
论文
论文:X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION
摘要
被训练用于区分说话人的深度神经网络把可变长的话语映射为固定维度的embedding,也我们叫它x-vector。先前的研究发现这种embedding在利用大规模的训练数据集后性能优于了i-vector,但是搜集大量高质量的标记的训练数据是一个挑战,所以我们使用包含增加噪声和混响的数据增强来作为一种价格低廉的增加训练数据数量和提升鲁棒性的方法。x-vector在数据集WILD和NIST SRE 2016 Cantonese 上于i-vector进行比较。我们发现,虽然在PLDA分类器中增强是有利的,但在i-vector提取器中却没有帮助。然而,x-vectorDNN有效地利用了数据增强,由于它的监督训练。结果表明,x-vector在评估数据集上具有较好的性能。
PS:这篇文章的结果表明x-vector在大量数据的情况下性能非常好,是为来语音表示的主要发展方向
模型结构
本文使用两种i-vector作为基准系统,一种是acoustic i-vector,一种是Phonetic bottleneck i-vector,被评估的系统是x-vector。
acoustic i-vector
这是一个传统的GMM-UBM系统,具体配置在上一篇博客中有。
1.模型:输入(60-d)→ \rightarrow→UBM(2048,4096,5297-c)→ \rightarrow→i-vector extractor(600-d)→ \rightarrow→PLDA;
2.输入:共60维,20维MFCC+Delta+acceleration,25ms帧长,平均归一化,最大3s窗口,基于能量的SAD;
3.UBM:full-covariance GMM with 2048 components;
4.i-vector:600-d;
5.PLDA:下面单独介绍
Phonetic bottleneck i-vector
这个i-vector从自动语音识别的深度神经网络声学模型[1]中引入了瓶颈特征(BNF)。这个DNN是一个使用p-norm作为非线性(激活函数)的TDNN,结构和[2](这篇论文在前面的博客中也有写,传送门)中一样,只不过把倒数第二层换成了瓶颈层(bottleneck layer),BNFs与上一个i-vector中描述的相同的20维MFCCs和delta连接,以创建100维特性。该系统的其余部件(特征处理、UBM、i矢量提取器和PLDA分类器)与acoustic i-vector系统相同。
