概念说明
如上文所说,标签中心的作用是在现有的数据表之上构建跨计算存储的逻辑模型,直接让用户在视图层上对数据进行管理、加工、查询,屏蔽下层的多个大数据计算存储资源,简化数据的使用。当整个数据架构越复杂,越是需要多个计算存储资源组合使用的场景下,标签中心的价值就越为明显。
标签建模的方法来源于阿里巴巴用户画像体系,广泛应用于精准营销、个性化推荐、用户画像、信用评分等需要基于明细数据进行计算的大数据应用当中。所谓标签就是对用户这一对象的一个最小描述单元,代表着所描述对象某一个具体的客观事实的抽象表达,如属性(性别 标签值男、女、年龄 标签值实际年龄),行为(成交金额、收藏次数、位置定位),或者是兴趣(对于多个关键词的偏好度),是一种以业务视角出发的数据建模方法,标签既可能是数值、也可能是枚举值,也可以是多个Key-Value组织的列,还可能是多字段组成的事实表(如对象、时间、谓语、宾语)。从概念模型上讲,标签体系就是围绕多个实体对象,如买家卖家商品企业设备,以及实体之间的关系,如成交检修位于等等,建立标签化描述的方法。
这种建模方式看起来可能类似于角模型(Anchor)或者是图模型(Graph),其实并不然。传统的建模过程是根据业务需求设计概念和逻辑模型,再根据逻辑模型对物理数据表进行加工和规整。而标签建模是在已有的物理数据/模型之上直接建立逻辑模型,通过各个数据服务的代理解析,让用户可以在视图上直接进行各类的计算,不需要预先对物理数据进行大规模的加工处理,即用即算。
但需要明确的是,总体来说,标签仍然是建立在物化数据之上,因为在跨计算的语境之下可能会面临多个计算的查询语言和性能的差异,建立在逻辑请求上的标签很可能会无法执行,所以总体来讲定义的每一个标签还是需要对应到落地的物理表上。但在DTBoost当中,可以在相应的数据服务当中以某一个计算查询逻辑定义为一个临时标签使用,但关系到跨计算之时还是需要将之物化,避免错误发生的可能。
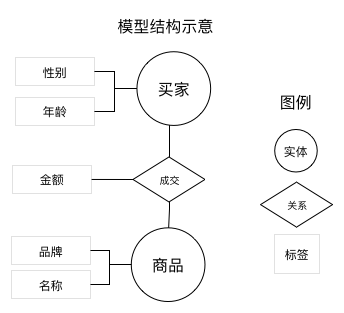
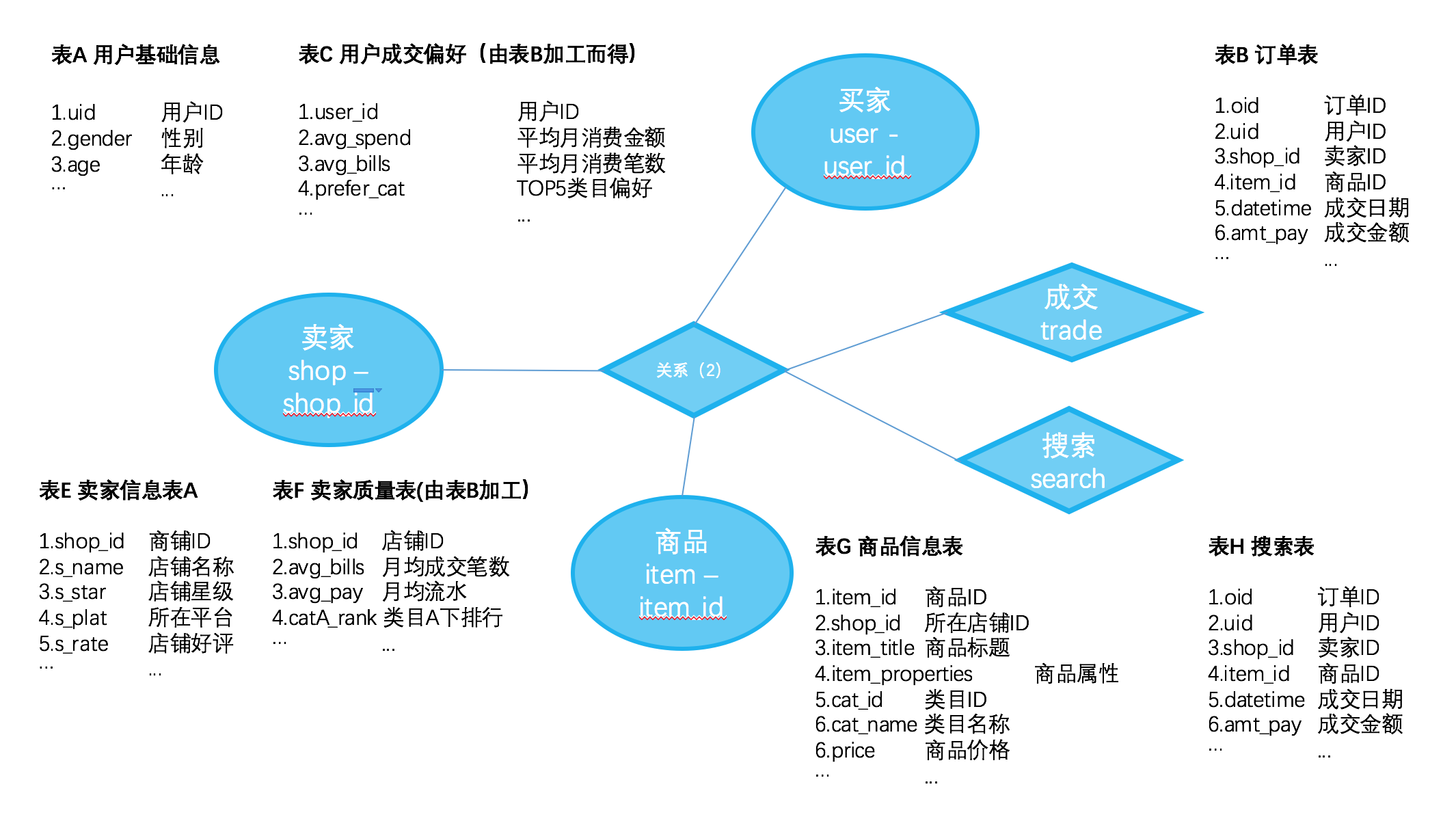
标签模型v2.0是围绕实体(Object)、关系(Link)、标签(Tag)三大元素对分布在不同数据库中的数据进行网络化的建模方式。实体用于描述某个客观的对象,如设备人员地址等,对应到物理数据表上一般就是属性表,有一个主键来代表每一个对象,剩下的每一列就是标签即描述对象的属性。那么关系是表示对象和对象之间的联系、事件、行为,一般对应到物理数据表上一般就是事实流水表,如成交检修乘车等。
