
我的需求是识别非结构化的法律文书,提取里面的结构化数据,这种是不是就用文字识别OCR长文档信息抽取模型?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,是的,阿里云的文字识别OCR长文档信息抽取模型可以用于识别非结构化的法律文书,并从中提取结构化数据。该模型能够自动识别文档中的表格、列表、标题、段落等结构化信息,并将其转化为结构化数据进行输出。这样可以大大提高文档处理效率,减少人工处理的时间和成本。
您好,文字识别OCR长文档信息抽取主要用于实现对非结构化、多版式的文档的高精度抽取,您可以用长文档信息抽取模型来抽取非结构化数据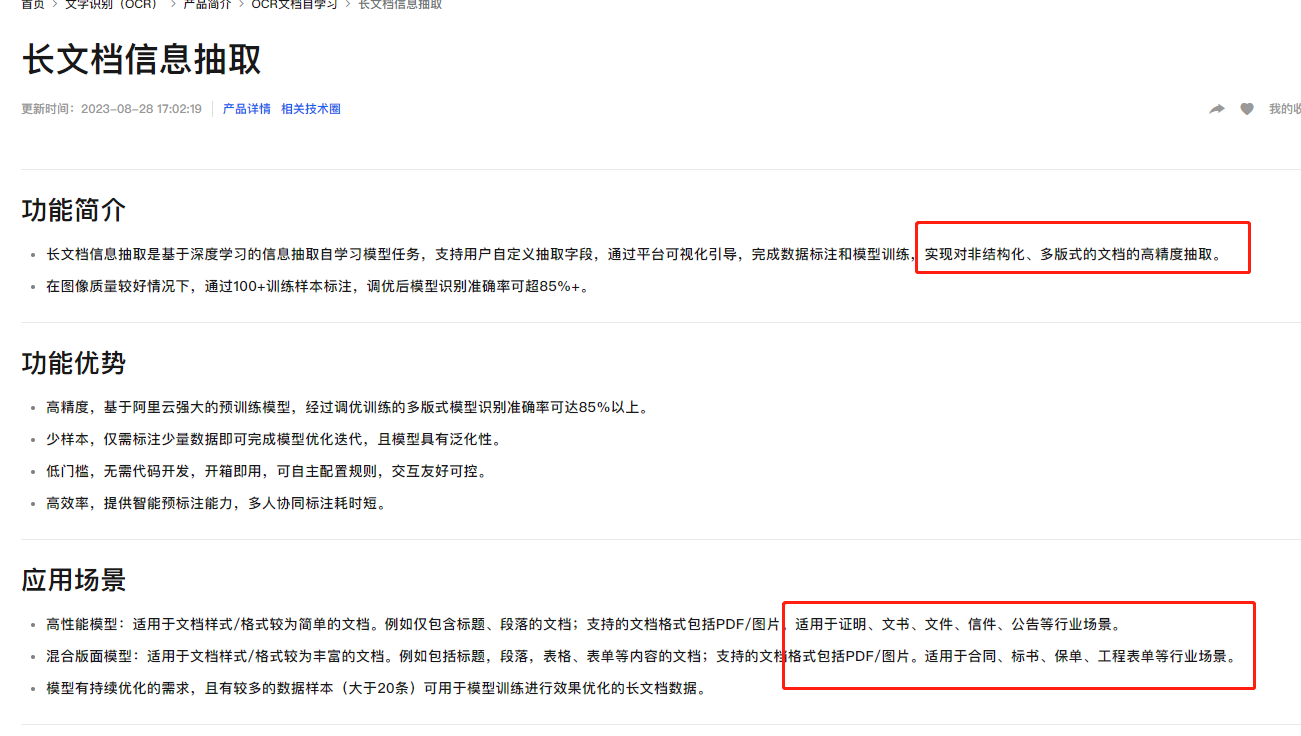
是的,对于识别非结构化的法律文书并提取其中的结构化数据,可以使用文字识别OCR和长文档信息抽取模型相结合的方法。

首先,使用文字识别OCR技术将法律文书中的图像或扫描文本转换为可编辑和可搜索的文本。OCR技术可以帮助提取整个文档的文字内容,包括标题、段落、表格等。
然后,使用长文档信息抽取模型对OCR识别结果进行处理和分析,以提取所需的结构化数据。长文档信息抽取模型通常使用自然语言处理(NLP)和机器学习技术,可以帮助识别和提取特定模式、关键词、实体等信息。
具体的步骤可能包括:
文字识别OCR:将法律文书图像或扫描文本应用文字识别OCR模型,将其转换为可编辑和可搜索的文本形式。
预处理和分段:根据文档结构特点,对OCR输出的文本进行预处理和分段操作。这可以帮助将文档划分为段落、章节等部分,以便后续处理。
长文档信息抽取模型:使用长文档信息抽取模型,例如序列标注模型、实体识别模型、关系抽取模型等,对文本进行分析和抽取。这可以帮助识别并标注出特定的结构化信息,如法律条款、案件号、当事人信息等。
后处理和整合:根据具体需求,对抽取结果进行后处理和整合。这可能包括去除噪声、纠正错误、规范化数据格式等操作,以确保提取出的结构化数据的准确性和一致性。


