
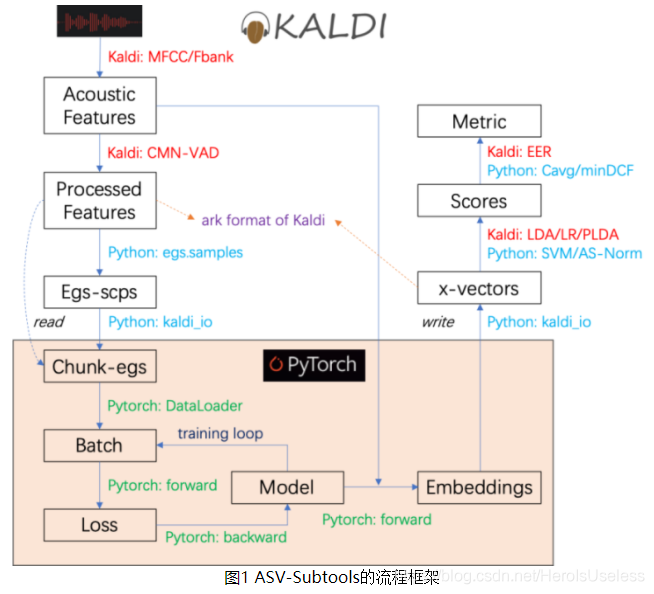
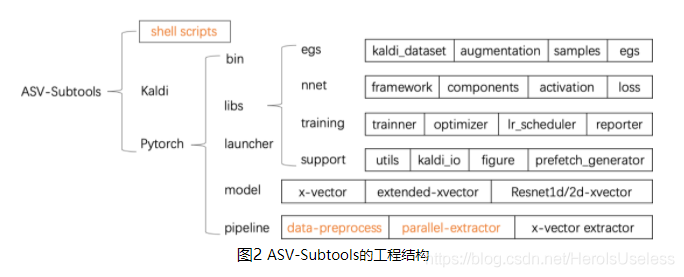
厦门大学智能语音实验室(XMUSPEECH)提供了基于Kaldi和Pytorch两个开源平台的基线系统:基于Kaldi的i-vector系统和x-vector系统,基于Pytorch的x-vector系统。
厦门大学智能语音实验室同时开源了ASV-Subtools工具,ASV-Subtools工具相比于其他开源工具的优势在于其整合了Pytorch的训练和Kaldi的前端后端处理,可用于声纹识别系统的搭建。
1、先将数据采样率降到16k
写了一个脚本,可以了
2、准备要提取数据的wav.scp、utt2spk、spk2utt。
spk2utt 是说话人id(记作spkid)和说话人语音名称(uttid)的对应关系,通常来讲,一个说话人会有很多条语音,文件中的格式为,spkid uttid1 uttid2...,每一行有且只有一个说话人id。
例如 zws wav1 wav2 wav3...

