
Flink数据从kettle迁移到Mysql有什么比较好的方案吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink 数据从 Kettle 迁移到 MySQL 是一个相对复杂的过程,因为涉及到数据转换和流处理。以下是一些建议的步骤和方案,以帮助你更顺利地完成迁移:
1.数据转换工具:
2.数据清洗:
3.流处理:
4.增量迁移:
5.测试:
6.监控和日志:
7.优化性能:
将Flink数据从Kettle迁移到MySQL,你可以考虑以下方案:
使用Flink的JDBC Connector:Flink提供了JDBC Connector,可以直接将Flink中的数据写入到MySQL数据库中。你需要定义一个JDBC Sink,然后将其连接到你的Flink数据流上。这个Sink会负责将数据写入到MySQL数据库中。
使用Kettle进行数据迁移:虽然你提到了从Kettle迁移数据,但Kettle本身也是一个强大的ETL工具,它支持多种数据源和目标数据库,包括MySQL。你可以在Kettle中定义一个转换任务,将Flink数据作为输入,然后将其写入到MySQL数据库中。
使用中间存储:如果数据量非常大,直接迁移可能会有性能问题。你可以考虑先将数据写入到一个中间存储(如HDFS、Kafka等),然后再从这个中间存储迁移到MySQL。这种方法可以利用中间存储的分布式处理能力,提高数据迁移的效率。
编写自定义程序:如果以上方法都不能满足你的需求,你也可以考虑编写一个自定义的程序来进行数据迁移。这个程序可以读取Flink数据,然后将其写入到MySQL数据库中。你可以使用Java、Python等语言来编写这个程序。
在进行数据迁移时,还需要注意以下几点:
数据一致性:确保在数据迁移过程中,数据的一致性得到保证。这可能需要使用事务、分布式锁等技术。
性能优化:如果数据量非常大,需要考虑性能优化。可以使用批量插入、并行处理等技术来提高数据迁移的效率。
错误处理:在数据迁移过程中,可能会遇到各种错误。需要有一个完善的错误处理机制,能够处理这些错误,并保证数据迁移的顺利进行。
数据验证:在数据迁移完成后,需要进行数据验证,确保数据的准确性和完整性。
Flink 数据从 Kettle 迁移到 MySQL,可以考虑以下几种方案:
1、使用 Flink SQL:
如果你的数据已经从 Kettle 转换成了 Flink,你可以使用 Flink SQL 来查询和转换数据。
创建一个 Flink SQL 客户端,连接到 Flink 集群,并执行 SQL 查询来读取数据、转换数据,并将结果写入 MySQL 数据库。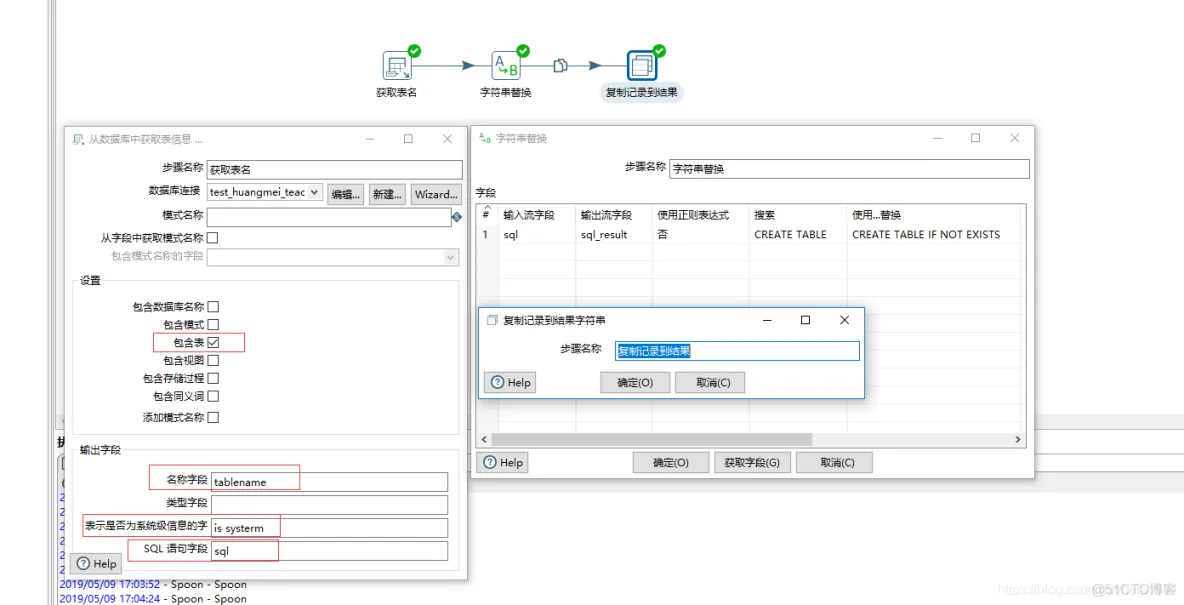
