
各位老师 谁有flinkcdc 到gaussdb的实践案例?有相关连接器吗
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是的,有一些使用Flink CDC和GaussDB的实践案例。Flink CDC可以用于从源(如Oracle、MySQL等)实时采集数据,并将其同步到目标数据库(如GaussDB)中。Flink CDC可以使用GaussDB的JDBC连接器来连接到GaussDB,并将数据同步到GaussDB中。
以下是一些使用Flink CDC和GaussDB的实践案例:
实时数据同步:使用Flink CDC和GaussDB来实现实时数据同步,以实现实时数据分析和处理。
数据迁移:使用Flink CDC和GaussDB来实现数据迁移,以将数据从源数据库迁移到目标数据库中。
数据集成:使用Flink CDC和GaussDB来实现数据集成,以将数据从多个源数据库集成到目标数据库中。
在使用Flink CDC和GaussDB时,您可以使用GaussDB的JDBC连接器来连接到GaussDB,并使用Flink CDC的JDBC驱动程序来连接到源数据库。您还可以使用Flink CDC的GaussDB插件来简化数据同步过程。
请注意,使用Flink CDC和GaussDB进行数据同步可能会影响数据同步的性能。如果您的数据集非常大,则可能需要考虑使用其他数据同步工具或方法来实现数据同步。
Flink CDC(Change Data Capture)是一种用于捕获和传递数据库变更的技术。GaussDB是一个支持分布式关系型数据库的产品。
以下是将Flink CDC与GaussDB集成的实践案例和相关连接器信息:
