分析型数据库支持多种数据入库方式,包括但不限于:
(1)内置将MaxCompute中的海量数据快速批量导入;
(2)支持标准的insert/delete语法,可使用用户程序、Kettle等第三方工具写入实时写入表;
(3)支持阿里云数据集成(CDP),将各类数据源导入批量导入表或实时写入表。阿里云大数据开发平台;
(4)支持阿里云数据传输(DTS),从阿里云RDS实时同步数据变更到分析型数据库。
本章节主要描述(1)和(3)两种数据导入方式,其余导入方式详见本手册第八章。
SQL方式将MaxCompute数据导入
分析型数据库目前内置支持从阿里云外售的MaxCompute(原ODPS)中导入数据。
将MaxCompute数据导入分析型数据库有几种方法:直接使用SQL命令进行导入,或通过MDS for AnalyticDB界面进行导入、通过数据集成(原CDP)配置job进行导入。
通过DMS for AnalyticDB界面导入数据已在《快速入门》进行了介绍;通过数据集成导入数据可以参考下一小章节。下面主要详细介绍通过SQL命令将MaxCompute数据导入AnalyticDB。
步骤一: 准备MaxCompute表或分区。
首先我们需要创建好数据源头的MaxCompute表(可以是分区表或非分区表,目前要求AnalyticDB中的字段名称和MaxCompute表中的字段名称一致),并在表中准备好要导入的数据。
如在MaxCompute中创建一个表:<PRE prettyprinted? linenums>
- use projecta;--在MaxCompute的某个project中创建表
- CREATE TABLE
- odps2ads_test (
- user_id bigint ,
- amt bigint ,
- num bigint ,
- cat_id bigint ,
- thedate bigint
- )
- PARTITIONED BY(dt STRING);
往表中导入数据并创建分区,如:dt=’20160808’。
步骤二:账号授权。
首次导入一个新的MaxCompute表时,需要在MaxCompute中将表Describe和Select权限授权给AnalyticDB的导入账号。公共云导入账号为
garuda_build@aliyun.com以及
garuda_data@aliyun.com(两个都需要授权)。各个专有云的导入账号名参照专有云的相关配置文档,一般为
test1000000009@aliyun.com。
授权命令:<PRE prettyprinted? linenums>
- USE projecta;--表所属ODPS project
- ADD USER ALIYUN$xxxx@aliyun.com;--输入正确的云账号
- GRANT Describe,Select ON TABLE table_name TO USER ALIYUN$xxxx@aliyun.com;--输入需要赋权的表和正确的云账号
另外为了保护用户的数据安全,AnalyticDB目前仅允许导入操作者为Proejct Owner的ODPS Project的数据,或者操作者为MaxCompute表的owner(大部分专有云无此限制)。
步骤三:准备AnalyticDB表,注意创建时更新方式属性为“批量更新”,同时把表的Load Data权限授权给导入操作者(一把表创建者都默认有该权限)。
如表:<PRE prettyprinted? linenums>
- CREATE TABLE db_name.odps2ads_test (
- user_id bigint,
- amt int,
- num int,
- cat_id int,
- thedate int,
- primary key (user_id)
- )
- PARTITION BY HASH KEY(user_id)
- PARTITION NUM 40
- TABLEGROUP group_name
- options (updateType='batch');
- --注意指定好数据库名和表组名
步骤四:在AnalyticDB中通过SQL命令导入数据。
语法格式:<PRE prettyprinted? linenums>
- LOAD DATA
- FROM 'sourcepath'
- [OVERWRITE] INTO TABLE tablename [PARTITION (partition_name,...)]
