
有大佬能指条路吗?弄了一天了[捂脸哭]
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC导出到PostgreSQL时,需要添加以下依赖项:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>${postgresql.version}</version>
</dependency>
其中${flink.version}和${postgresql.version}需要替换为对应的版本号。
另外,还需要配置Flink的JDBC连接信息,可以在Flink的配置文件中添加以下配置:
# PostgreSQL连接信息
# 注意:这里的url、username和password需要根据实际情况进行修改
flink.connector.jdbc.url=jdbc:postgresql://localhost:5432/mydatabase
flink.connector.jdbc.table=mytable
flink.connector.jdbc.username=username
flink.connector.jdbc.password=password
需要根据实际情况修改url、username和password的值,以正确连接到PostgreSQL数据库。
在代码中,可以使用JDBCOutputFormat来将数据导出到PostgreSQL。例如:
String insertQuery = "INSERT INTO mytable (column1, column2) VALUES (?, ?)";
JDBCOutputFormat jdbcOutput = JDBCOutputFormat
.buildJDBCOutputFormat()
.setDrivername("org.postgresql.Driver")
.setDBUrl("jdbc:postgresql://localhost:5432/mydatabase")
.setUsername("username")
.setPassword("password")
.setQuery(insertQuery)
.finish();
DataStream<Row> dataStream = ...; // 输入数据流
dataStream.writeUsingOutputFormat(jdbcOutput);
以上代码中的insertQuery需要根据实际表结构进行修改,dataStream为输入的数据流,可以根据需求进行调整。
楼主你好,需要导入以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>${postgresql.version}</version>
</dependency>
其中 ${flink.version} 和 ${postgresql.version} 需要替换为相应的版本号。
要将 Flink CDC 导出到 PostgreSQL,您需要在项目的依赖中添加相应的库。以下是导入到 PostgreSQL 所需的主要依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>版本号</version>
</dependency>
请确保将 ${flink.version} 替换为您正在使用的 Flink 版本,并将 版本号 替换为您所需的 PostgreSQL 驱动程序版本。
此外,还可能需要根据具体的需求添加其他依赖,如 JSON 库、日期时间库等,这取决于您在导出过程中要处理的数据类型和格式。
使用 Flink CDC 将数据导出到 PostgreSQL 数据库,需要导入以下依赖:
Flink JDBC Connector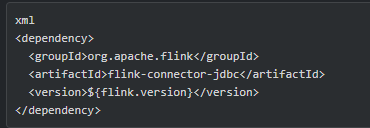
PostgreSQL JDBC 驱动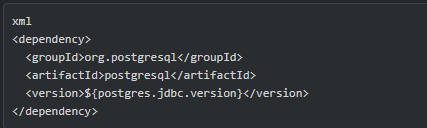
常用的版本比如 42.2.5 和 above。
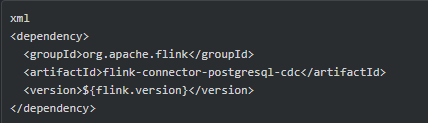
此外,还可以根据需要加入相关的武装数据格式(Json/Avro等)的依赖。
在创建 JDBC Sink 时,需要设置正确的 JDBC URL、用户名和密码等来连接 PostgreSQL。
如果你要使用Flink CDC将数据导出到PostgreSQL数据库,需要在项目中引入对应的 JDBC 驱动依赖。具体来说就是 PostgreSQL 的 JDBC 驱动包。
这个驱动包的 Maven 依赖大概如下(请根据实际情况选择合适的版本):
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.5</version>
</dependency>
有了这个依赖,你就可以在 Flink 中使用 JDBC 连接器(connector)将数据写入到 PostgreSQL 数据库中。连接器的具体使用方法可以参考官方文档或者相关示例代码。
要将Flink CDC导出到PostgreSQL,你需要在Flink应用程序中导入以下依赖关系:
flink-connector-jdbc:用于将数据写入PostgreSQL;
flink-cdc-connectors:用于提供与CDC相关的类和接口。
例如,使用Maven,你可以在你的pom.xml文件中添加以下依赖项:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId <version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cdc-connectors_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
