
环境:scala 2.11.11,spark2.4,pmml
步骤描述:最近看了阿里PAI的产品,想仿照写一个小的例子。我定义了多个object class,每个class完成一种数据处理功能,然后输出一个新的文件提供给下一个class作为输入,从而完成一连串的数据转换及特征提取工作,最后输出文件用于决策树分类训练,从而得到训练模型。
问题:请问我该如何导出最终训练完的模型?如何只在决策树class中导出pmml模型,那么此pmml模型是不是不包含前面的一串数据处理方法?如果我部署此pmml模型,那么调用的时候是不是不能直接传入源数据?
如下图所示,每一个节点都是一个object class,需求是导出可通过输入原始数据做分类的模型
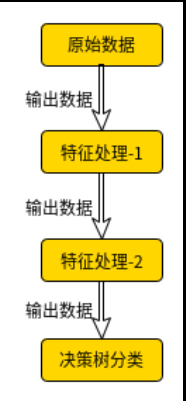
本人机器学习小白,谢谢帮助
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Scala和Spark进行机器学习模型训练,并希望导出为PMML(Predictive Model Markup Language)格式时,您需要确保所使用的库支持PMML导出。对于Spark MLlib,它本身并不直接支持PMML输出,但您可以借助第三方库如JPMML-Spark来实现这一需求。
添加依赖:首先,您需要在项目中加入JPMML-Spark的依赖,以便能够将Spark模型转换为PMML。在您的build.sbt或相应构建文件中添加如下依赖:
libraryDependencies += "org.jpmml" % "jpmml-sparkml_2.11" % "1.6.5"
注意版本号可能需要根据当前可用版本进行调整,并且确保与您的Scala版本匹配。
模型转换:在您的决策树模型训练完成后,使用JPMML-Spark库将模型转换为PMML格式。以下是一个简化的示例代码段:
import org.jpmml.sparkml._
// 假设dtModel是已经训练好的Spark决策树模型
val dtModel: DecisionTreeClassificationModel = ...
// 将Spark模型转换为PMML模型
val pmml = new SparkMLConverter().convert(dtModel)
// 将PMML模型保存到文件
pmml.save(new File("path/to/your/model.pmml"))
综上所述,虽然PMML模型本身不包括数据预处理逻辑,但通过确保在部署和调用模型时遵循相同的数据处理流程,仍然可以实现从原始数据到分类预测的整个工作流。