说明:
如果使用MaxCompute(原ODPS)数据源,则sourcepath为:<PRE prettyprinted? linenums>
-
odps://<project>/<table>/[<partition-1=v1>/.../<partition-n=vn>]
- ODPS项目名称 project 。
- ODPS表名 table 。
- ODPS分区 partition-n=vn ,可以是多级任意类型分区。
- 如果不指定则取当前时间(秒),格式是 yyyyMMddHHmss ,如 20140812080000。
覆盖导入选项( OVERWRITE ),导入时如果指定数据日期的表在分析型数据库线上已存在,则返回异常,除非显示指定覆盖。分析型数据库表名( tablename ),格式 table_schema.table_name ,其中 table_name 是分析型数据库表名, table_schema 是表所属DB名,表名不区分大小写。
PARTITION,分析型数据库表分区,分区格式 partition_column=partition_value ,其中 partition_column 是分区列名, partition_value 是分区值
- 分区值必须是 long 型;
- 分区值不存在时表示动态分区,例如第一级hash分区;
- 不区分大小写;
- 目前最多支持二级分区。
执行返回值: <jobId>(任务ID),
用于后续查询导入状态.任务ID是唯一标识该导入任务,返回的是字符串,最长256字节。
示例1:<PRE prettyprinted? linenums>
- LOAD DATA
