
怎样 处理数据不匹配问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。


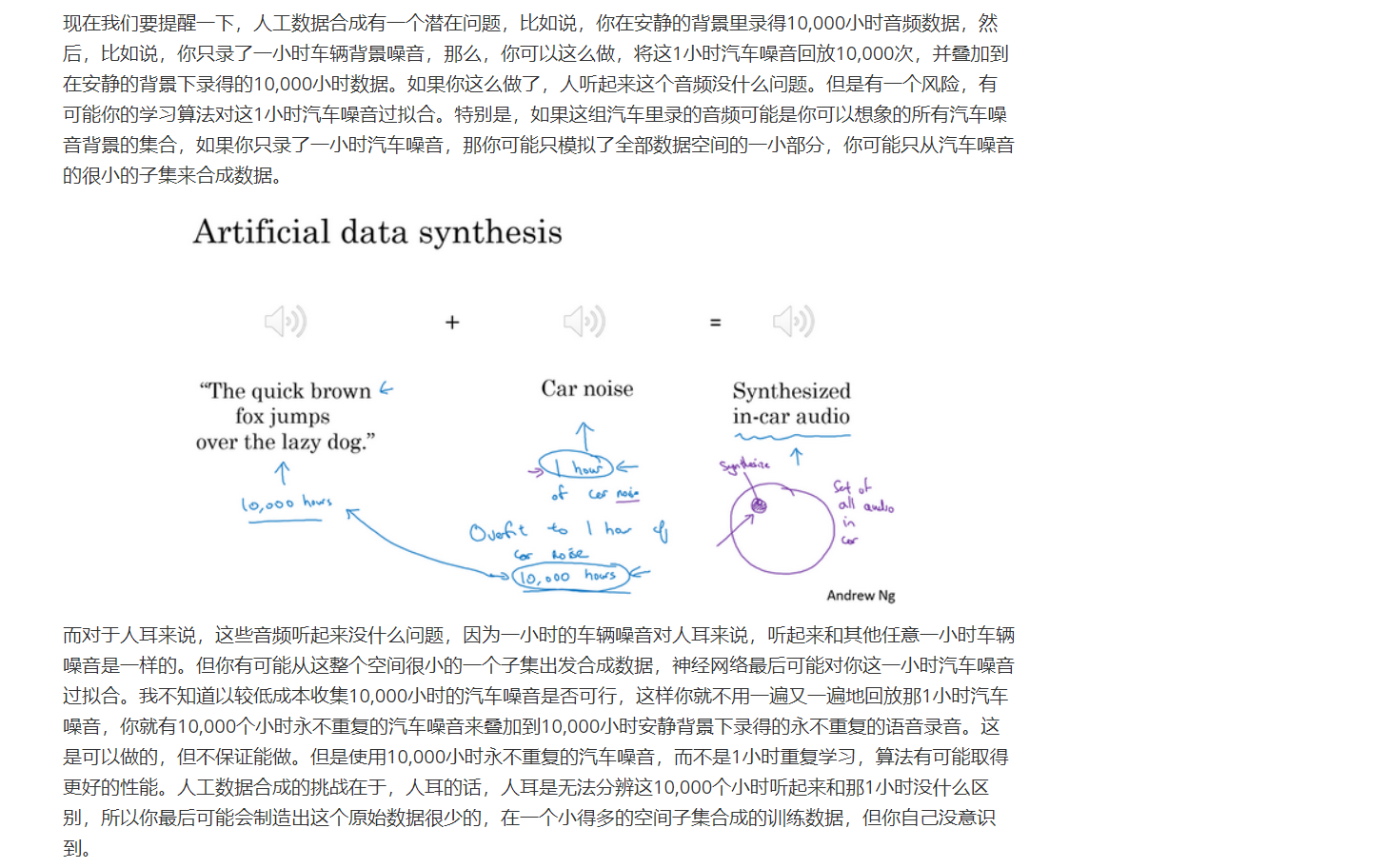
 不幸的是,上一张幻灯片介绍的情况也会在这里出现,比如这是所有车的集合,如果你只合成这些车中很小的子集,对于人眼来说也许这样合成图像没什么问题,但你的学习算法可能会对合成的这一个小子集过拟合。特别是很多人都独立提出了一个想法,一旦你找到一个电脑游戏,里面车辆渲染的画面很逼真,那么就可以截图,得到数量巨大的汽车图片数据集。事实证明,如果你仔细观察一个视频游戏,如果这个游戏只有20辆独立的车,那么这游戏看起来还行。因为你是在游戏里开车,你只看到这20辆车,这个模拟看起来相当逼真。但现实世界里车辆的设计可不只20种,如果你用着20量独特的车合成的照片去训练系统,那么你的神经网络很可能对这20辆车过拟合,但人类很难分辨出来。即使这些图像看起来很逼真,你可能真的只用了所有可能出现的车辆的很小的子集。
不幸的是,上一张幻灯片介绍的情况也会在这里出现,比如这是所有车的集合,如果你只合成这些车中很小的子集,对于人眼来说也许这样合成图像没什么问题,但你的学习算法可能会对合成的这一个小子集过拟合。特别是很多人都独立提出了一个想法,一旦你找到一个电脑游戏,里面车辆渲染的画面很逼真,那么就可以截图,得到数量巨大的汽车图片数据集。事实证明,如果你仔细观察一个视频游戏,如果这个游戏只有20辆独立的车,那么这游戏看起来还行。因为你是在游戏里开车,你只看到这20辆车,这个模拟看起来相当逼真。但现实世界里车辆的设计可不只20种,如果你用着20量独特的车合成的照片去训练系统,那么你的神经网络很可能对这20辆车过拟合,但人类很难分辨出来。即使这些图像看起来很逼真,你可能真的只用了所有可能出现的车辆的很小的子集。
所以,总而言之,如果你认为存在数据不匹配问题,我建议你做错误分析,或者看看训练集,或者看看开发集,试图找出,试图了解这两个数据分布到底有什么不同,然后看看是否有办法收集更多看起来像开发集的数据作训练。
我们谈到其中一种办法是人工数据合成,人工数据合成确实有效。在语音识别中。我已经看到人工数据合成显著提升了已经非常好的语音识别系统的表现,所以这是可行的。但当你使用人工数据合成时,一定要谨慎,要记住你有可能从所有可能性的空间只选了很小一部分去模拟数据。
