
E-MapReduce的用途
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
以往在使用Hadoop和Spark等分布式处理系统时,您通常需要执行如下步骤。 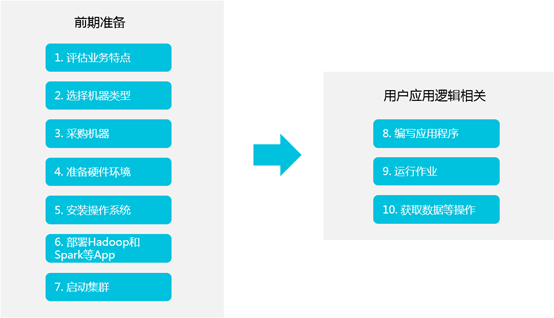
在上述使用流程中,真正跟用户的应用逻辑相关的是步骤8~10,而步骤1~7都是前期准备工作,但这些前期准备工作都非常冗长繁琐。E-MapReduce提供了集群管理工具的集成解决方案,例如,主机选型、环境部署、集群搭建、集群配置、集群运行、作业配置、作业运行、集群管理和性能监控等。通过E-MapReduce,您可以从繁琐的集群构建相关的采购、准备和运维等工作中解放出来,只关心自己应用程序的处理逻辑即可。 此外,E-MapReduce还为您提供了灵活的搭配组合方式,您可以根据自己的业务特点选择不同的集群服务。例如,如果您的需求是对数据进行日常统计和简单的批量运算,则可以只选择在E-MapReduce中运行Hadoop服务;如果您有流式计算和实时计算的需求,则可以在Hadoop服务基础上再加入Spark服务。