在实际应用中,可以使用Flink CDC捕获GaussDB数据库的变更,并将变更数据传递给其他系统进行进一步处理或分析。例如,可以将GaussDB中的数据变更实时传输到数据仓库或数据湖进行分析。
另外,您可以通过以下步骤实现将Flink CDC数据写入GaussDB的实践:
使用Flink CDC捕获数据库的变更数据,可以使用Debezium等开源CDC工具,或者自行编写Flink CDC程序。
将CDC数据写入Kafka或者其他消息队列中,可以使用Flink的Kafka Connector或者自行编写数据写入逻辑。
使用Flink消费Kafka中的CDC数据,可以使用Flink的Kafka Connector进行数据消费。
将消费到的CDC数据格式化为适合GaussDB的数据格式,可以使用Flink的Map或者FlatMap函数进行数据转换。
使用GaussDB的JDBC连接器将转换后的数据写入GaussDB。
这个实践案例中并没有直接的Flink CDC到GaussDB的连接器,而是通过中间件(如Kafka)进行数据传输和转换。
相关连接器信息:
Flink CDC提供了多个连接器来与不同类型的数据库进行集成,包括GaussDB。你可以通过以下方式获取相关连接器信息:
官方文档:查阅Flink CDC官方文档,其中包含有关各种连接器的详细信息和示例代码。https://help.aliyun.com/zh/flink/developer-reference/supported-connectors?spm=a2c4g.11186623.0.0.153e5d1f6ueWqb#b6bb4bd12a05k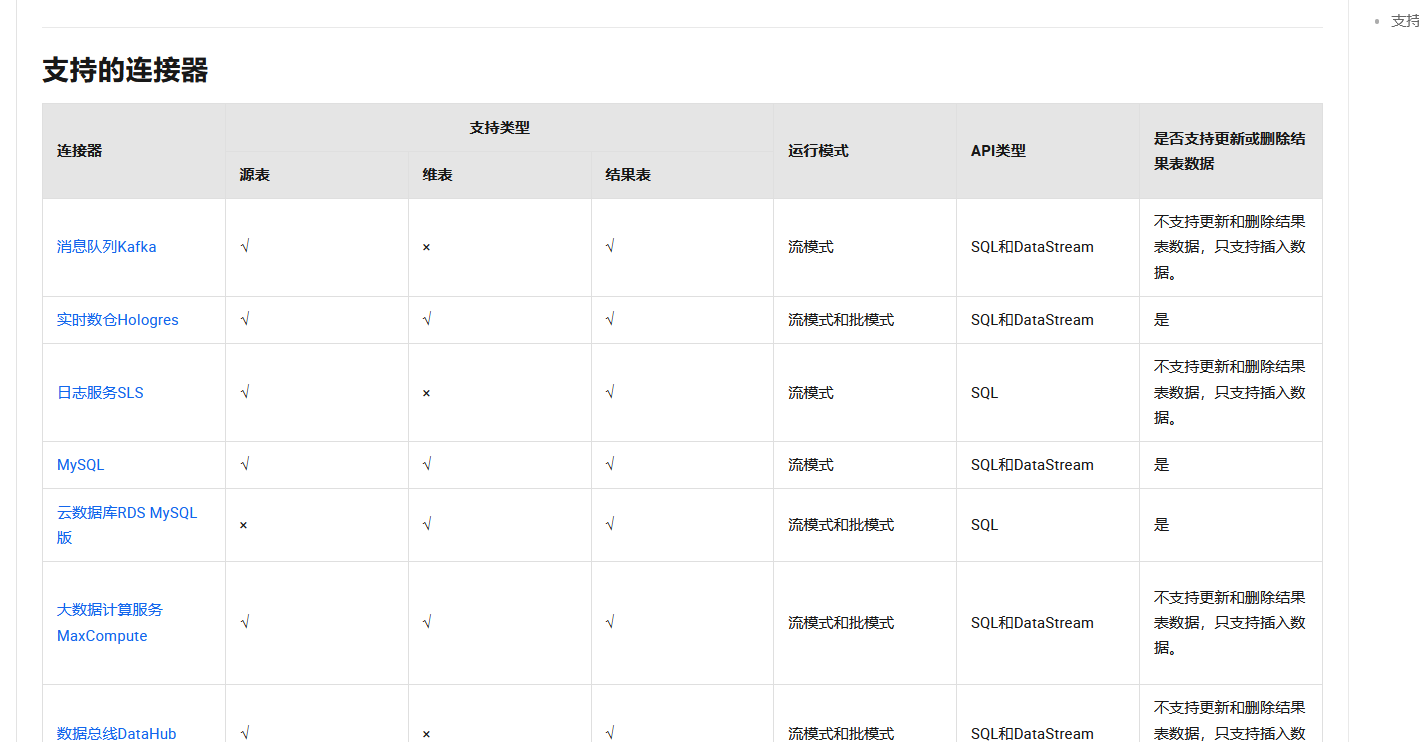
目前Flink CDC没有单独针对GaussDB的连接器。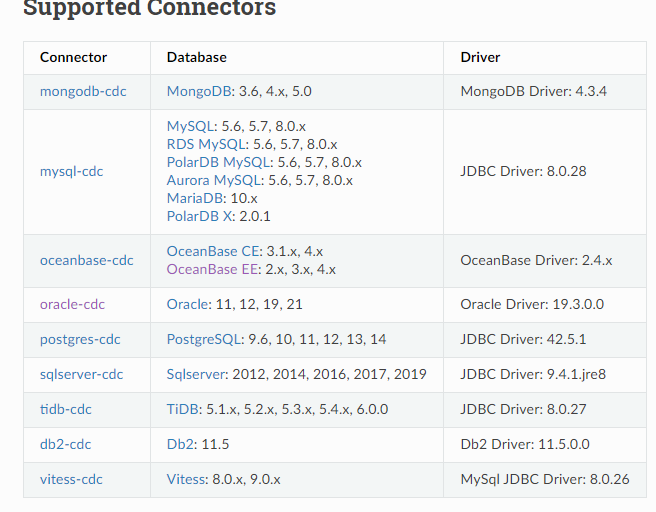
