
flink的 streamfilesink 写parquet到hdfs 官网给了例子但是不是很详细 写了之后好像有点问题?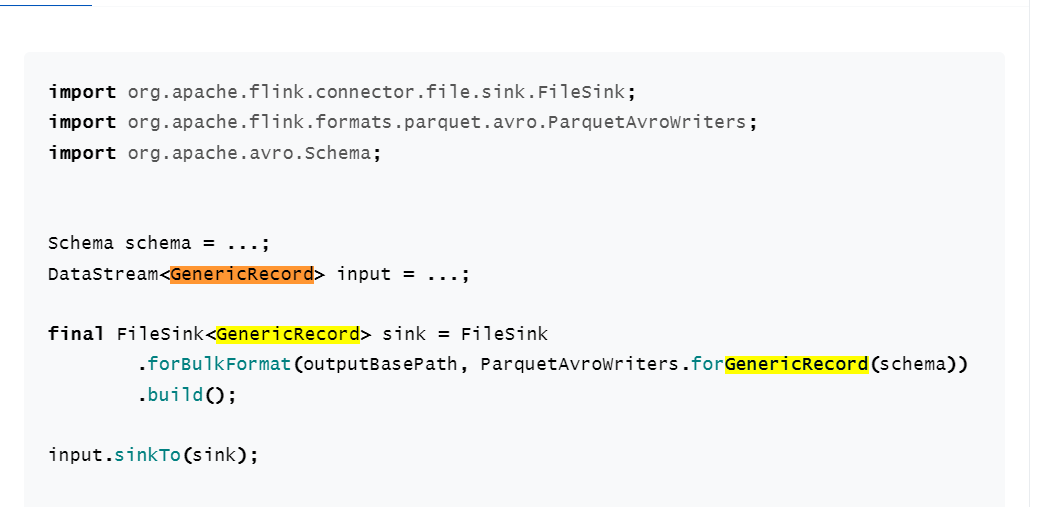
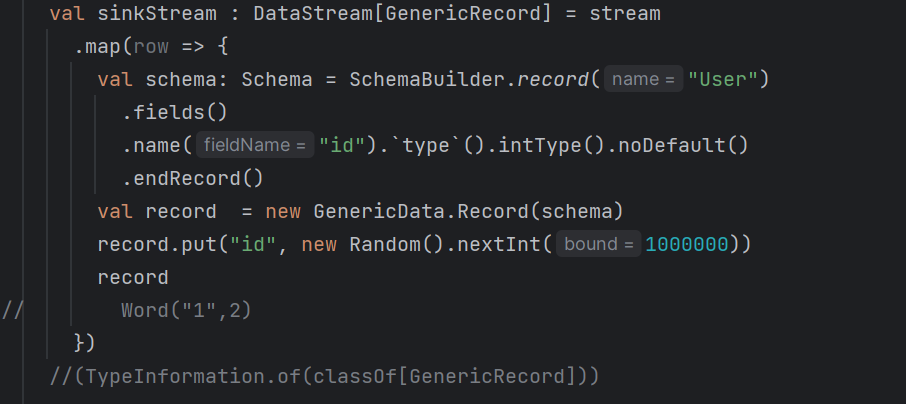

说我这个GenericRecord 没序列化 不知道咋弄
阿里云的社区里说是有bug?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,看了你的描述,问题是出现在序列化对象时发生的。Java.lang.UnsupportedOperationException 是一个继承自 java.io.ObjectStreamException 的异常,用于指示某个 Java 类型不支持序列化。
因为Kryo在反序列化过程中发现某种类型的字段无法被序列化,于是抛出了 UnsupportedOperationExpection。
在处理"KryoException: java.lang.UnsupportedOperationException"这个异常时,我们首先需要了解该异常的原因以及如何解决它。该异常通常在使用Kryo序列化库时出现,表示对象的某些属性不支持序列化操作。
下面是处理"KryoException: java.lang.UnsupportedOperationException"异常的一般步骤。我们将使用表格来展示这些步骤。
确定异常的根本原因
首先,我们需要确定异常的根本原因。在这种情况下,"KryoException: java.lang.UnsupportedOperationException"异常表示某些对象属性不支持序列化操作。因此,我们需要检查导致该异常的代码段。
检查导致异常的代码段
查找并检查导致异常的代码段。通常,该异常会在进行Kryo序列化操作时抛出。因此,我们需要找到涉及到Kryo序列化的代码段。
确认是否有属性不支持序列化
在找到涉及到Kryo序列化的代码段后,我们需要确认是否有属性不支持序列化。通常,这个信息会在异常堆栈跟踪中给出。
执行相应的解决方案
一旦我们确认了不支持序列化的属性,我们需要执行相应的解决方案。以下是一些可能的解决方案:
忽略不支持序列化的属性:如果不支持序列化的属性对于应用程序的正确执行不是必需的,我们可以在序列化过程中忽略它们。这可以通过使用transient关键字修饰属性来实现,该关键字告诉序列化机制忽略该属性。
private transient String unsupportedProperty;
自定义序列化:如果我们需要序列化不支持序列化的属性,我们可以自定义序列化过程。这可以通过实现Serializable接口并提供自定义的writeObject和readObject方法来实现。
private void writeObject(java.io.ObjectOutputStream out) throws IOException {
// 自定义序列化逻辑
}
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException {
// 自定义反序列化逻辑
}
——参考链接。
看起来您遇到了一个问题,其中包含以下日志消息:
[INFO] com.esotericsoftware.kryo.KryoException: java.lang.UnsupportedOperationException Serialization trace:
