
介绍
Insight Face在2019年提出的最新人脸检测模型,原模型使用了deformable convolution和dense regression loss, 当时在 WiderFace 数据集上达到SOTA。
基网络有三种结构,基于ResNet的ResNet50和ResNet152版本能提供更好的精度,以及基于mobilenet(0.25)的轻量版本mnet,检测速度更快。
简化版mnet结构
RetinaFace的mnet本质是基于RetinaNet的结构,采用了特征金字塔的技术,实现了多尺度信息的融合,对检测小物体有重要的作用,RetinaNet的结构如下:
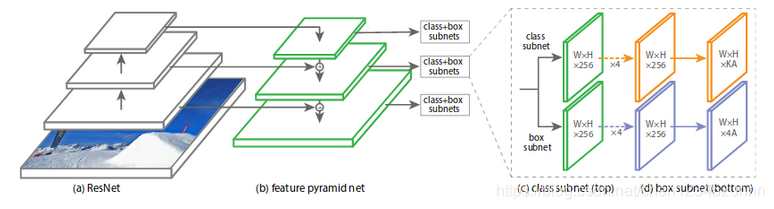
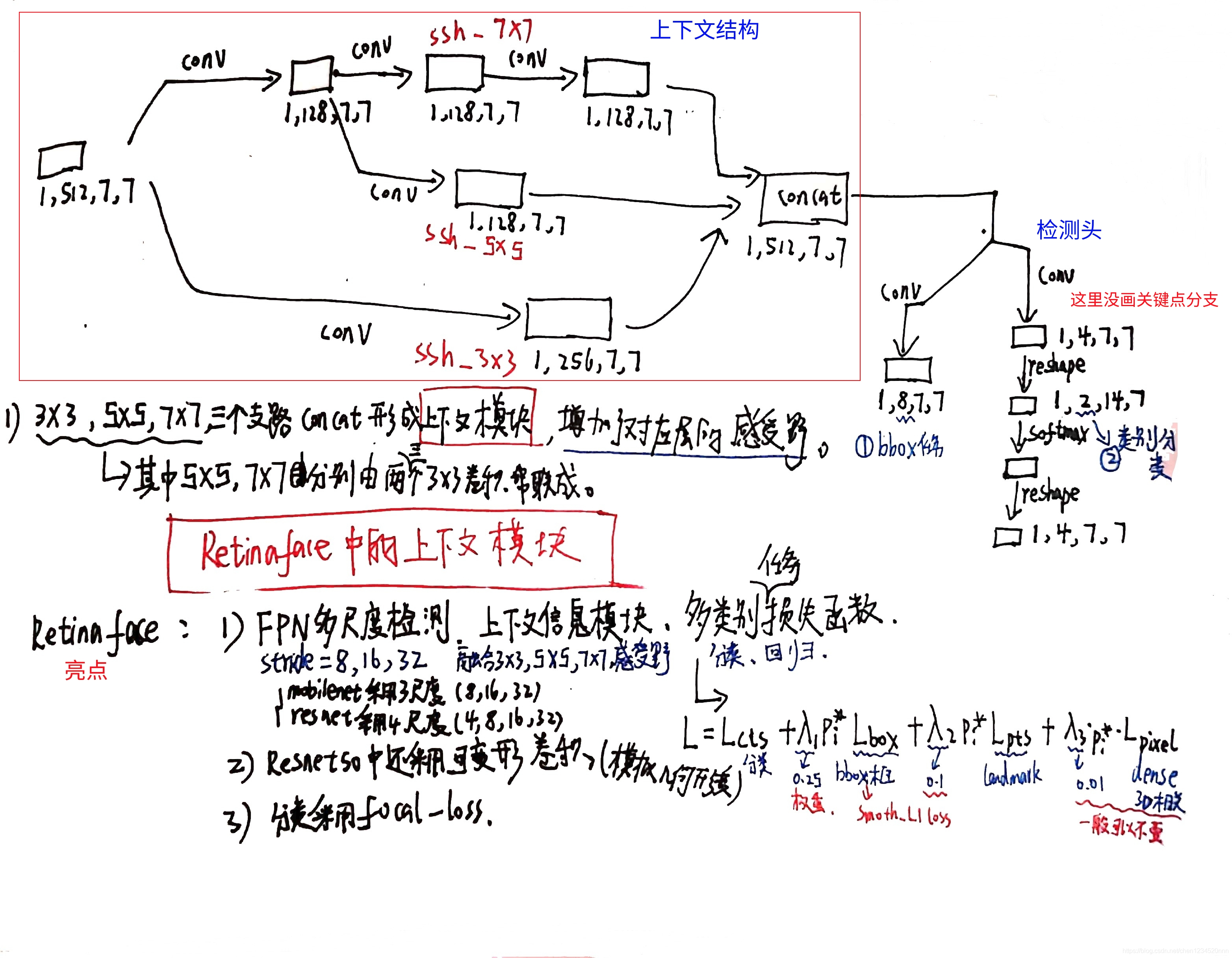
简化版mnet与RetinaNet的区别除了在于主干网络的选择上使用了mobilenet做到了模型的轻量化,最大的区别在于检测模块的设计。mnet使用了SSH检测网络的检测模块,SSH检测模块由SSH上下文模块组成,上下文信息结构位于网络末尾的检测头位置。
上下文结构模块细节:
这部分是文章一个比较重要的理解点,下面手绘图有上下文信息的结构图(个人感觉和inception有点类似)和Retinaface的几个亮点。
附一个专业点的解释:
Context Modelling:提升模型的上下文模块推理能力以捕获微小人脸,SSH和PyramidBox在特征金字塔上用context modules扩大欧几里德网格的感受野。
为了提高CNNs的非刚性变换建模能力,可变形卷积网络(deformable convolution network, DCN)采用了一种新的可变形层对几何变换进行建模
原文链接:https://blog.csdn.net/flyfor2013/article/details/105337298
网络的Loss函数:
多任务组合loss:
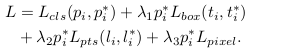
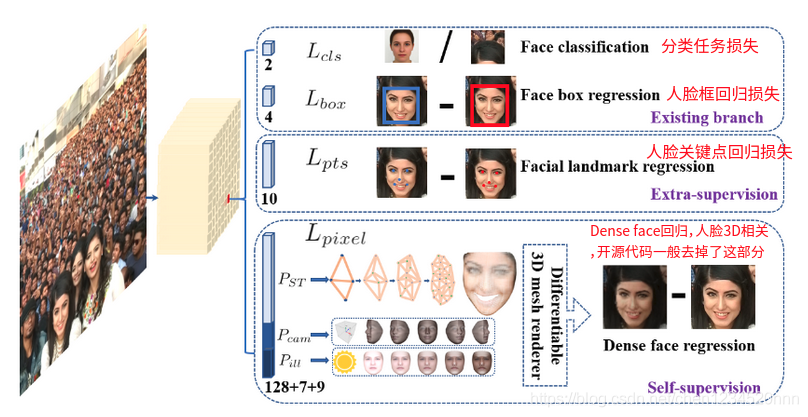
(1)人脸分类loss Lcls(pi,pi*),这里的pi是anchor i为人脸的预测概率,对于pi * 是1是positive anchor,0代表为negative anchor。分类loss Lcls是softmax loss 在二分类的情况(人脸/非人脸)。
(2)人脸框回归loss,Lbox(ti,ti*),这里的ti={tx,ty,tw,th},ti * ={tx *,ty *,tw * ,th *}分别代表positive anchor相关的预测框和真实框(ground-truth box)的坐标。我们按照 [16]对回归框目标(中心坐标,宽和高)进行归一化,使用Lbox(ti,ti *)=R(ti-ti *),这里R 是 Robust loss function(smooth-L1)(参考文献16中定义)
(3)人脸的landmark回归loss Lpts(li,li *),这里li={l x1,l y1,...l x5,l y5},li *={l x1 *,l y1 *,...l x5 *,l y5 *}代表预测的五个人脸关键点和基准点(ground-truth)。五个人脸关键点的回归也采用了基于anchor中心的目标归一化。
(4)Dense回归loss Lpixel (参考方程3)。loss调节参数 λ1-λ3 设置为0.25,0.1和0.01,这意味着在监督信号中,我们增加了边界框和关键点定位的重要性,也侧面反应最后那个Dense 任务loss重要性比较低。
Pytorch-RetinaFace 详解(带代码讲解):
https://zhuanlan.zhihu.com/p/157297085
原文链接:https://blog.csdn.net/chen1234520nnn/article/details/118176979