x-vector
这个DNN emdedding是基于[3]中的,在这里对其详细描述。
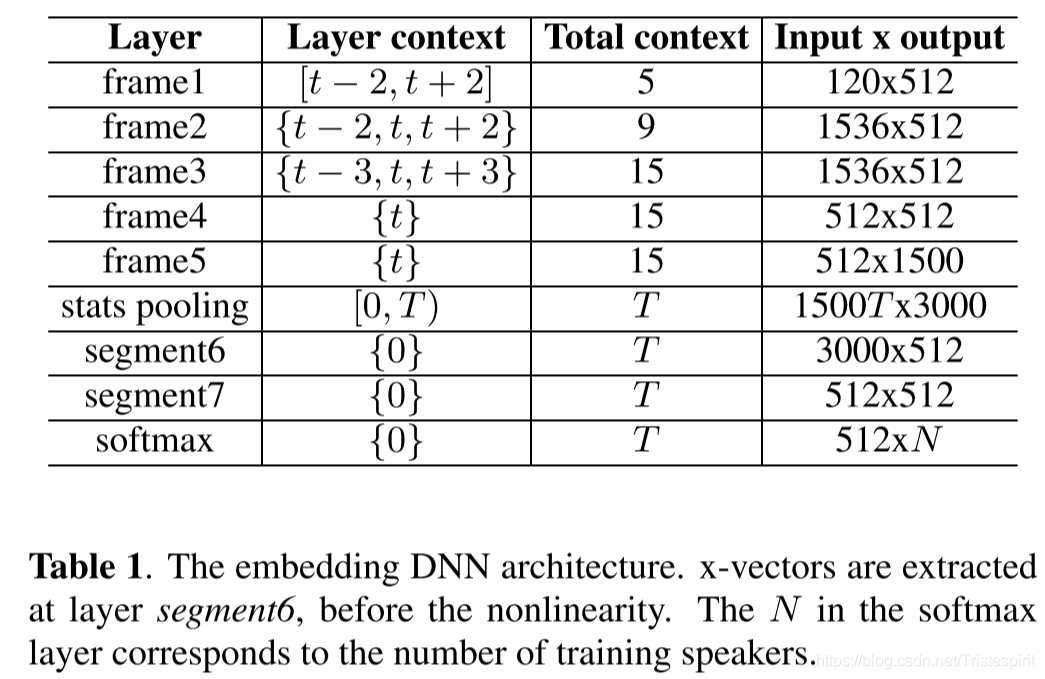
输入:24-d滤波器组,帧长25ms,均值归一化,在最多3s的滑动窗口上,基于能量的SAD;
如上表所示,在1到5层有以当前帧t为中心的一个小的时间上下文,比如第3层的输入就是第二层输出的叠加,统计池化层从第5层汇聚了T个帧级的输出并且计算其均值和标准差。这个统计量是为每个输入段计算一次的1500-d的向量。这个过程汇聚了所有时间维度的信息,以便后面的层对整个段进行操作。均值和标准差连接起来然后传播到segment层和最终的softmax输出层。这里的激活函数都是ReLU。
DNN使用的训练数据,每一个训练例子是由平均3s长度的语音特征以及对应的说话人标签组成。训练完成后,enbedding从segment6输出的仿射分量中提取,去除了segment7和softmax层。
PLDA classifier
x-vector和i-vector系统使用相同类型的PLDA分类器。这个表示(x向量或i向量)中心化,并使用LDA进行投影。LDA维度在SITW开发集上进行了调整,i-vector设置为200,x-vector设置为150。在降维后,对表示进行长度归一化,采用PLDA建模。采用自适应s-norm对得分进行归一化。
数据集
1.SWBD portion consists of Switchboard 2 Phases 1, 2, and 3 as well as Switchboard Cellular;
2.NIST SREs from 2004 to 2010;
3.VoxCeleb dataset.
4.SITW
5.Fisher English corpus
提取器使用1和2来训练,PLDA分类器使用2来训练。3和4中说话人后重复所以从3中删除重复的部分。5用来训练自动语音识别的DNN,为了实现有限形式的领域适应,把4和SRE16的开发数据汇集起来,用于中心化和评分标准化。
数据增强
babble
music
nois
reverb
结果
在接下来的章节中,我们使用术语提取器来指代UBM/T或嵌入的DNN。
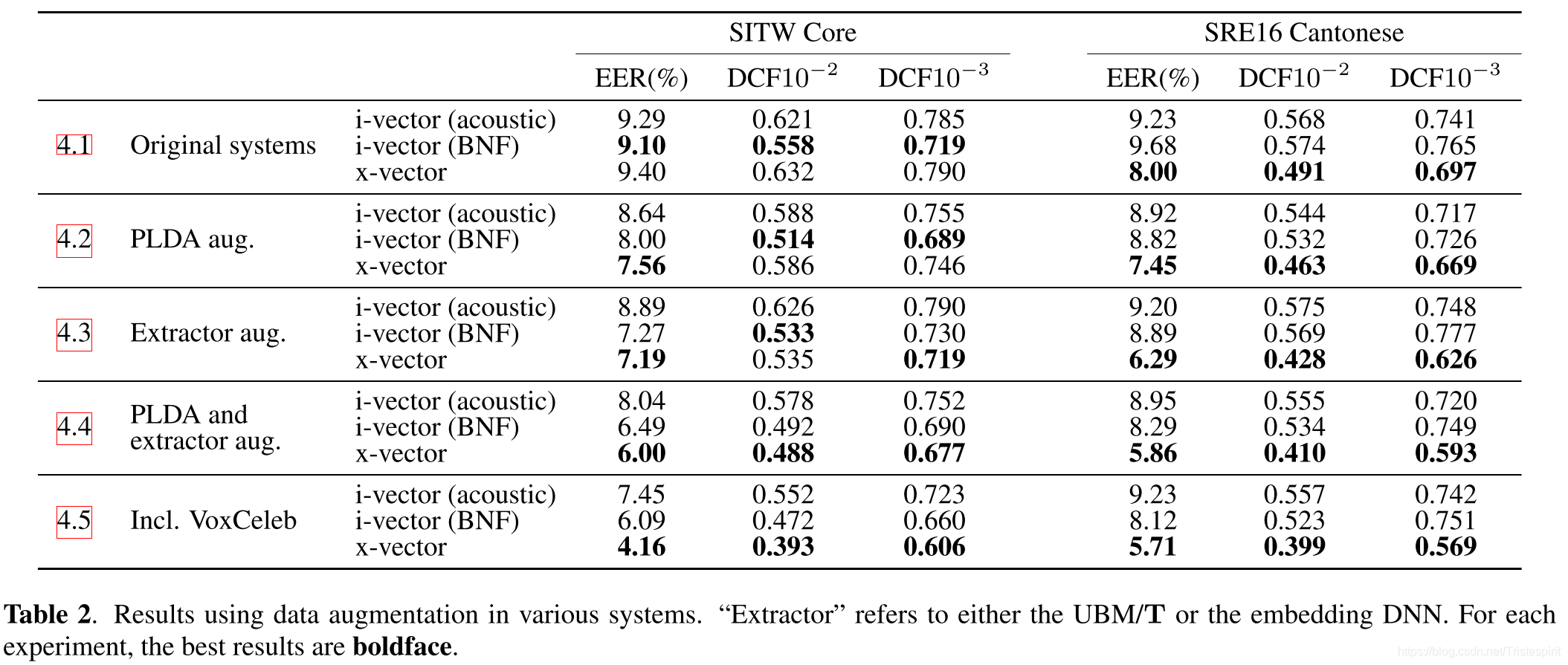
实验分成了5组:
1.原始系统:没有进行数据增强,对3个系统进行比较:x-vector没有体现出特别的优势。