2、使用 Java/Scala 代码:
如果你熟悉 Java 或 Scala,可以使用 Flink 的 DataStream 或 DataSet API 来读取 Kettle 中的数据,进行必要的转换,然后将结果写入 MySQL。
利用 Flink 的 Table API 和 SQL API 进行数据转换和查询。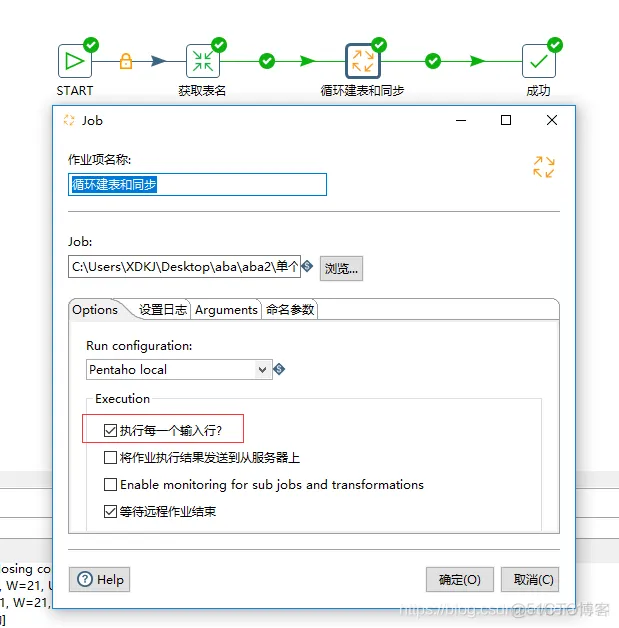
3、自定义脚本:
根据你的具体需求和数据格式,你可以编写自定义的脚本或程序来读取 Kettle 中的数据,将其转换为 MySQL 支持的格式,并写入 MySQL 数据库。
数据导出/导入:
将 Kettle 中的数据导出为文件(如 CSV、JSON 等),然后使用 MySQL 的导入工具(如 LOAD DATA INFILE)将文件导入到 MySQL 数据库中。
4、考虑性能和效率:
在迁移过程中,确保考虑到性能和效率的因素。根据你的数据量和业务需求,选择适当的方案和技术,以确保数据迁移的顺利进行。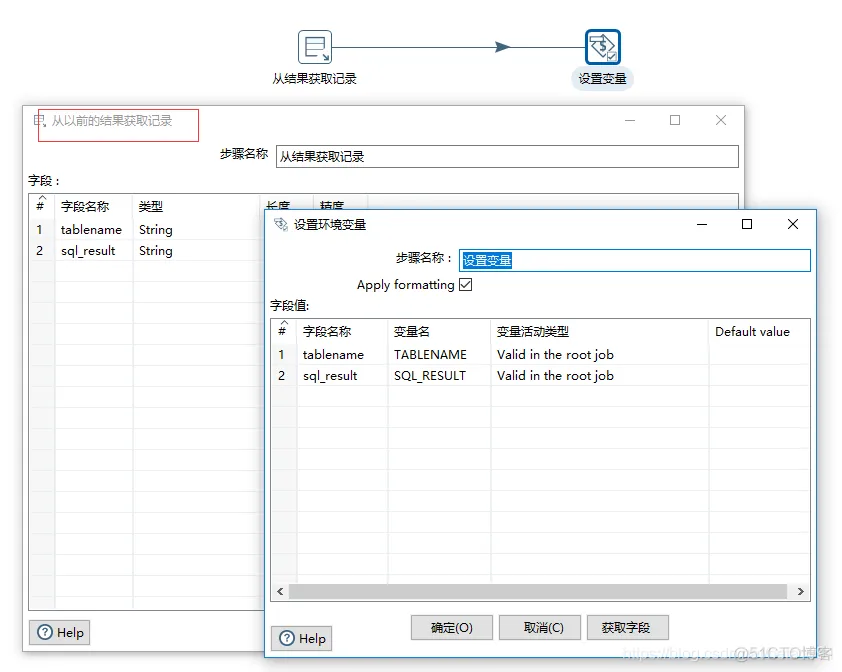
Kettle 是一款国外开源的 ETL 工具,纯 Java 编写,绿色无需安装,数据抽取高效稳定 (数据迁移工具)。Kettle 中有两种脚本文件,transformation 和 job,transformation 完成针对数据的基础转换,job 则完成整个工作流的控制。
Flink数据从kettle迁移到Mysql可以按照以下思路:
读取数据库中表->创建表->表数据抽取
整个抽取过程包括一个job和两个trans。
1、首先是数据库的表名抽取trans:作用是读取数据库的表名并以此记录。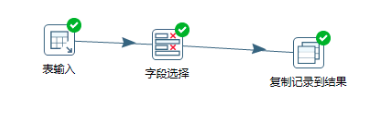
2、表名称传给变量
3、获取对应的表结构
4、表数据抽取
然后运行查看。得到对应的表和数据。
——参考链接。
将Flink数据从Kettle迁移到MySQL,可以采取以下步骤:
数据源分析:首先,你需要理解Kettle和MySQL的数据结构以及数据之间的映射关系。这包括表结构、字段类型、主键、外键、索引等。
数据迁移计划:根据数据源分析的结果,制定一个详细的数据迁移计划。这包括数据迁移的时间、人员、资源、风险评估和应对策略等。
数据迁移工具选择:根据数据迁移计划,选择适合的工具进行数据迁移。你可以选择使用开源工具,如Apache Sqoop,或者商业工具,如DataGrip等。
数据迁移实施:按照数据迁移计划,使用所选的工具进行数据迁移。在迁移过程中,要确保数据的完整性和准确性,对可能出现的问题进行预判和处理。
数据验证:数据迁移完成后,需要对数据进行验证,确保数据的完整性和准确性。可以使用查询语句或编写脚本进行数据验证。