这些依赖关系将允你使用Flink CDC将数据从Source(如MySQL、Oracle等)提取出来,并将其写入PostgreSQL Sink。但是,在实际使用中,你还需要提供正确的JDBC连接字符串、用户名和密码以及其他必要的参数,以确保成功连接到PostgreSQL数据库。
要将 Flink CDC 导出到 PostgreSQL(pg),你需要添加以下依赖项:
Flink JDBC Connector 依赖:这是用于与 PostgreSQL 进行连接和数据导出的 JDBC 驱动程序。你可以在 Flink 的 pom.xml 文件中添加以下依赖:
xml
Copy
org.apache.flink
flink-connector-jdbc_2.12
${flink.version}
请确保将 ${flink.version} 替换为你正在使用的 Flink 版本。
PostgreSQL JDBC 驱动程序依赖:你需要添加 PostgreSQL JDBC 驱动程序的依赖,以便在 Flink 中使用该驱动程序连接到 PostgreSQL 数据库。你可以在 pom.xml 文件中添加以下依赖:
xml
Copy
org.postgresql
postgresql
${postgresql.version}
请确保将 ${postgresql.version} 替换为你希望使用的 PostgreSQL 驱动程序的版本。
配置 Flink CDC 的 PostgreSQL Sink:在 Flink CDC 的配置文件中,你需要指定 PostgreSQL Sink 的连接信息和表映射规则。例如,你可以设置以下属性:
properties
Copy
sink.jdbc.url=jdbc:postgresql://localhost:5432/mydatabase
sink.jdbc.table=your_table_name
sink.jdbc.username=your_username
sink.jdbc.password=your_password
sink.jdbc.driver=org.postgresql.Driver
sink.jdbc.sink.buffer-flush.max-rows=1000
sink.jdbc.sink.buffer-flush.interval=1s
请根据你的实际情况修改以上属性,确保正确连接到 PostgreSQL 数据库并将数据导出到指定的表中。
FlinkCDC 可以导出数据到 PostgreSQL 数据库,但需要导入一些依赖项。
首先,确保您已经将 PostgreSQL JDBC 驱动程序添加到 Flink 的 classpath 中。您可以从 PostgreSQL 官方网站下载该驱动程序,并将其添加到 Flink 的 lib 目录下。
其次,您需要将以下依赖项添加到 Flink 项目的 pom.xml 文件中,以便使用 FlinkCDC 的 PostgreSQL 导出器:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-CDC-source_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
请确保将 ${flink.version} 替换为您使用的 Flink 版本号。
最后,您需要编写 FlinkCDC 的配置文件,指定要导出的数据库和表的信息,以及 PostgreSQL 的连接信息。以下是一个示例配置文件的内容:
# FlinkCDC 配置
CDC:
# 数据库连接信息
database: your_database_name
hostname: your_database_host
port: your_database_port
username: your_username
password: your_password
schema: your_schema_name
table: your_table_name
# 其他配置项...
请将 your_database_name、your_database_host、your_database_port、your_username、your_password、your_schema_name 和 your_table_name 替换为您的实际数据库连接信息。
配置完成后,您可以使用 FlinkCDC 将数据导出到 PostgreSQL 数据库中。请参考 FlinkCDC 的官方文档和示例代码以获取更多详细信息和指导。
如果你想将Flink CDC中的数据导出到PostgreSQL中,需要使用Flink提供的JDBC连接器,同时需要导入PostgreSQL JDBC驱动依赖。
具体来说,你需要在Flink的pom.xml文件中添加以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>${postgresql.version}</version>
</dependency>
其中,${flink.version}和${postgresql.version}分别是Flink和PostgreSQL JDBC驱动的版本号,你可以根据实际情况进行修改。
在使用JDBC连接器时,你需要指定PostgreSQL数据库的连接信息,例如:
String url = "jdbc:postgresql://localhost:5432/mydb";
String username = "myuser";
String password = "mypassword";
JDBCOutputFormat outputFormat = JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("org.postgresql.Driver")
.setDBUrl(url)
.setUsername(username)
.setPassword(password)
.setQuery("INSERT INTO mytable (id, name) VALUES (?, ?)")