相比于指标-维度体系,这种建模方式更适用于对于明细数据描述和表达。明细数据很大一部分都是事实表,引入关系的概念对应到流水事实表上,把多个实体之间的关系很好的呈现表达,既有利于管理也方便分析时的表达,在对业务端呈现上也更接近于概念模型的设计一样可被一般人理解。
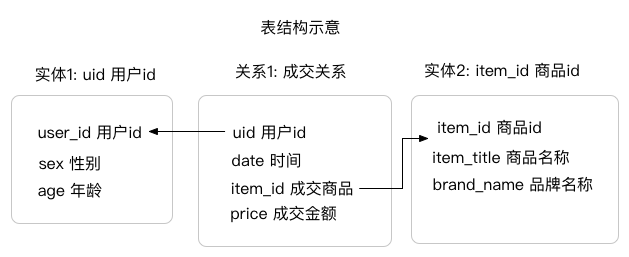
在经过建模转化之后,可以将上表中的模型逻辑关系转化为下图所示。成交表对应到关系结点上,金额和时间是关系上的标签,用户表和商品表对应到买家和商品两个实体上,性别、年龄是买家的标签。这种建模方式非常便于各类基于明细行为、关系数据进行分析的场景。
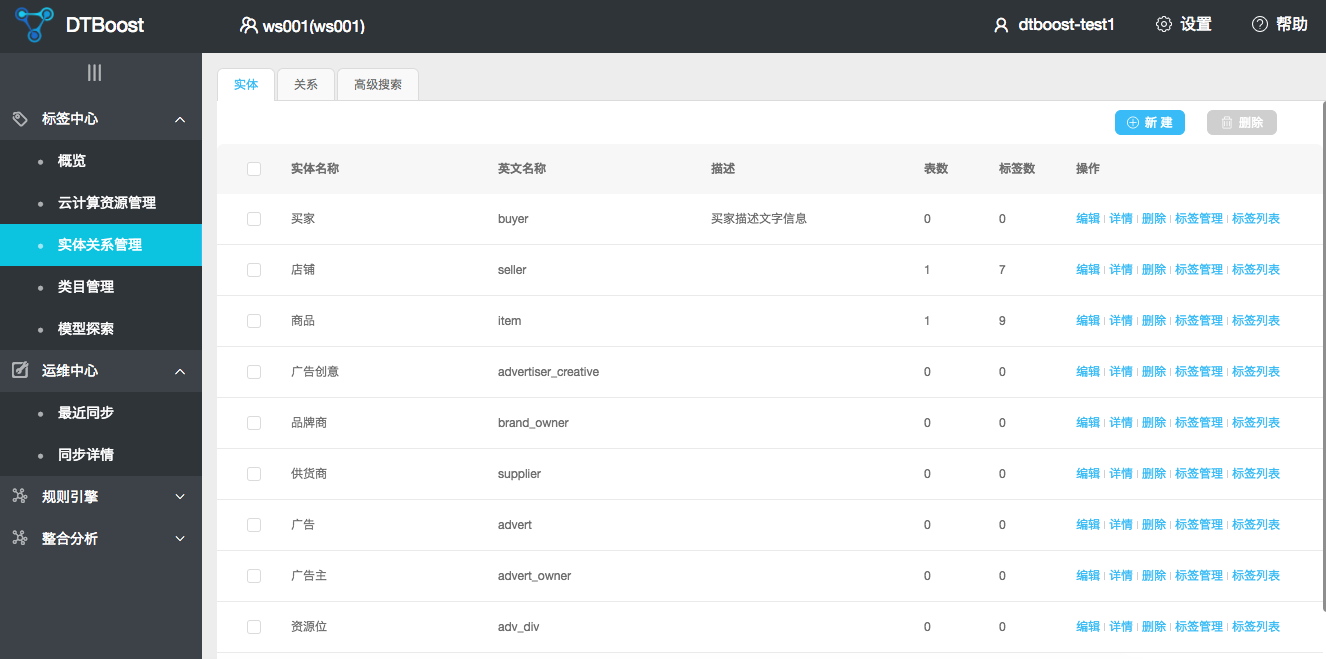
您可以在标签中心页面下看到标签中心的几大功能:包括了模型管理、云计算资源管理和模型探索
适用场景
如上文所述,标签中心是跨计算存储、可在物理模型之上逻辑动态建模、与数据服务结合面向大数据应用开发的数据建模、数据管理工具,并能够通过可视化的方法清晰的展现企业的数据模型视图。