- FROM 'odps://<project>/odps2ads_test/dt=20160808'
- INTO TABLE db_name.odps2ads_test
- --注意<project> 填写MaxCompute表所属的项目名称
示例2:
如果分析型数据库表有二级分区,也可指定导入到相应二级分区:<PRE prettyprinted? linenums>
- LOAD DATA
- FROM 'odps://<project>/odps2ads_test/dt=20160808'
- INTO TABLE db_name.odps2ads_test PARTITION(user_id, dt=20160808)
步骤五:查看导入状态(参见5.2章节)和成功导入的数据。
通过数据集成将RDS等其他数据源的数据导入
当表的数据源是RDS、OSS等其它的云系统,我们可以通过阿里云的数据集成产品进行数据同步。
批量更新表导入
专有云上批量导入
专有云上可以通过
大数据开发套件的数据集成任务里的数据同步进行操作,数据同步任务即通过封装数据集成实现数据导入。具体步骤请看“大数据开发套件”的用户指南相关数据源配置和数据同步任务配置章节。
前提条件:
- 分析型数据库目标表更新方式是“批量更新”。
- 在分析型数据库中给MaxCompute的base_meta这个project的owner账号至少授予表的Load Data权限,base_meta的owner账号信息可以在CMDB中查到。
注意“大数据开发套件”中数据集成同步任务目标为ads数据源的“导入模式”配置项需要选择“批量导入”。
公共云上批量导入
公共云上可在