反馈与调整:如果在数据验证过程中发现问题,需要回到迁移计划阶段进行反馈和调整,重新进行数据迁移。
以上是一个大致的方案,具体实施时可以根据实际情况进行调整。
从Kettle迁移数据到MySQL,可以通过以下几种方案:
需要注意的是,以上方案都可能需要根据具体的数据格式和转换规则进行调整。另外,对于大批量数据的迁移,你可能需要考虑数据的分片和分批处理,以避免一次性加载大量数据导致的问题。
另外,为了确保数据的一致性和完整性,你可能需要在迁移过程中进行一些数据校验和错误处理。例如,你可以在迁移过程中定期检查MySQL数据库中的数据是否与Kettle中的数据一致,如果不一致,可以尝试回滚或者重新迁移数据。
最后,对于敏感数据的处理,你可能需要考虑数据脱敏或者加密。例如,你可以在将敏感数据写入MySQL之前,将其替换为一些固定的或者随机化的值。这样可以保护敏感数据的安全性。
使用Flink进行Kettle到MySQL的数据迁移可以采取以下方案:
定义数据流源和目标:
确定Kettle和MySQL在Flink中的数据流源和目标格式。Kettle可以作为数据源,提供数据给Flink,而MySQL可以作为目标,接收Flink处理后的数据。
创建Flink数据流:
使用Flink的DataStream API创建一个数据流,该数据流从Kettle获取数据。确保将数据从Kettle的输出格式转换为Flink可以处理的格式。
数据处理:
根据需要对数据进行转换、过滤、聚合等操作。可以使用Flink提供的各种算子和函数来完成这些操作。
数据写入MySQL:
将处理后的数据写入MySQL数据库。可以使用Flink提供的JDBC连接器或自定义的Sink来实现数据写入。确保将数据正确地写入MySQL的目标表中。
配置和优化:
根据实际情况对Flink作业进行配置和优化,例如调整并行度、缓冲区大小等参数,以提高数据迁移的效率和准确性。
监控和调试:
在迁移过程中实时监控Flink作业的状态和性能,并进行必要的调试和优化。可以使用Flink提供的Web UI或其他监控工具来完成这一步骤。
测试和验证:
在实际迁移之前,对Flink作业进行充分的测试和验证,确保数据的准确性和完整性。可以使用Kettle或其他工具进行数据校验和比较。
部署和运行:
将Flink作业部署到生产环境中,并确保它可以稳定地运行并完成数据迁移任务。根据需要调整和维护作业以确保其性能和可靠性。
Apache Flink 并不是一个ETL工具,但作为一个强大的流处理框架,它可以用来实现实时数据迁移和处理。要将数据从 kettle 迁移到 MySQL,可以采取以下步骤:
使用Kettle抽取数据:
将数据发送到中间存储:
使用Flink进行实时迁移:
示例代码片段(Java API):
// 创建Flink环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从Kafka读取数据(假设已经将Kettle转换的数据发送到了Kafka)
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", "localhost:9092");
DataStream<String> input = env.addSource(new FlinkKafkaConsumer<>("input-topic", new SimpleStringSchema(), kafkaProps));
// 解析数据并转换为Flink的Row类型,这里假设解析为(String, Integer)
DataStream<Row> parsedData = input.map(...);
// 将数据写入MySQL
Properties dbProps = new Properties();
dbProps.setProperty("driver.name", "com.mysql.cj.jdbc.Driver");
dbProps.setProperty("username", "mysql_user");
dbProps.setProperty("password", "mysql_password");
dbProps.setProperty("database-url", "jdbc:mysql://localhost:3306/mydatabase");
JdbcSink.sink(
"INSERT INTO my_table (column1, column2) VALUES (?, ?)",
new JdbcStatementBuilder<Row>() {
@Override
public void configure(int i, PreparedStatement ps) throws SQLException {
// 设置PreparedStatement的索引和参数
ps.setString(1, row.getField(0).toString());
ps.setInt(2, row.getField(1).hashCode());
}
},
dbProps
).accept(parsedData);
// 执行Flink作业
env.execute("Flink Streaming Job from Kettle to MySQL");
对于SQL Client,可以编写SQL DDL创建一个表源和一个JDBC sink:
CREATE TABLE kafka_source (
...
