
在文字识别ocr中,识别结果返回:预测失败,如何处理啊?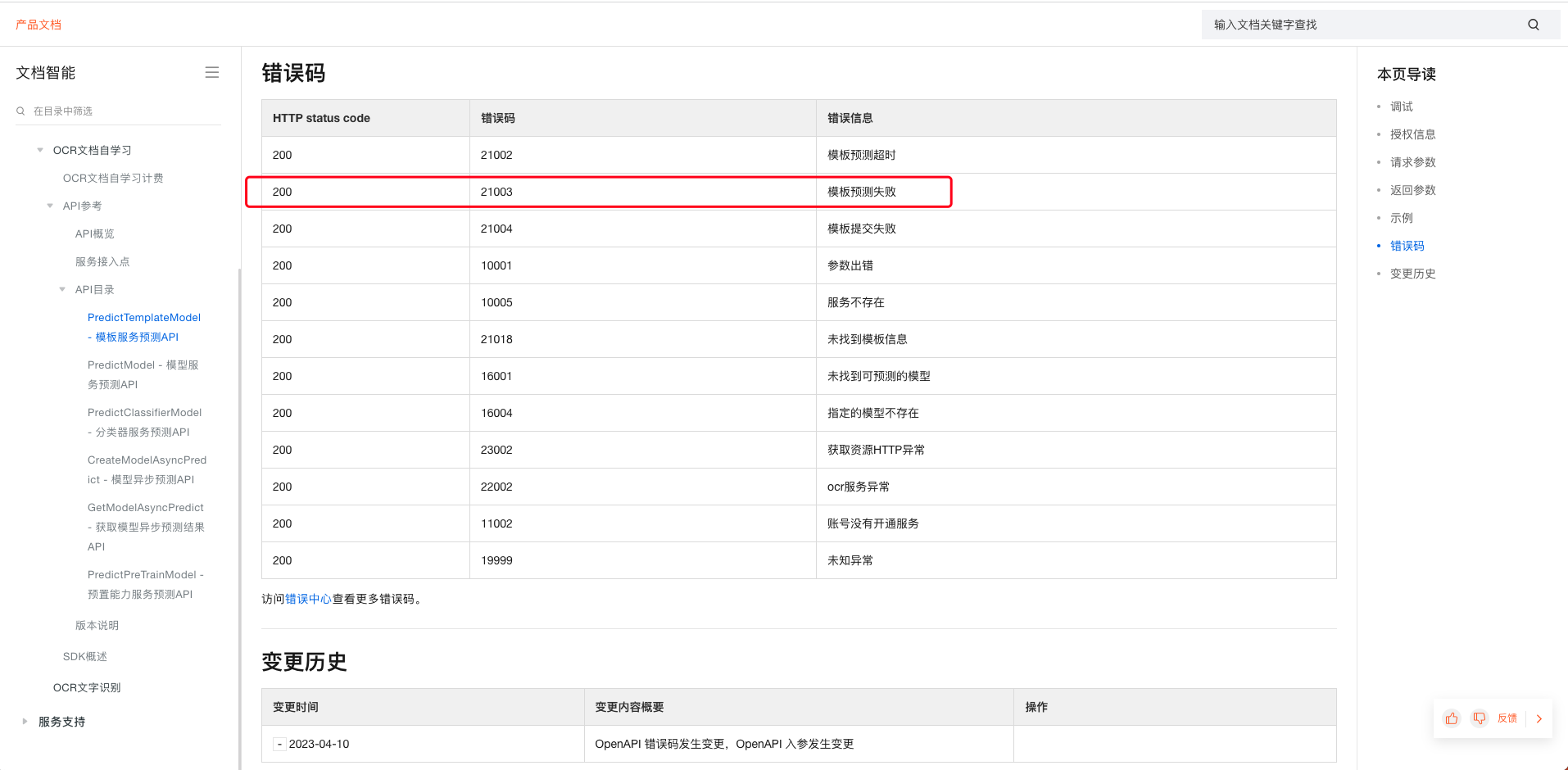 {"headers":{"Date":["Mon, 25 Sep 2023 04:42:44 GMT"],"Content-Type":["application/json;charset=utf-8"],"Content-Length":["229"],"Connection":["keep-alive"],"Keep-Alive":["timeout=25"],"Access-Control-Allow-Origin":[""],"Access-Control-Expose-Headers":[""],"x-acs-request-id":["C4888DC2-8CB9-5E98-A9C0-59600F6DA2B1"],"x-acs-trace-id":["75b98f93e7a8867094841ed26d205946"],"ETag":["2qN9pEnV1Pm6454fzGp6Blg7"]},"statusCode":200,"body":{"code":"21003","data":null,"message":"模板预测失败","requestId":"C4888DC2-8CB9-5E98-A9C0-59600F6DA2
{"headers":{"Date":["Mon, 25 Sep 2023 04:42:44 GMT"],"Content-Type":["application/json;charset=utf-8"],"Content-Length":["229"],"Connection":["keep-alive"],"Keep-Alive":["timeout=25"],"Access-Control-Allow-Origin":[""],"Access-Control-Expose-Headers":[""],"x-acs-request-id":["C4888DC2-8CB9-5E98-A9C0-59600F6DA2B1"],"x-acs-trace-id":["75b98f93e7a8867094841ed26d205946"],"ETag":["2qN9pEnV1Pm6454fzGp6Blg7"]},"statusCode":200,"body":{"code":"21003","data":null,"message":"模板预测失败","requestId":"C4888DC2-8CB9-5E98-A9C0-59600F6DA2
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,看了你的描述,如果阿里云文字识别OCR返回预测失败,你可以考虑尝试一下调整图片清晰度和对比度,使文字更加清晰,或者增加图片分辨率,提高图片质量。