http://www.aliyun.com/product/cdp/ 上开通数据集成(可能需要申请公测),
前提条件:
- 分析型数据库目标表更新方式是“批量更新”。
- 在分析型数据库中给cloud-data-pipeline@aliyun-inner.com这个账号至少授予表的Load Data权限。
配置下面的数据同步任务,准备工作要添加相应的数据源,添加各种数据源详细信息可以参考下面的文档:
数据源配置
向导模式配置同任务
下面以mysql同步到ads为例:
- 新建同步任务,如下图所示:
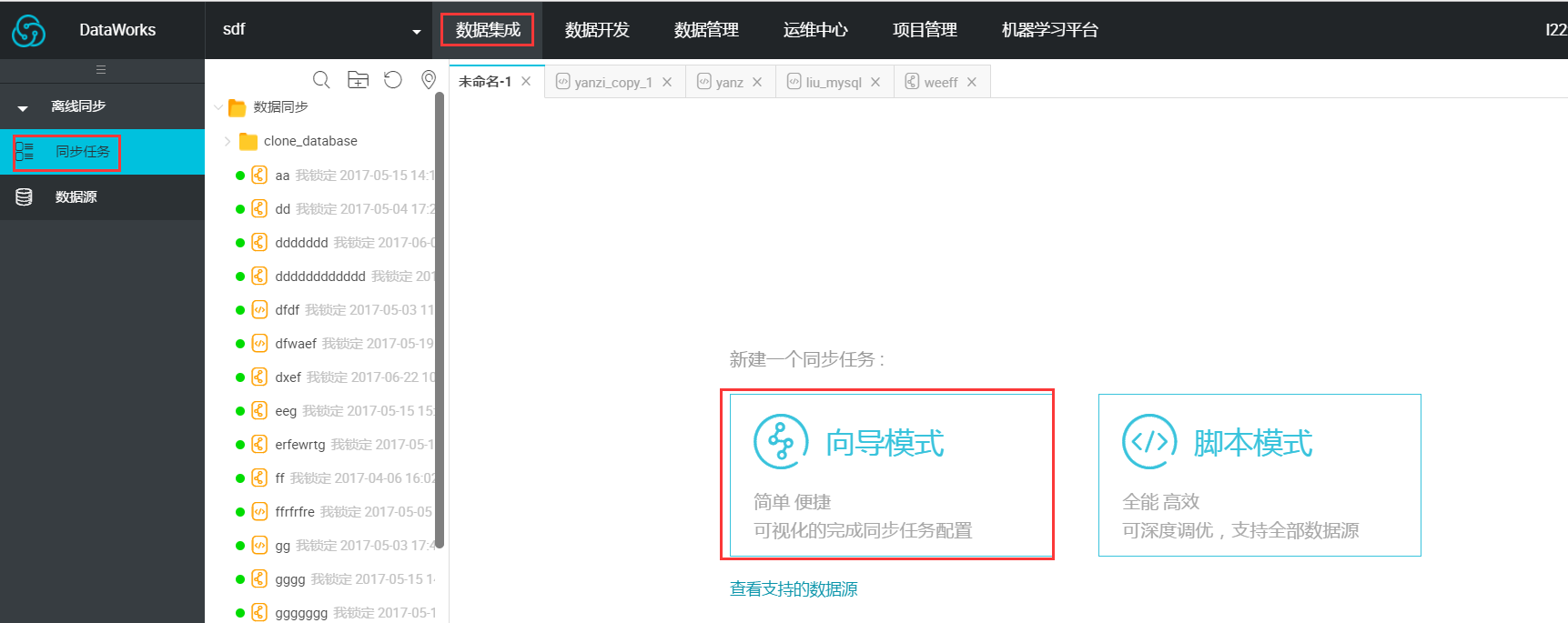
- 选择来源: 选择mysql数据源及源头表emp,数据浏览默认是收起的,选择后点击下一步,如下图所示:
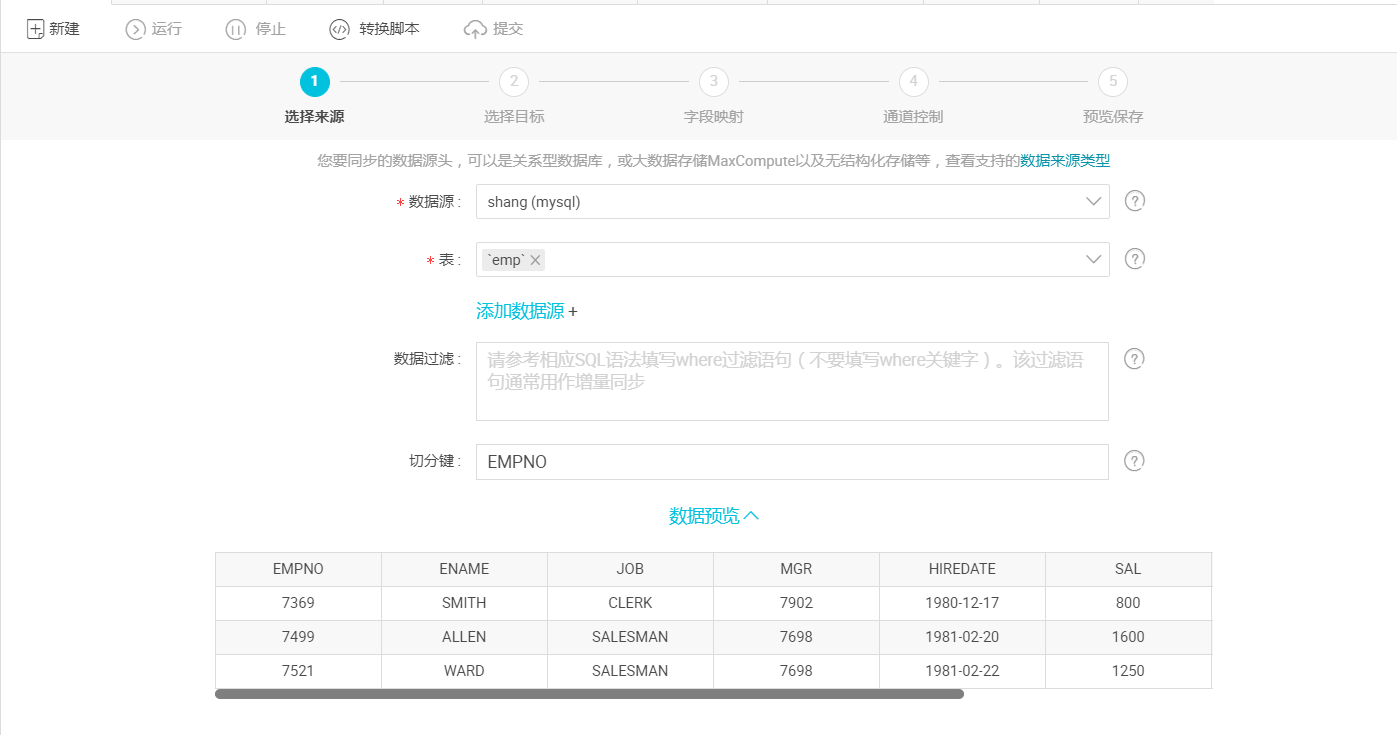
- 选择目标:选择ads数据源及目标表emp,选择后点击下一步,如下图所示:
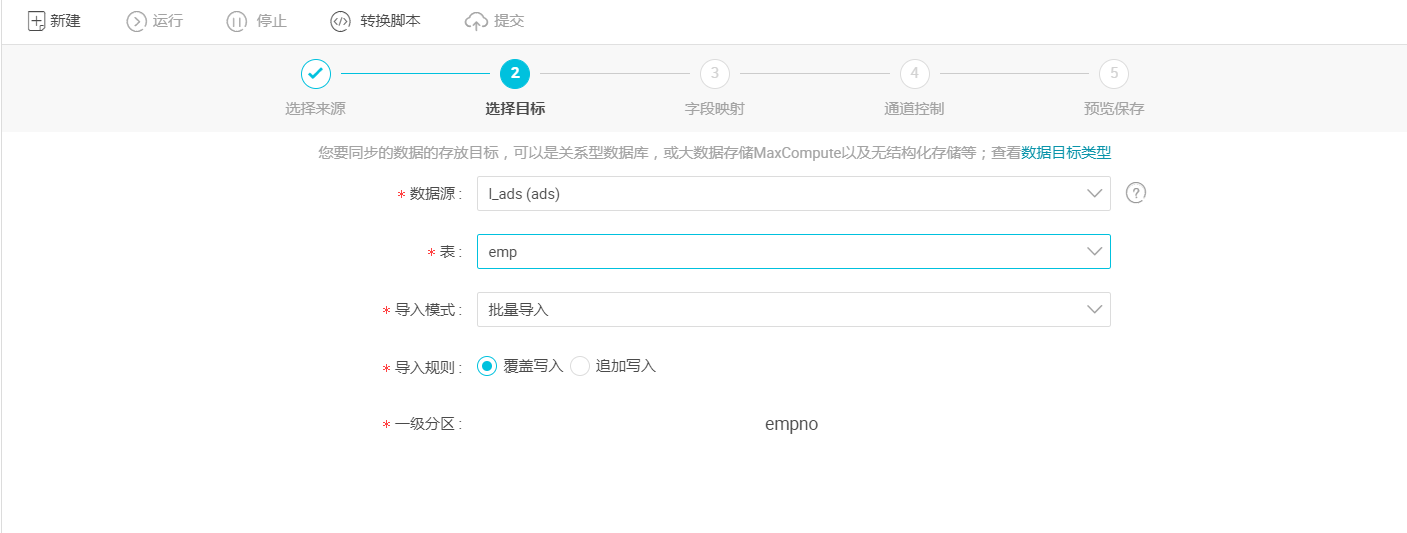
- 导入模式:即上述参数说明中的“writeMode”,支持Load Data(批量导入)和Insert Ignore(实时插入)两种模式。
清理规则:
1)写入前清理已有数据:导数据之前,清空表或者分区的所有数据,相当于 insert overwrite 。
2)写入前保留已有数据:导数据之前不清理任何数据,每次运行数据都是追加进去的,相当于 insert into 。
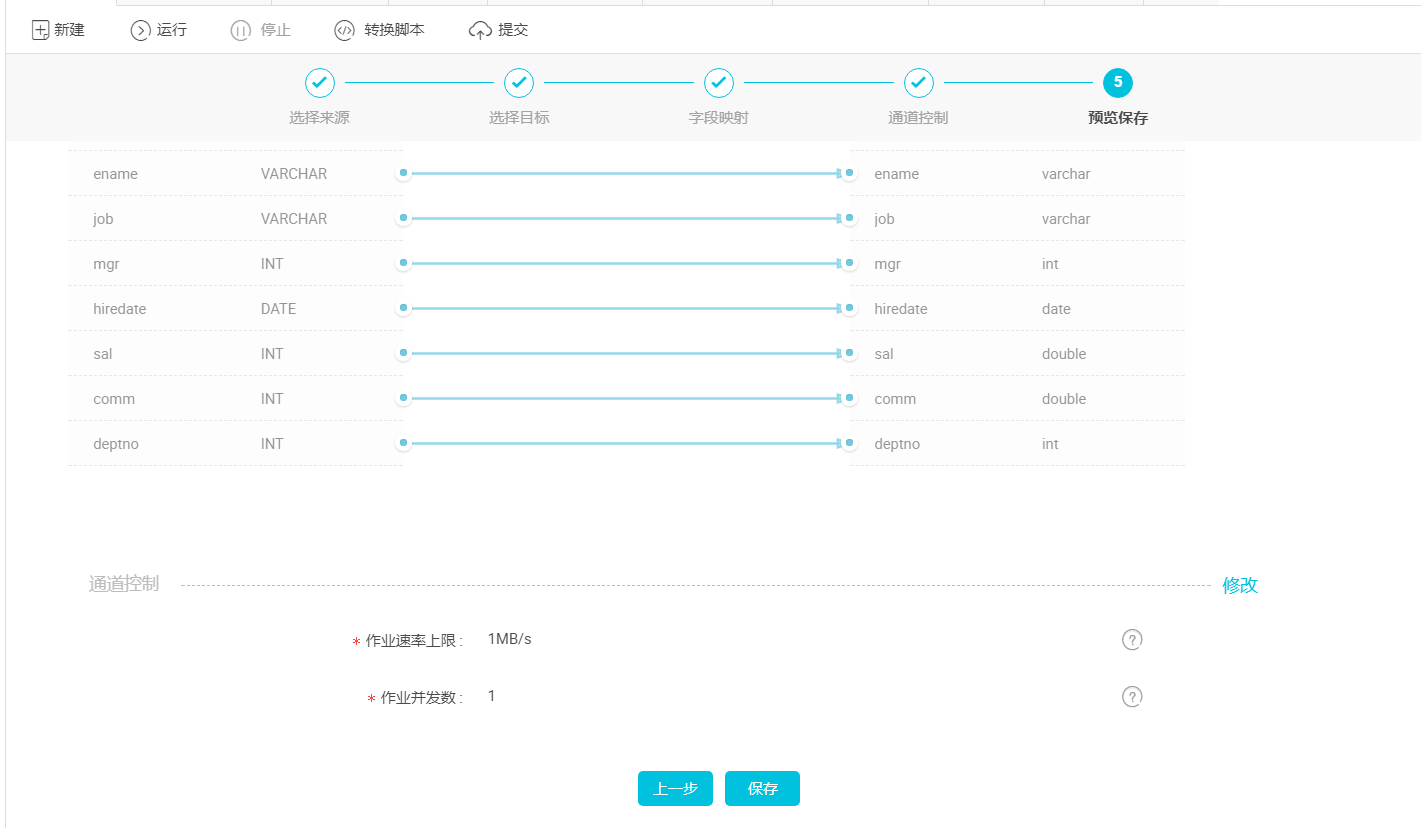