) WITH (
'connector' = 'kafka',
'topic' = 'input-topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json' -- 根据实际数据格式选择
);
CREATE TABLE mysql_sink (
column1 STRING,
column2 INT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'my_table',
'username' = 'mysql_user',
'password' = 'mysql_password'
);
-- 将数据从kafka源表迁移到mysql sink表
INSERT INTO mysql_sink
SELECT * FROM kafka_source;
然后提交这个SQL作业到Flink集群运行。
虽然Flink并不是直接与Kettle集成,但通过合理的数据管道搭建,可以将Kettle处理过的数据通过Flink高效地迁移到MySQL中。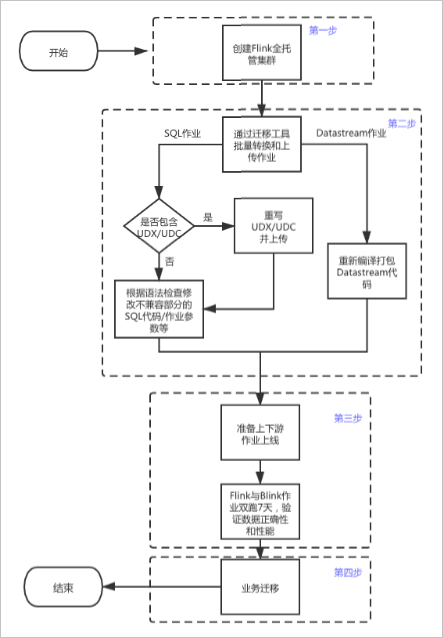
迁移Kettle数据到MySQL的最佳实践涉及两个主要阶段:数据抽取和数据加载。以下是实现这两个阶段的一些基本步骤:
第一阶段:数据抽取
创建ETL转换:在Kettle中创建一个ETL转换,其中包含一系列工具,如读取CSV文件、过滤数据、排序、合并等,以便清理原始数据。
导出数据:将清洗后的数据导出成CSV格式,便于后续导入MySQL。
备份现有数据库:为了避免意外覆盖现有的MySQL数据,先备份好原数据库。