如果是身份证、营业执照等特定类型的证件,可以尝试使用对应的OCR接口进行识别。
还有就是检查图片是否包含非文字内容,如水印、噪点等,可以尝试去除这些干扰因素,顺便再检查API调用参数是否正确,如图片类型、图片大小等。
当OCR识别结果返回"预测失败"时,表示OCR系统无法成功识别您提供的图像或文本。这种情况可能由以下一些因素引起:
图像质量问题:OCR系统对文字识别非常依赖图像的质量。如果图像模糊、光线不足、倾斜等,会导致识别结果不准确甚至无法识别。您可以尝试改善图像质量,如调整光线、纠正图像倾斜等,以提高OCR的成功率。
文字特征问题:OCR系统可能对某些字体、手写体、特殊符号或其他复杂的文本特征识别能力有限。如果您的文本包含这些特殊情况,可能会导致预测失败。在这种情况下,您可以尝试使用具有更强大识别能力的OCR工具,例如专门针对手写体或特定文本特征进行优化的OCR引擎。
缺少训练样本:OCR系统通常是基于机器学习和深度学习技术进行训练的。如果您提供的文本样本在训练数据中较少或没有涵盖到,则OCR系统可能无法准确预测。在这种情况下,可能需要重新训练OCR模型,并增加包含您感兴趣的文本样本。
如果您遇到预测失败的情况,可以尝试以下方法来处理:
改善图像质量:优化图像质量,确保清晰、高对比度且光线充足。可以进行图像预处理操作,如去噪、增强对比度等,以提高OCR识别的准确性。
使用不同的OCR引擎或算法:尝试使用其他OCR服务或工具,可能有不同的识别算法或训练数据,能够更好地适应您的特定需求。
提供更多训练样本:如果您有大量的自定义文本样本,您可以将这些样本添加到训练数据中,重新训练OCR模型以提高识别准确性。
人工干预:在某些特殊情况下,手动校正OCR识别结果可能是一种解决方法。您可以通过人工审查并纠正预测失败的部分,以获得更准确的结果。
当在OCR系统中遇到“预测失败”的情况时,可以尝试以下方法来解决问题:
检查图像质量:确保输入的图片清晰、无模糊或噪声。如果图片质量较差,尝试使用图像增强技术(如锐化、去噪等)来提高图片质量。
调整参数设置:检查模型的参数设置,例如阈值、字体大小范围等,并根据实际需求进行调整。
选择其他模型:尝试使用其他预训练的OCR模型,因为不同的模型可能在不同类型的图片上表现出色。
数据增强:通过对训练数据进行扩充,可以提高模型的泛化能力。可以尝试旋转、翻转、缩放等操作对图片进行变换。
超参数调优:通过调整学习率、批次大小、优化器等超参数,可以优化模型的训练过程,从而提高预测成功率。
增加训练数据:如果可能的话,收集更多的训练数据可以帮助模型更好地学习和泛化。
使用迁移学习:利用预训练的模型作为基础,在此基础上继续训练,可以利用已经学习到的特征,减少训练时间并提高准确率。
错误分析:对于错误的识别结果,进行具体分析,找出问题所在,针对性地进行改进。