reserved (org.apache.avro.Schema$Field)
fieldMap (org.apache.avro.Schema$RecordSchema)
schema (org.apache.avro.generic.GenericData$Record)
这些日志表明您的应用程序正在尝试序列化 Avro 数据类型,但某些字段没有实现所需的操作。
Avro 是一种数据交换格式,用于跨语言平台传输结构化数据。Kryo 是 Apache Flink 中使用的默认 Java 对象字节码库之一,负责对象的序列化和反序列化过程。根据提供的日志条目,com.esotericsoftware.kryo.KryoException 异常是由于 java.lang.UnsupportedOperationException 被抛出而引发的。这意味着 Kryo 在试图序列化某个特定的对象时失败了,因为它发现了一些未实现的方法。为了解决此问题,您可以考虑以下几个选项:
fieldMap) 是否正确配置。确保所有必需的字段都存在并且被正确地标记为可序列化的。streamingExecutionEnvironment.getConfig().setCustomClassLoader(new CustomClassLoadingStrategy());
您好,我很高兴回答您的问题。根据您提供的错误堆栈信息,问题是出现在序列化对象时发生的。Java.lang.UnsupportedOperationException 是一个继承自 java.io.ObjectStreamException 的异常,用于指示某个 Java 类型不支持序列化。
在您的案例中,该异常发生于 com.esotericsoftware.kryo.KryoException 中,而 Kryo 是一个高性能的 Java 反序列化/序列化框架。Kryo 在反序列化过程中发现某种类型的字段无法被序列化,于是抛出了 UnsupportedOperationExpection。
根据 StackOverflow 上的链接 Unsupported Operation Exception in kryo,这种情况可能是由以下几种原因造成的:
使用了内部类的对象,因为 Kryo 默认不支持序列化此类对象;
尝试序列化不可变对象,但 Kryo 并不知道如何处理它们;
尝试序列化 final 或者 static 成员变量;
尝试序列化数组元素,而不是直接序列化数组;
尝试序列化 null 字段。
鉴于以上原因,您可以按照以下方式尝试优化您的代码:
检查是否存在内部类的对象,如果是的话,尽量避免使用内部类,或者手动实现序列化接口;
尽量不要使用 final 或 static 成员变量,改用普通成员变量;
将数组改为 List 或 Map,让 Kryo 能够更好地理解数组结构;
如果必须序列化 null 字段,可以通过设置 Kryo 的 ignoreMissingField 属性为 true 来忽略空值。
从您的问题描述来看,您可能在尝试使用Flink的StreamFileSink将数据写入HDFS时遇到了问题。问题可能是由于序列化/反序列化过程中的数据类型不匹配导致的。
我建议您检查以下几点:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


