
PolarDB-X中的多流复制是啥意思呀?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
PolarDB-X中的多流复制是指将一个实例的数据复制到多个实例中,每个实例都有自己的独立的复制流。多流复制可以提高数据的可靠性和可用性,避免单点故障,并且可以支持多个实例的并发写入,提高写入性能。多流复制的具体实现方式是通过在复制过程中对数据进行分片,将每个分片分配给一个独立的复制流,每个复制流都有自己的独立的复制路径和复制进度。多流复制可以通过PolarDB-X控制台或者命令行工具进行配置和管理。
楼主你好,阿里云 PolarDB-X 的多流复制是指将一个主节点的写入操作同时复制到多个备节点,以提高数据容错性和读取性能的技术。具体地说,每个备节点都会在自己的本地磁盘上保存一份完整的数据副本,并且能够及时地获取主节点的写入数据变化。
这样,当主节点发生故障或者网络故障导致无法访问时,备节点可以立即接管主节点并继续提供数据服务。另一方面,多流复制还可以将读请求分发到各个备节点,从而提高系统的读取性能和并发能力。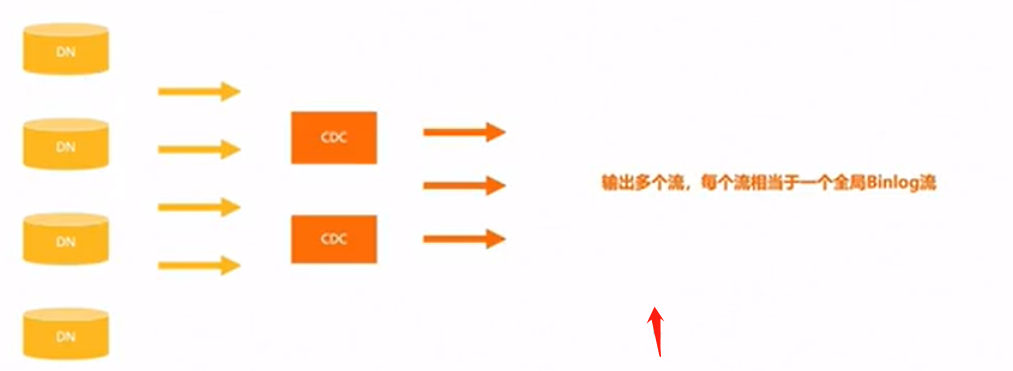
PolarDB-X中的多流复制是一种数据复制技术,它允许将一个数据库实例的数据复制到多个目标数据库实例中。这种复制技术可以用于实现高可用性、容灾、负载均衡等场景。
多流复制在PolarDB-X中是通过在源数据库实例上创建一个或多个复制流来实现的。每个复制流将源数据库的数据复制到一个目标数据库实例中。这样,就可以同时从多个目标数据库实例中读取数据,从而提高系统的性能和可靠性。
多流复制还可以用于实现数据分片,即将数据分散到多个目标数据库实例中,以增加系统的可伸缩性和并发处理能力。此外,多流复制还可以实现数据的分布式存储和备份,以提高系统的容错性和可用性。
总之,多流复制是一种高效的数据复制技术,可以用于实现多种数据库系统的扩展和容错方案。在PolarDB-X中,多流复制可以提供更高的性能和可靠性,以满足大规模数据处理和数据存储的需求。
多流复制(Multi-Stream Replication)是PolarDB-X中的一项关键功能。它是一种基于分布式存储和计算引擎的数据库复制机制,用于实现数据的高可用性和容灾性。
在传统的数据库复制中,通常使用单一的主节点(Master)和多个备用节点(Standby)的架构。主节点负责处理写操作和部分读操作,而备用节点则通过从主节点复制数据,提供读操作的支持。这种架构存在一定的限制,比如备用节点的读性能有限,无法完全解决读写负载平衡的问题。
而PolarDB-X通过引入多流复制机制,打破了传统复制架构的限制。它将数据分成多个流,每个流对应着一个备用节点。每个备用节点都可以独立地接收和处理来自主节点的数据流,并且可以提供读操作的支持。这样就实现了更好的并行化处理和负载均衡,提高了整体的读写性能。
多流复制在PolarDB-X中还具备以下优势:
高容错性:每个备用节点都包含完整的数据副本,即使主节点或某个备用节点发生故障,系统仍然可以继续正常运行。
高可用性:在主节点故障时,系统可以自动切换到一个备用节点,实现快速的故障切换,减少业务中断时间。
弹性扩展:可以通过增加更多的备用节点来水平扩展读操作和提高整体的处理能力。
总的来说,多流复制是PolarDB-X中的一项高效的数据库复制机制,通过并行处理和负载均衡,提高了数据的可用性、容错性和读写性能。
在PolarDB-X中,"多流复制"是指一种分布式事务复制技术,它允许多个数据流在多个副本之间进行同步。这种技术的目的是确保数据的一致性、可靠性和高可用性。
在PolarDB-X的多流复制系统中,每个数据流都被称为一个"流"。这些流可以来自于不同的数据源,如MySQL、PostgreSQL、Oracle等。每个流都可以在多个副本之间进行复制,从而实现数据的冗余和备份。
多流复制的主要优点是它可以显著提高系统的可用性和容错能力。当某个数据流出现故障时,其他数据流仍然可以继续工作,从而保证整个系统的稳定性。此外,多流复制还可以提高数据的读写性能,因为多个副本可以同时进行读写操作,从而减少了单个副本的负载压力。
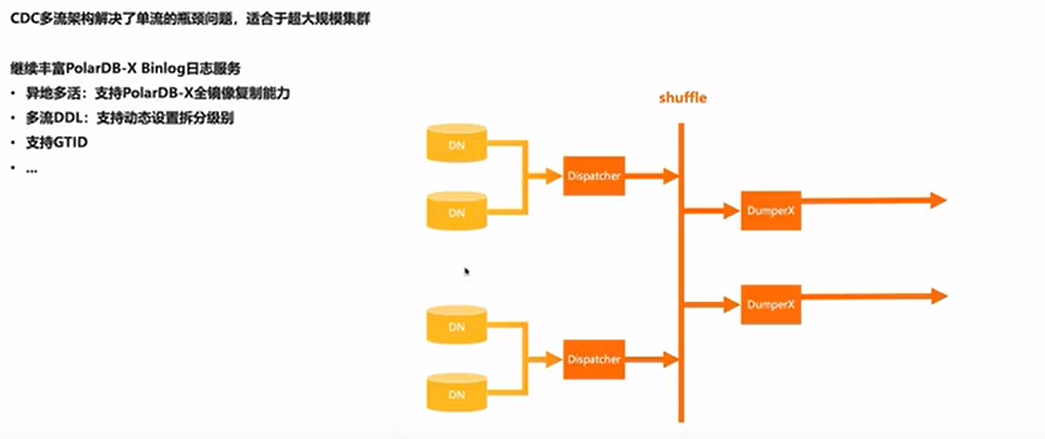
然而,多流复制也存在一定的挑战,如数据一致性问题、数据同步延迟问题等。为了解决这些问题,PolarDB-X采用了一些先进的技术,如分布式事务管理、数据校验、数据同步算法等。这些技术使得多流复制在保证数据一致性的同时,也能实现高效的数据同步。