GaussDB数据库它是基于PostgreSQL9.2开发的,在性能、安全、可用性和可维护性上做了增加。主要适用于对数据的插入、删除和查询为主,更新的频率较低。
可以尝试使用postgres-cdc来进行实践。
-- register a PostgreSQL table 'shipments' in Flink SQL
CREATE TABLE shipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN
) WITH (
'connector' = 'postgres-cdc',
'hostname' = 'localhost',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments',
'slot.name' = 'flink',
-- experimental feature: incremental snapshot (default off)
'scan.incremental.snapshot.enabled' = 'true'
);
-- read snapshot and binlogs from shipments table
SELECT * FROM shipments;
楼主你好,阿里云Flink CDC是一种用于实时数据抓取的开源流式数据同步工具,它可以在数据源变化时实时将变化的数据同步到目标数据库中,而GaussDB是华为推出的一种高性能、高可靠性的分布式关系型数据库。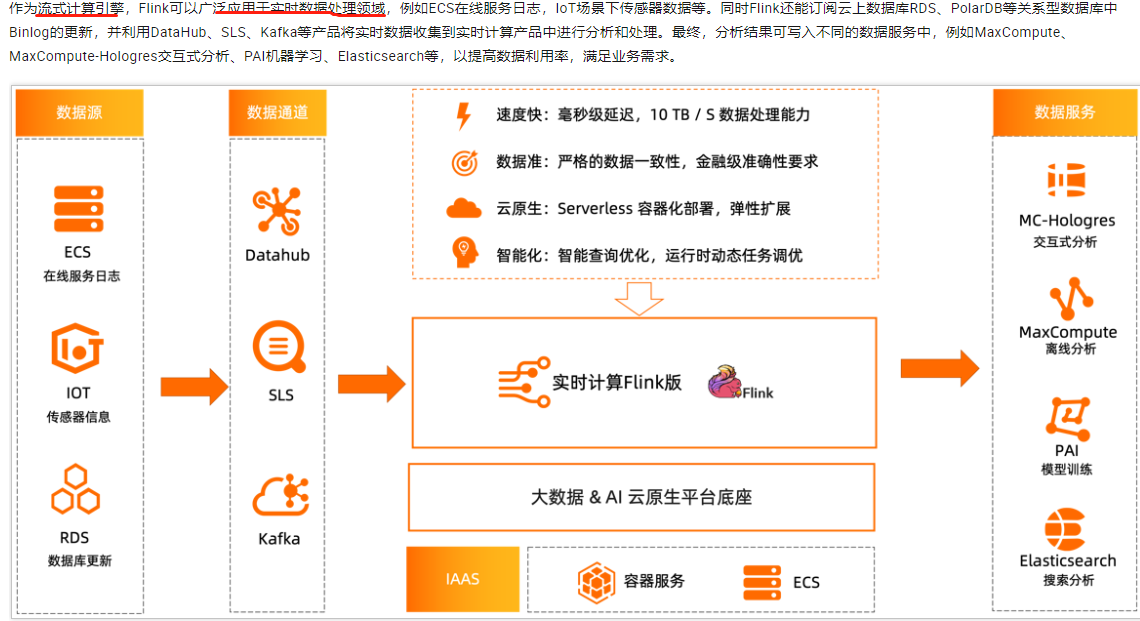
目前阿里云Flink CDC与GaussDB之间还没有官方支持的连接器,但可以通过自定义编写Flink连接器的方式实现数据同步。