2.对PLDA进行数据增强:3个系统的性能都获得了提升,但是x-vector的提升最大,数据集SITW上仅仅EER略低,但其它指标不如i-vector,但是在SRE16上所有指标都比i-vector好,其中DCF10-2优势最明显。
3.对extractor进行数据增强:i-vector并没有获得明显提升,但x-vector获得了大幅提升。
4.同时对PLDA和extractor进行数据增强:x-vector保持了一个巨大的性能优势。
5.使用VoxCeleb dataset:由于之前的实验中,只使用了电话语音,该实验中引入麦克风语音并对该数据集进行数据增强。在SITW上,i-vector和x-vector都取得了显著的提升,但x-vector取得的提升更为巨大,在SRE16上,i-vector几乎没有变化,但x-vecctor依然有微弱的提升。
总结
因为x-vector的各种优势巴拉巴拉,所以是下一代说话人表示的有力竞争者。(当然现在这已经变成了现实,x-vector是当下最流行的)。
[1]M. McLaren, Y. Lei, and L. Ferrer, “Advances in deep neural network approaches to speaker recognition,” in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE Interna-
tional Conference on. IEEE, 2015, pp. 4814–4818.
[2]D. Snyder, D. Garcia-Romero, and D. Povey, “Time delay deep neural network-based universal background models for speaker recognition,” in 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE, 2015, pp. 92–97.
[3]D. Snyder, D. Garcia-Romero, D. Povey, and S. Khudanpur, “Deep neural network embeddings for text-independent speaker verification,” Proc. Interspeech, pp. 999–1003, 2017.
————————————————
原文链接:https://blog.csdn.net/Tristespirit/article/details/115831097