创建空的目标数据库:在MySQL中创建一个新的数据库,用于存放从Kettle导出的数据。
插入测试数据:在目标数据库中手动插入几条示例数据,以确保一切都在预期范围内运作良好。
第二阶段:数据加载
创建ETL转换:现在切换回Kettle, 使用Kettle的Data Integration (DI) Studio 来建立一个ETL转换,这次的目的将是把之前导出的CSV文件载入到MySQL中。
添加数据装载工具:在DI Studio中加入适当的工具,如File Text Reader、Database Connection、Insert Data Into Table等,分别负责读取CSV文件、连接到MySQL数据库及将数据插入到目标表中。
映射字段:确保每个CSV文件中的字段都能正确映射到MySQL表格中的相应字段。
预览和校验:在正式运行前,务必预览一遍ETL转换的结果,确保数据按预期方式进行了整理和加载。
运行ETL转换:最后,运行ETL转换,让Kettle将CSV文件中的数据加载到MySQL数据库中。
具体操作见:https://blog.csdn.net/zzz37zhh/article/details/129959424。
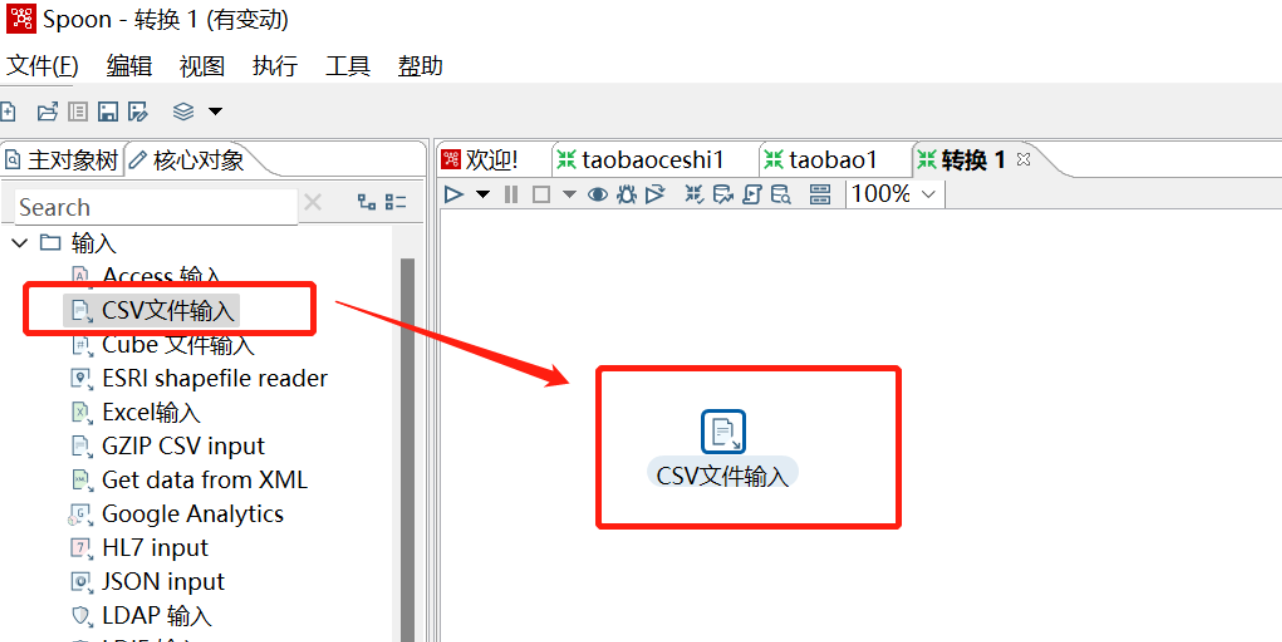

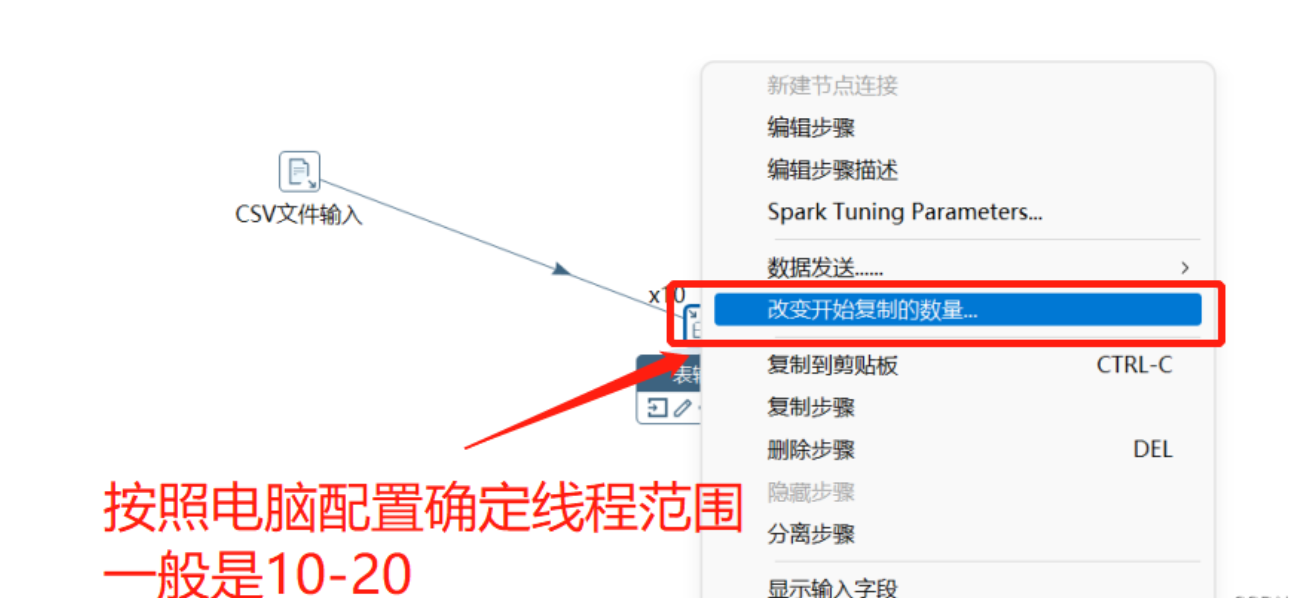
要在Flink中将从Kettle迁移到Mysql,可以采用以下步骤:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