具体实现步骤如下:
在Flink中编写自定义的GaussDB连接器,实现数据写入GaussDB的功能。可以参考Flink官方文档中对于自定义连接器的介绍和示例。
在Flink CDC中配置数据源和目标数据存储位置,并使用自定义的GaussDB连接器将数据同步到GaussDB中。
针对不同的数据变化情况,编写对应的触发器和处理程序,保证数据同步的及时性和正确性。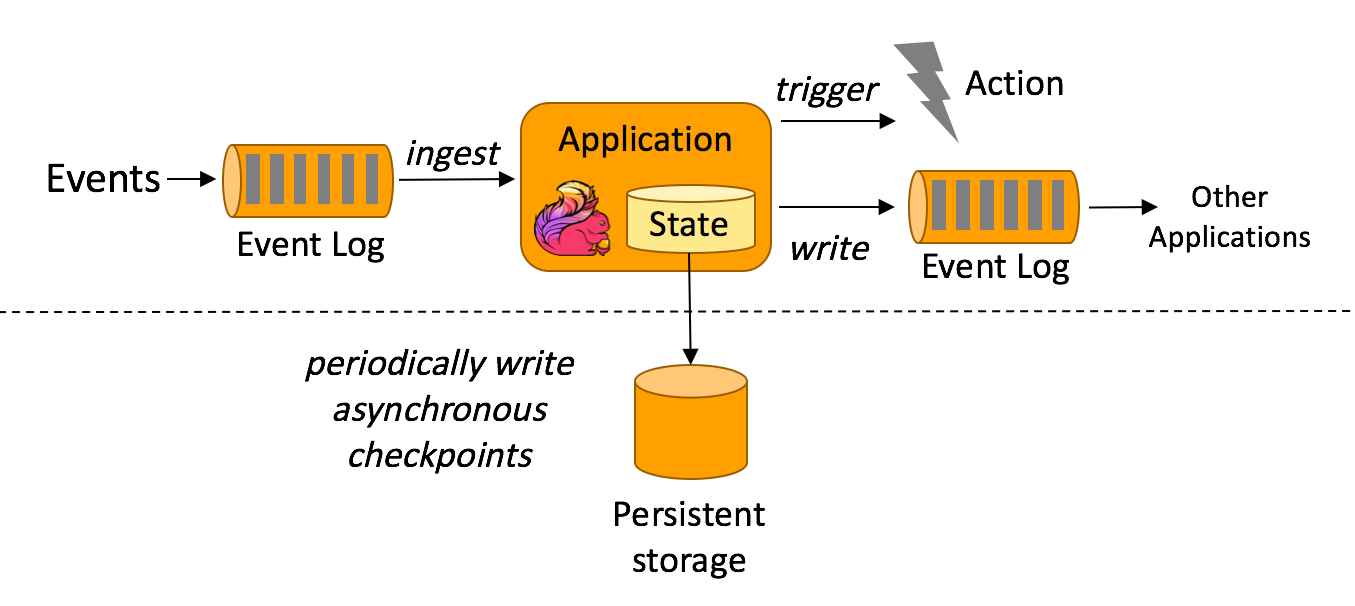
需要注意的是,自定义连接器的实现过程中需要了解GaussDB的数据结构和API接口,以便能够准确地将数据写入GaussDB中。同时还需要考虑连接器的可靠性和性能问题,确保数据同步过程的稳定性和效率。具体可以参考这个文档下的内容:
作为流式计算引擎,Flink可以广泛应用于实时数据处理领域,例如ECS在线服务日志,IoT场景下传感器数据等。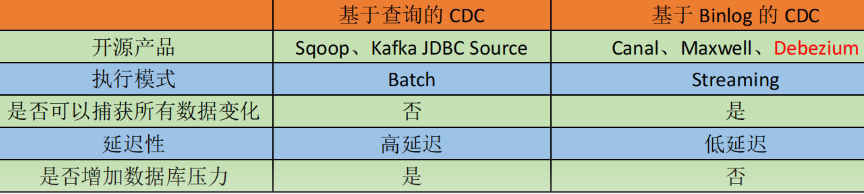
同时Flink还能订阅云上数据库RDS、PolarDB等关系型数据库中Binlog的更新,并利用DataHub、SLS、Kafka等产品将实时数据收集到实时计算产品中进行分析和处理。最终,分析结果可写入不同的数据服务中,例如MaxCompute、MaxCompute-Hologres交互式分析、PAI机器学习、Elasticsearch等,以提高数据利用率,满足业务需求。查看相关文档学习:https://help.aliyun.com/zh/flink/product-overview/scenarios?spm=a2c4g.11186623.0.0.398a1111vZNeiw#concept-62447-zh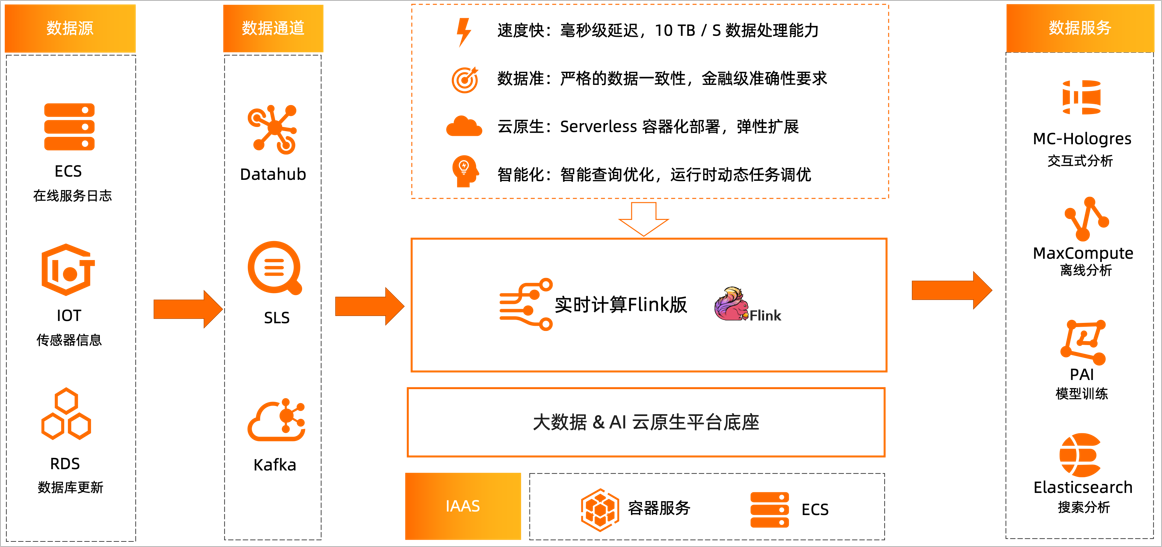