.finish();
在上面的示例中,我们使用了JDBCOutputFormat来将数据写入PostgreSQL中。其中,setDrivername方法指定了PostgreSQL JDBC驱动的类名,setDBUrl、setUsername和setPassword方法则用来指定连接信息,setQuery方法用来指定插入数据的SQL语句。你可以根据实际情况进行修改。
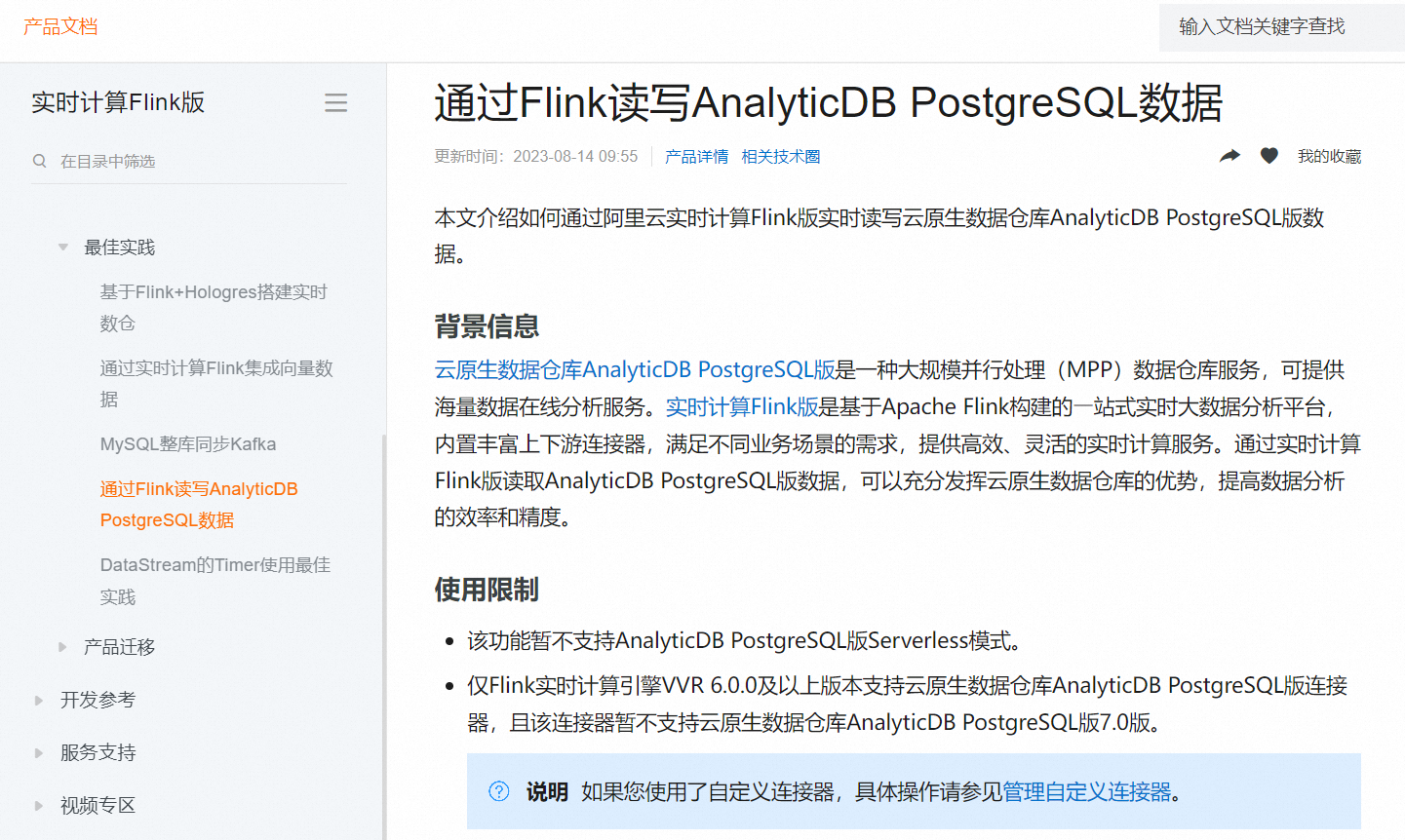
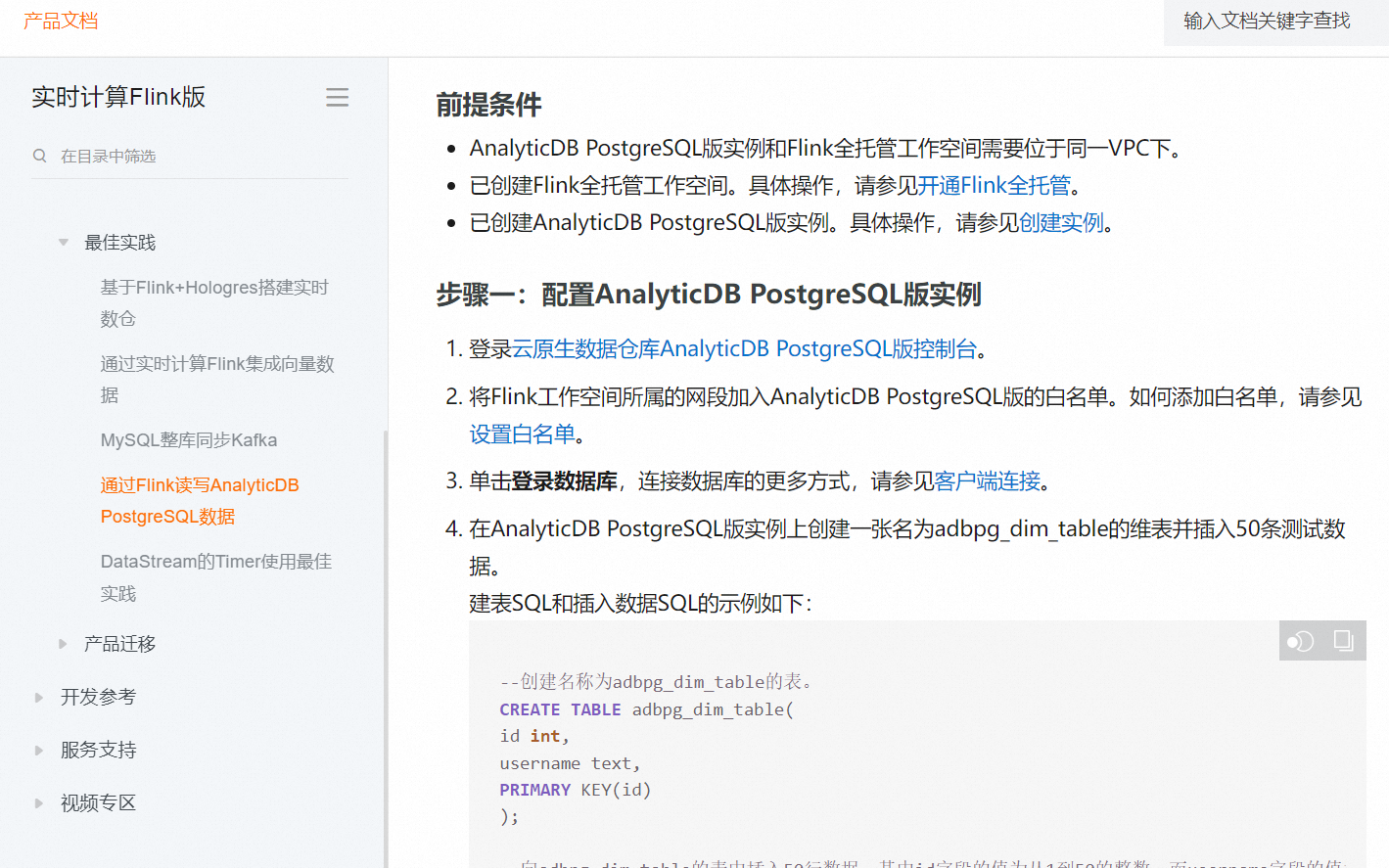