需要注意的是,每一行的uttid顺序需要按照sort命令的排序模式来排,以及spkid也需要按照排序命令sort的模式来排。否则kaldi脚本在进行validate_data_dir.sh的时候报错。
utt2spk 是单个语音名称uttid和说话人的对应,很明显每行都是一一对应关系。例如 wav1 zws
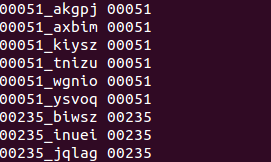
utt2spk也可以由kaldi自带脚本和spk2utt生成,也可以由自己写脚本完成
wav.scp 是语音名称uttid和其完整路径的对应,也是每行一个音频。
wav1 /home/beibei/data1/zws_subtools/test1.wav
如果需要训练性别有关的模型,还需要加入spk2gender的文本文件,但显然用不到了
搞定
这个需要自己搞
3、提取fbank_41,fbank是类似于mfcc的特征
bash subtools/makeFeatures.sh data/fbank_41/aishell3/enroll fbank conf/fbank_41_16k.conf
这个东西,我安装不了。。。说不定还真的需要自己安装!因为python环境不一样啊。。。自己造吧。。。
说实话你要造一个完全没问题的Ubuntu。。。
4、做vad
subtools/computeVad.sh data/fbank_41/aishell3/enroll conf/vad-5.0.conf
说实话这里有大问题
5、提取一下512维xvector
bash run_train_my.sh
6、降维
bash scoreSets_lad.sh
这里可能还需要用加噪的数据训练plda打分
7、转成txt文件
copy-vector ark:exp/ftdnn_xv_train_4kh_aug_warmR_fbank_41_16k_pytorch/far_epoch_18/all/xvector_lda256.ark ark,t:- > exp/ftdnn_xv_train_4kh_aug_warmR_fbank_41_16k_pytorch/far_epoch_18/all/xvector_256_18.txt
8、每个矩阵放一个文件
python write_xvector.py exp/ftdnn_xv_train_4kh_aug_warmR_fbank_41_16k_pytorch/far_epoch_18/all/xvector_256_18.txt exp/ftdnn_xv_train_4kh_aug_warmR_fbank_41_16k_pytorch/far_epoch_18/all/xvector_256_18/
就差最后的转成txt文件了卧槽。搞不定。。。
这还真TM的慢啊。。。
肝不动啊,看来用512的了,但是就一个512啊,不赖啊。。。就算有speaker_id也没有任何关系了。
1. 用aishell3 训练的模型 提取的 128 维 xv /tsdata/cyx/aishell3_xv/128/xvector_128_21
2. 用大量中文数据库提取的 512 维xv /tsdata/cyx/aishell3_xv/512
5. 用大量中文数据库提取的 256维xv /tsdata/cyx/aishell3_xv/256/xvector_256_18
3. 用大量中文数据库提取的 128维xv /tsdata/cyx/aishell3_xv/128/xvector_128_18
4. 用大量中文数据库提取的 512 维xv (同2)
那老师的也能用了。。。
卧槽不一样。。。只能说,emmmm,没办法了,只能重新训练了。那个aishell的embed是谁提取出来的?可能一开始就有吧。。。
虽然不一样,但是加进去看看行不行啊。。。但是decode没办法啊,人家都把内存用完了。。。
今晚三个工作,做完训练fs2的准备工作 7-8
那绝对没问题了,接下来修改代码。分为fs,fs2和config,conf没变啊。。。没变就没变呗。准备完毕了,就等着训练了。512大数据的。
那个新melgan效果真是惊人,/data/OB/TensorFlowTTS-master-new/TensorflowTTS-work/examples/melgan/exp/melgan_16k_new_config/predictions/
/data/OB/TensorFlowTTS-master-new/TensorflowTTS-work/examples/melgan/exp/melgan_16k_new_config/checkpoints/
/data/OB/TensorFlowTTS-master-new/TensorflowTTS-work/examples/melgan/conf/
再训练几天,就真的太强大了。后面的噪音是我固定的,这个可以改。melgan的停了?怎么停了呢?
并不见得那么好哈,念的太快了。而且后面有电音啊。。。这个有待观察。
移植subtools 8-9
注意在fbank的conf中,帧长为25,这个需要注意。
在370行,为什么需要三层结构,啊,因为这里确定的。不好起名字,而且好像还没模型。
它这个为啥这么慢呢?它这个容易卡住啊?
没有那玩意会重新训练的。。。看来自己改不动啊。。。
整体移植吧。。。
一个zcvf,一个zxvf,没问题的
啊?明白了,路径不对!你知道有多少绝对路径啊。。。
Syntax error: Bad for loop variable
从 ubuntu 6.10 开始,ubuntu 就将先前默认的bash shell 更换成了dash shell;其表现为 /bin/sh 链接倒了/bin/dash而不是传统的/bin/bash。
卧槽重新命个名都不可以吗?
成功了一次!我认为这个绝对路径是kaldi自己造的。。。卡住了。。。
成功了卧槽。
————————————————
原文链接:https://blog.csdn.net/HeroIsUseless/article/details/115772367