如果您希望简化整个数据同步过程,并减少手动编写代码的工作量,可以考虑使用其他中间件或工具来实现 Flink CDC 到 GaussDB 的集成。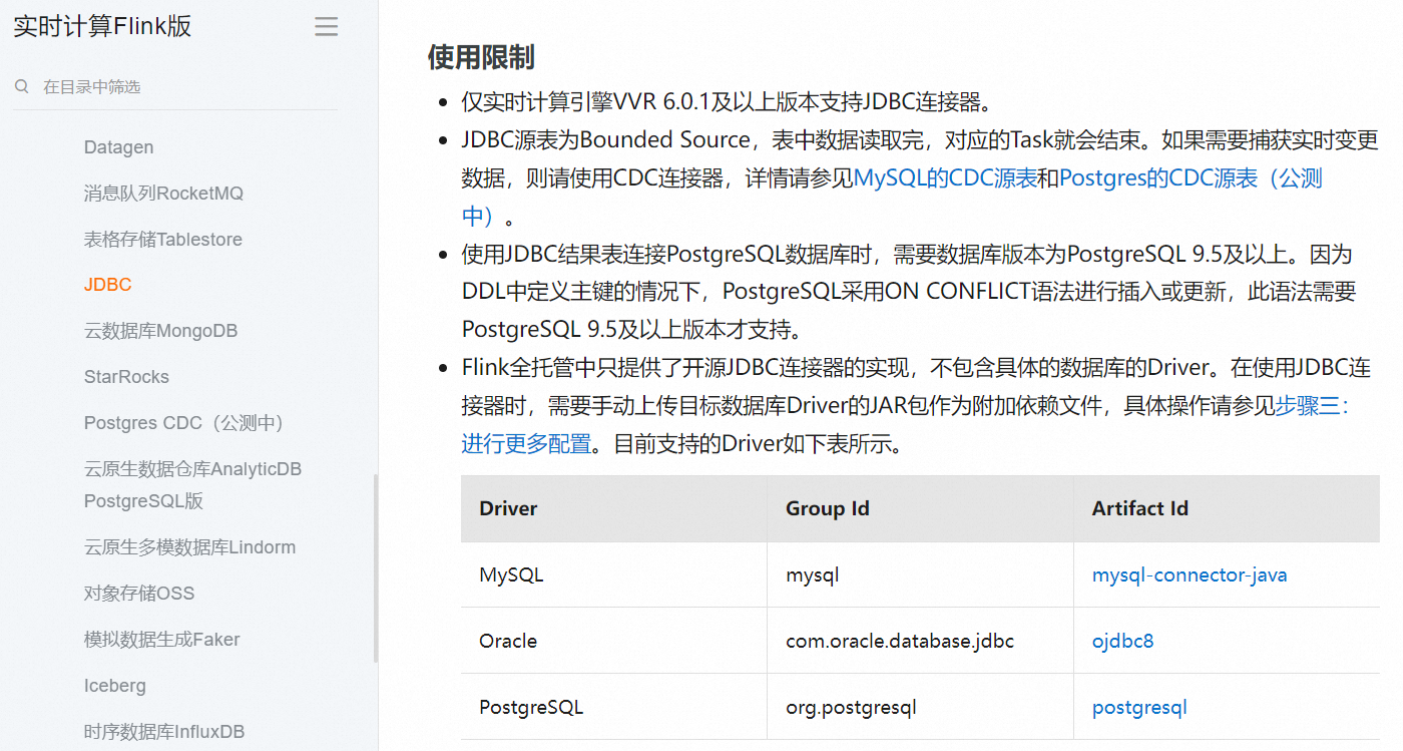
目前没有直接将Flink CDC连接到GaussDB的实践案例或官方提供的连接器。然而,你可以通过使用JDBC连接器来实现Flink CDC与GaussDB之间的数据同步。
以下是一个可能的实现步骤:
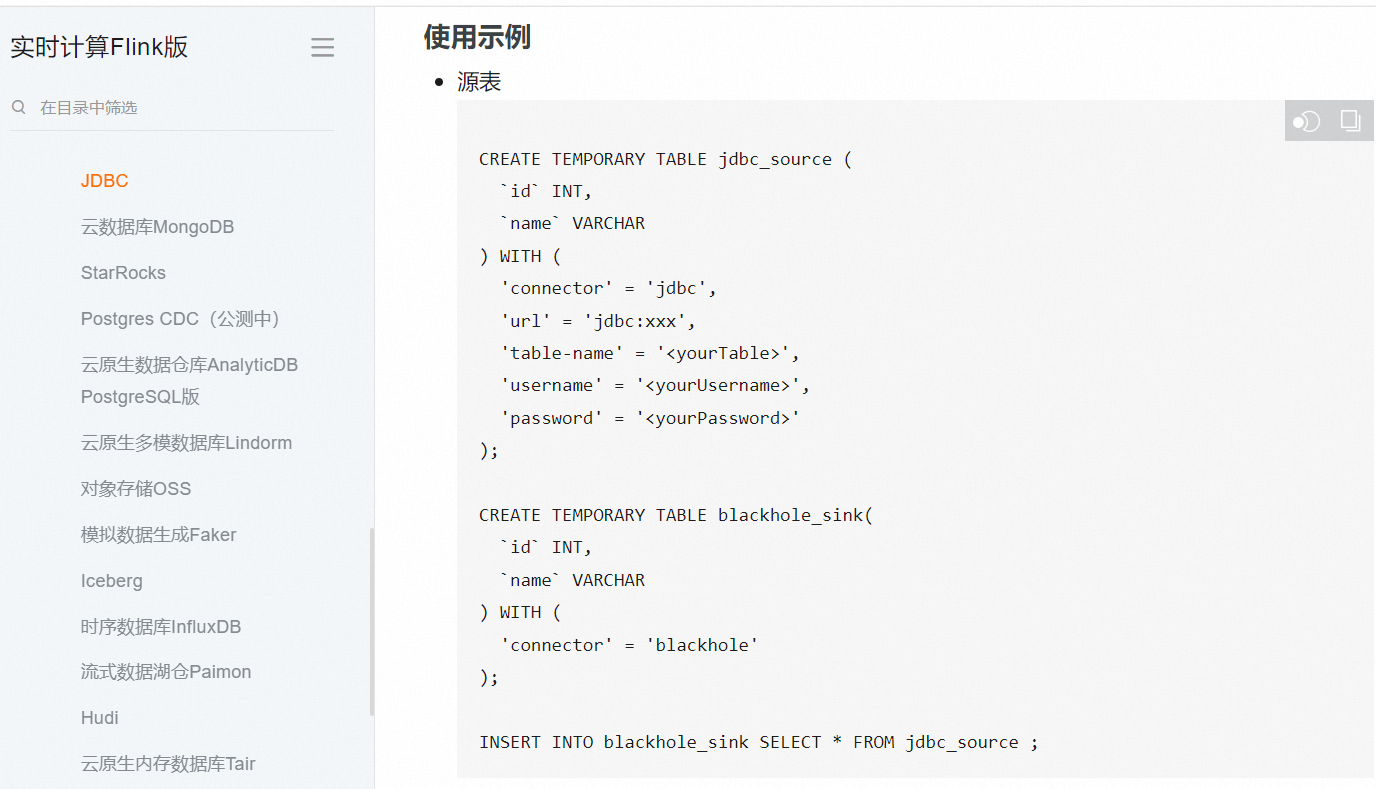
目前,尚未有官方提供的 Flink CDC 到 GaussDB 的连接器。然而,您可以通过以下两种方法来实现 Flink CDC 到 GaussDB 的数据同步:
自定义连接器:GaussDB 是一种支持 JDBC 连接的数据库,您可以使用 Flink 提供的 JDBC 连接器来与其进行交互。您可以编写自定义的 Flink CDC Job,将捕获的变更数据发送到 GaussDB 中。这样,您可以根据具体需求自定义数据的转换和同步逻辑。
使用其他中间件或工具:如果您希望简化整个数据同步过程,并减少手动编写代码的工作量,可以考虑使用其他中间件或工具来实现 Flink CDC 到 GaussDB 的集成。例如,您可以使用 Apache Kafka 作为中间件,将 Flink CDC 捕获的变更数据发送到 Kafka 主题中,然后使用特定的 Kafka Connector 将数据从 Kafka 主题写入 GaussDB。这样的架构可以提供更高的可扩展性和灵活性。
无论您选择哪种方式,都需要确保合适的数据格式转换、数据一致性以及正确的权限和安全性控制。