4.映射字段:点击下一步,选择字段的映射关系。需对字段映射关系进行配置,左侧“源头表字段”和右侧“目标表字段”为一一对应的关系 ,如下图所示。

- 通道控制点击下一步,配置作业速率上限和脏数据检查规则,如下图所示:
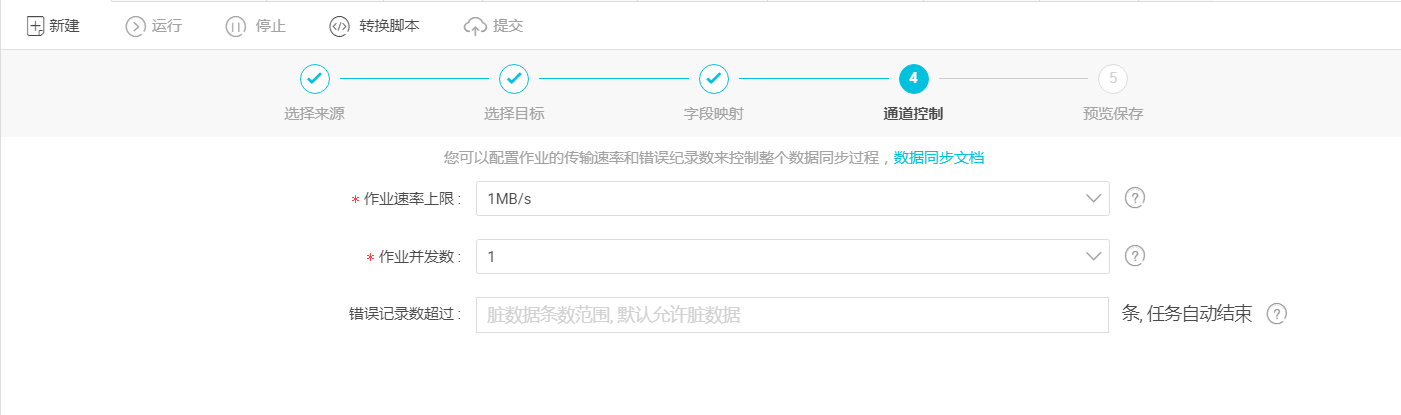
作业速率上限:是指数据同步作业可能达到的最高速率,其最终实际速率受网络环境、数据库配置等的影响。
作业并发数:
从单同步作业来看:作业并发数*单并发的传输速率=作业传输总速率;
当作业速率上限已选定的情况下,应该如何选择作业并发数?
① 如果你的数据源是线上的业务库,建议您不要将并发数设置过大,以防对线上库造成影响;
② 如果您对数据同步速率特别在意,建议您选择最大作业速率上限和较大的作业并发数
- 预览保存:完成以上配置后,上下滚动鼠标可查看任务配置,如若无误,点击保存,如下图所示:
脚本模式配置同步任务
mysql同步到ads任务配置示例:<PRE prettyprinted? linenums>
- {
- "type": "job",
- "version": "1.0",
- "configuration": {
- "setting": {
- "errorLimit": {
- "record": "0"
- },
- "speed": {
- "mbps": "1",//一个并发的速率上线是1MB/S
- "concurrent": "1"//并发的数目
- }
- }
- },
- "reader": {
- "plugin": "mysql",
- "parameter": {
- "datasource": "xxx",//数据源名,建议数据源都添加数据源后进行同步任务
