热门
文字识别OCR长文档信息抽取这个应用类型 上传20张图片训练可以上传 不同模版的pdf吗 ?还是只能用一个模版不同内容?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
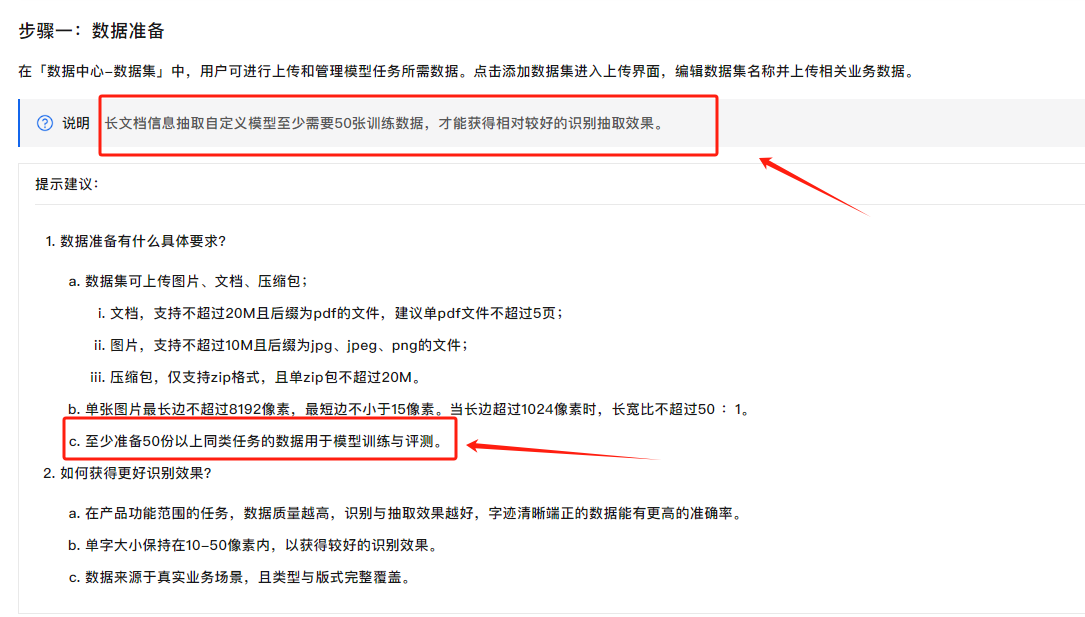
您好,文字识别OCR长文档信息抽取自定义模型至少需要50张训练数据,才能获得相对较好的识别抽取效果。不可以上传不同模版的PDF,需要是同类任务的数据用于模型训练与评测,可以理解为一个模版的不同内容其他内容参考:文档
文字识别技术可以灵活应用于证件文字识别、发票文字识别、文档识别与整理等行业场景,满足认证、鉴权、票据流转审核等业务需求。