Flink CDC到GaussDB没有现成的连接器,需要通过数据流API或SQL Client自行开发连接器。
但有几点需要注意:
GaussDB提供了binlog日志,可以借助binlog实现CDC的功能。这与Flink CDC本身读取数据库binlog日志的机制是一致的。
GaussDB JDBC驱动可以连接GaussDB,所以可以通过Flink的JDBC数据源将CDC出来的数据写入到GaussDB。
Flink SQL Client支持GaussDB,也可以将CDC的输出转换成SQL写入GaussDB。
方法一和方法二都需要实现binlog解析和变更记录提取,以及CDC状态检查和恢复等功能。
相比直接JDBC写入,使用SQL Client可以利用SQL的数据同步能力,实现更佳的性能。
地域厂商发布的方案文档中没看到具体Flink CDC到GaussDB的案例。
可以参考Flink CDC现有的连接器,参照其设计思路开发GaussDB连接器。
如果您想要使用Flink CDC连接GaussDB数据库,可以通过以下方式进行:
查看Flink CDC的配置文件:在Flink CDC的配置文件中,可以查看connector参数,以确定Flink CDC支持的数据库类型。例如,如果您的Flink CDC支持连接GaussDB数据库,那么您可以在connector参数中指定GaussDB数据库的连接信息。
查看Flink CDC的启动命令:在Flink CDC的启动命令中,可以查看--add-plugins参数,以确定Flink CDC支持的数据库类型。例如,如果您的Flink CDC支持连接GaussDB数据库,那么您可以在--add-plugins参数中指定GaussDB数据库的插件信息。