- "table": "k",//mysql源端表名
- "splitPk": "id",//切分键:源数据表中某一列作为切分键,切分之后可进行并发数据同步,目前仅支持整型字段;建议使用主键或有索引的列作为切分键
- "column": [
- "int"
- ],//列名
- "where": "id>100"请参考相应的SQL语法填写where过滤语句(不需要填写where关键字)该过滤 语句通常作为增量同步
- }
- },
- "writer": {
- "plugin": "ads",
- "parameter": {
- "datasource": "yyy",//数据源名,建议数据源都添加数据源后进行同步任务
- "table": "dd1",//ads目标表名
- "partition": "id",//分区
- "overWrite": "true",//写入规则
- "batchSize": "256",//同步的批量大小
- "writeMode": "load",//写入模式load
- "column": [
- "*"
- ]
- }
- }
- }
- }
其他的数据源跟ads之间的同步,可以参考
脚本模式各数据源的reader配置里的文档。
其他数据导入方式
用户亦可利用阿里云数据传输(DTS)进行RDS到分析型数据库的实时数据同步(请参照手册第八章的相关内容)。
分析型数据库亦兼容通过kettle等第三方工具,或用户自行编写的程序将数据导入/写入实时写入表。
另外,分析型数据库进行实时插入和删除时,不支持事务,并且仅遵循最终一致性的设计,所以分析型数据库并不能作为OLTP系统使用。

