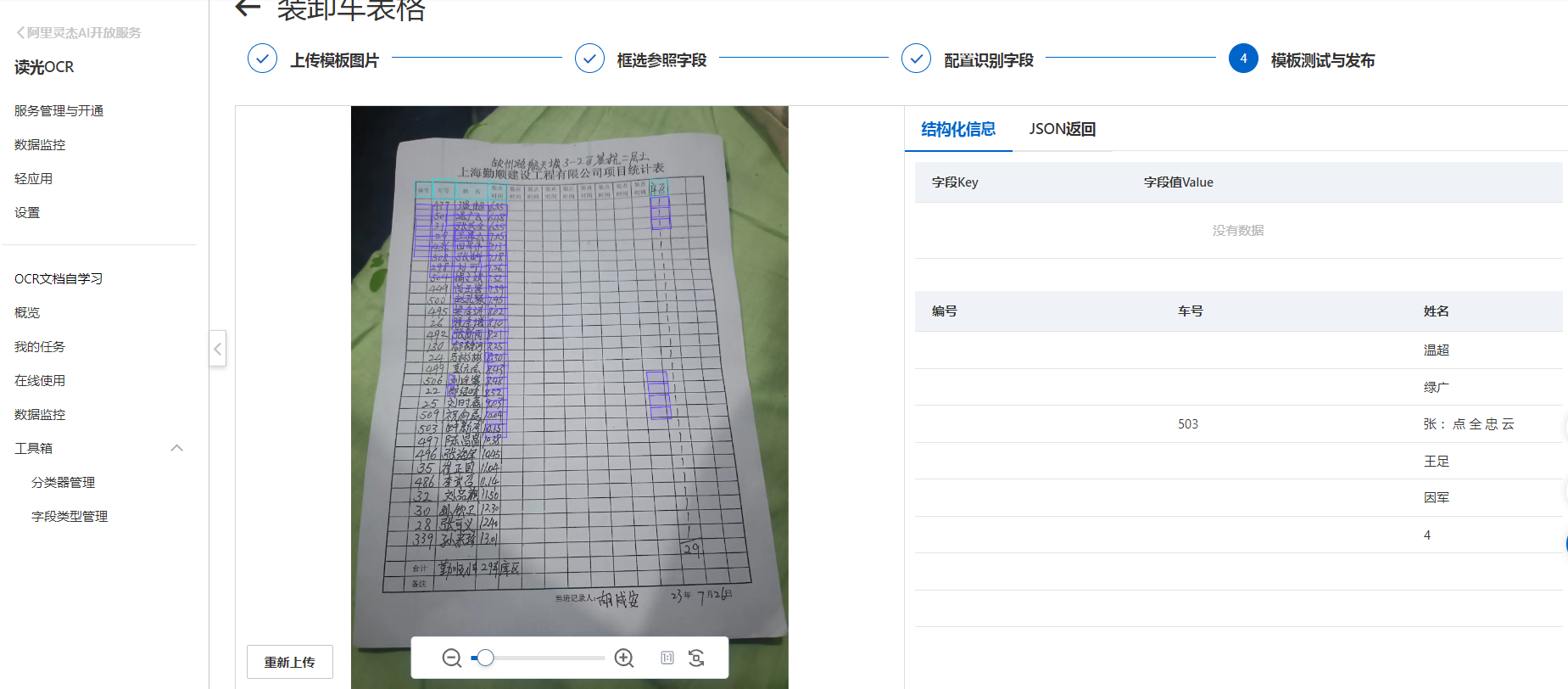
你好,识别的准备率跟图像质量关系较大,图片角度建议平铺拍摄,另外你这个是手写字体,建议使用通用手写体识别。
识别字段配置,表格列需要把整列表格都框选完整。参考字段配置,您可以把之前框的参考字段都删了看看效果。另外模版图片最好选一张较为清晰端正的图片。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”

如果文字识别OCR的结果不准确或偏离预期,以下是一些改善准确率的方法:
图像质量优化:确保输入图像的质量良好,图像清晰度、对比度和光照条件等因素都会对识别结果产生影响。可以尝试进行图像增强、去噪处理、调整亮度对比度等操作来提高图像质量。
字体样本收集:提供更多有代表性的字体样本用于训练模型,包括不同字体、大小、倾斜度和风格的文本样本。这样能够帮助模型更好地适应不同的字体和书写风格。
模型训练和调优:针对特定的数据集和场景,通过模型训练和调优来提高准确率。使用更大规模的训练数据集,采用更精细的特征工程和模型选择,调整算法参数等方式来提升模型性能。
数据标注和纠错:对于已识别的错误结果,可以进行人工标注和纠正,将正确的标签应用到相应文本上。这种反馈机制可以帮助模型校正错误并提高准确率。
结合后处理技术:应用后处理技术,如校正、纠错和规则引擎等,对识别结果进行进一步处理和优化。例如,使用语言模型检查语法错误或通过规则过滤掉明显不合理的结果。
使用多个OCR引擎:尝试使用多个不同的OCR引擎进行识别,并将它们的结果进行融合。这样可以综合各个引擎的输出,提高整体的准确率。