需要注意的是,如果您在生产环境中使用Flink CDC连接GaussDB数据库,那么您需要确保Flink CDC使用的是稳定版本的GaussDB数据库连接器。同时,您还需要确保Flink CDC的数据备份和恢复机制,以保证数据的安全性和可靠性。
Flink CDC (Change Data Capture) 是 Flink 的一个功能,用于实时捕获数据源的变化,并将这些变化转换为可操作的数据流。GaussDB 是一个基于列存储的 NoSQL 数据库,可以用作 Flink CDC 的目标数据源。
要将 Flink CDC 应用程序部署到 GaussDB 上,您需要执行以下步骤:
配置 Flink CDC,以便它可以连接到 GaussDB 数据库。
将 Flink CDC 应用程序部署到 Flink 集群中,以便它可以在 Flink 集群中运行。
在 Flink 中配置 GaussDB 数据源,并使用 Flink SQL API 来查询和操作数据。
关于 Flink CDC 和 GaussDB 的更多信息,请参阅以下文档:
Flink 官方文档中关于 CDC 的部分:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/connectors/cdc.html
GaussDB 官方文档:https://doc.oceanbase.com.cn/gaussiondb/latest/zh/dev/index.html
Flink 官方文档中关于 Flink SQL API 的部分:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/connectors/jdbc.html#flink-sql
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