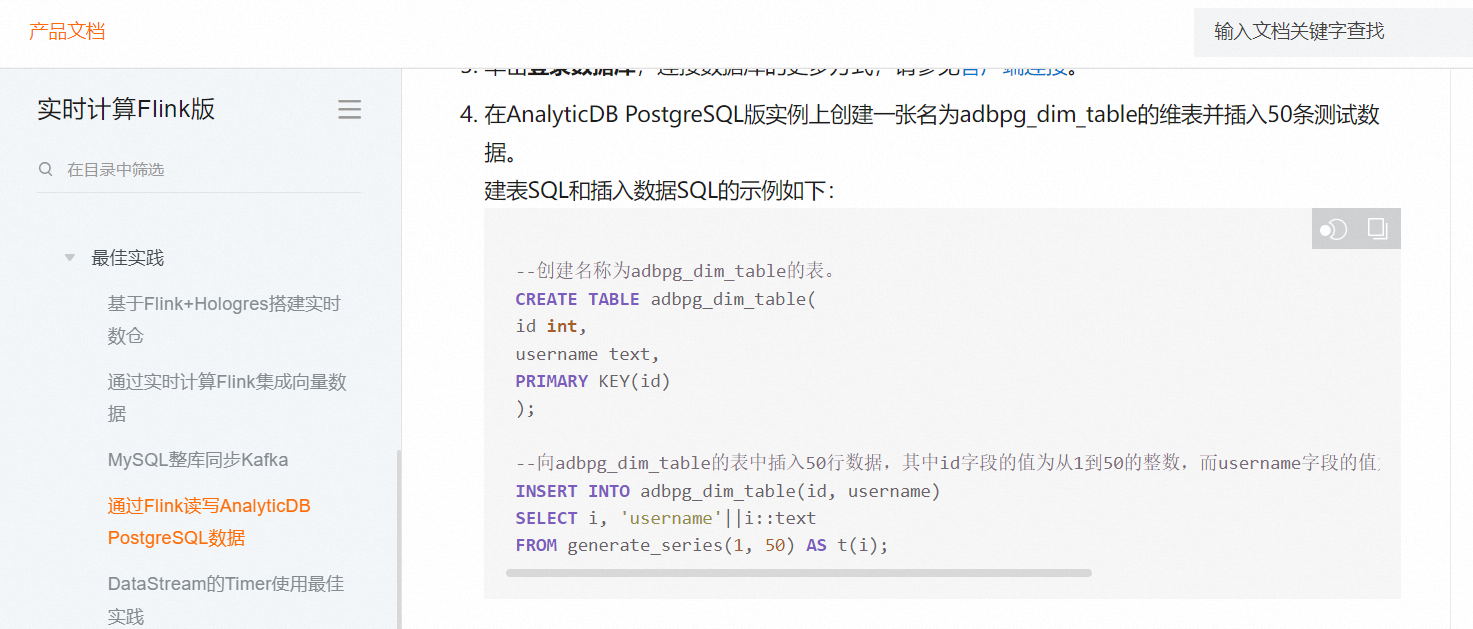
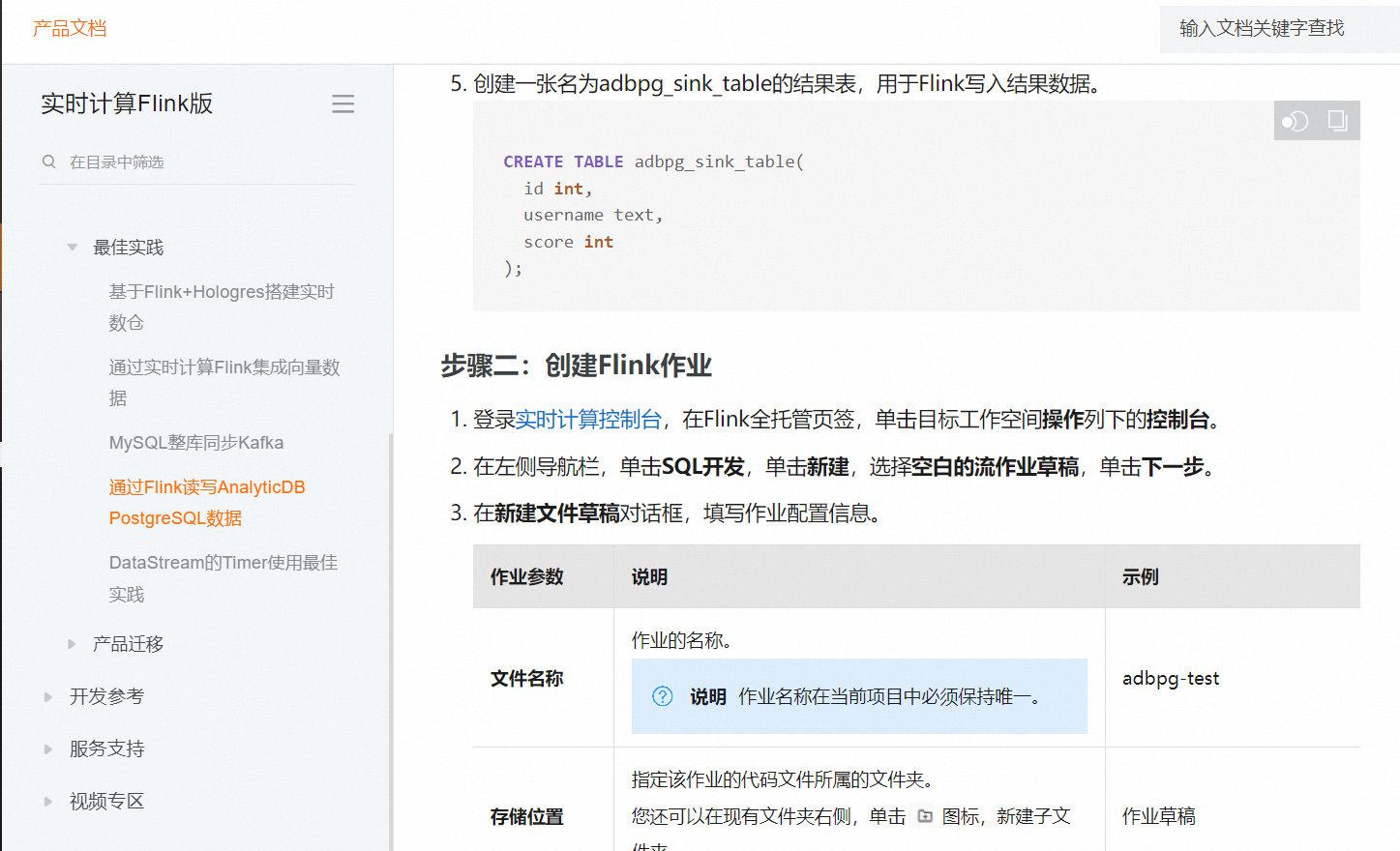
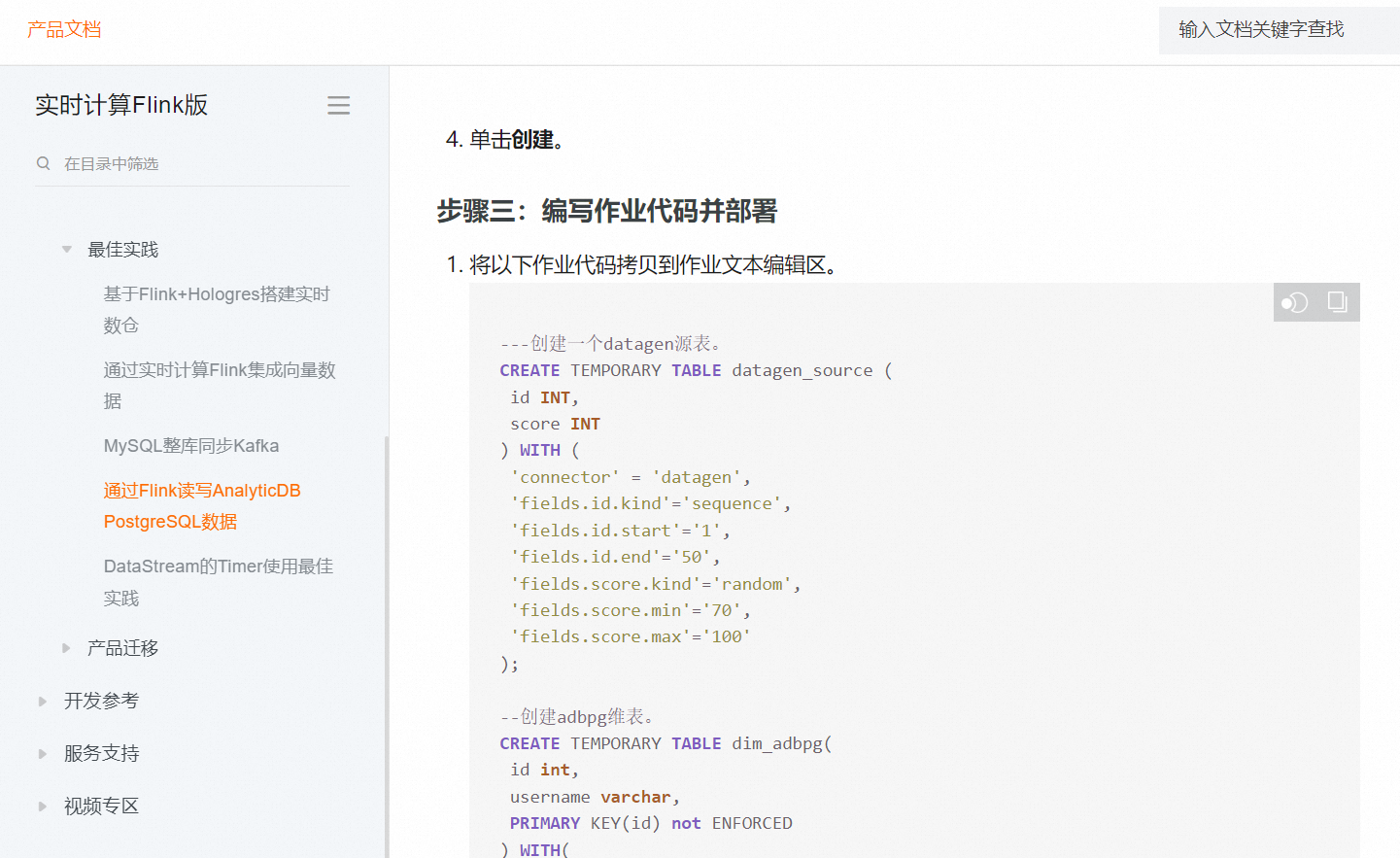
如果您想要将Flink CDC(Change Data Capture)导出到PostgreSQL中,需要导入以下依赖:
pgjdbc依赖:pgjdbc是一个用于连接PostgreSQL的Java驱动程序。您可以使用以下Maven依赖来导入pgjdbc依赖:
xml
Copy code
```
在以上Maven依赖中,为org.apache.flink,为flink-connector-jdbc,为1.14.0。
如果您对以上解释有疑问,请提供更多具体的信息,我会尽力帮助您解决问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