数据模型探索管理标签中心提供一种业务视角的数据发现、模型探索的工具,便于业务人员、开发人员、数据管理人员透视企业的数据资产。
为数据服务提供视图支撑为多个计算引擎上的数据提供一个统一的数据视图,结合数据服务能够方便的进行业务逻辑计算操作
数据权限管理可以通过逻辑层对数据访问权限进行有效控制,比物理表的访问管理更加安全有效
功能模块
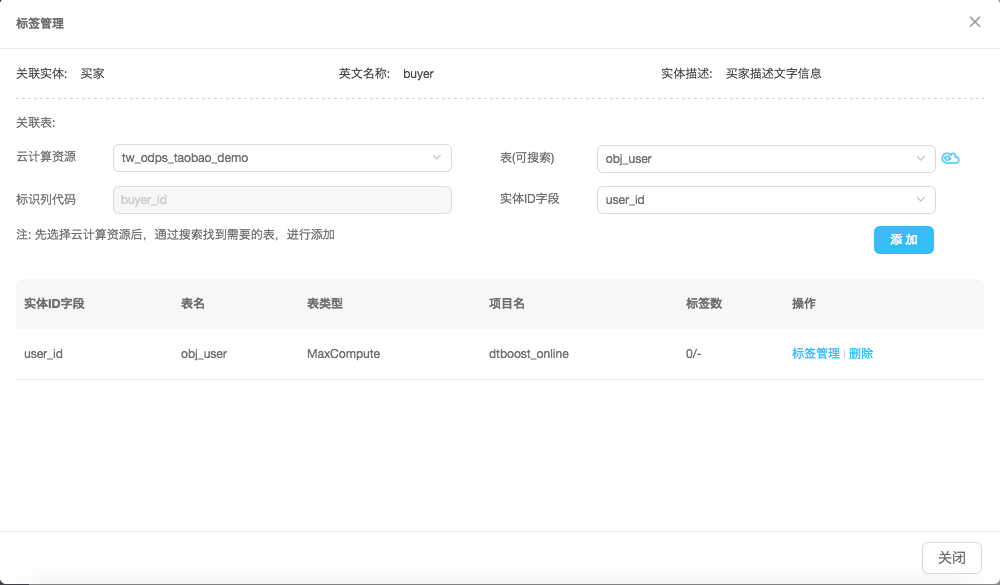
云计算资源管理
云计算资源管理就是支撑与多个计算存储资源通信,与元信息获取的基本功能模块。目前DTBoost支持与以下计算存储资源的管理:
- 阿里云关系型数据库(RDS)
- 阿里云大数据计算(MaxCompute)
- 阿里云分析型数据库(AnalyticDB)
- 阿里云表格存储(TableStore)
- 阿里云数据中枢(DataHub)
- 阿里云流式计算(StreamCompute)
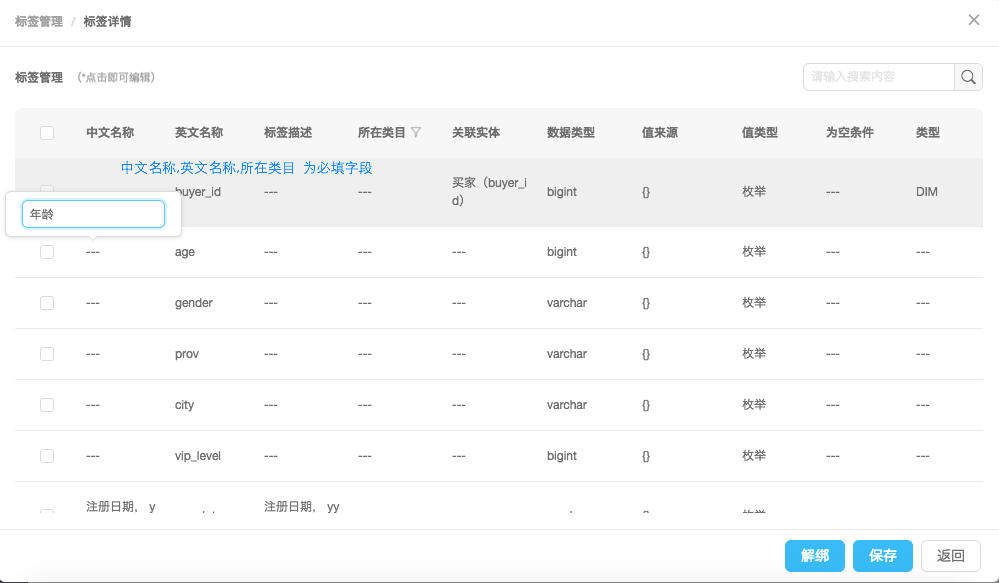
模型管理
模型探索与数据订阅
模型探索部分可以通过关系图的方式查看所有的实体,实体与实体之间的联通关系及其属性,以及实体/关系下关联的标签情况。通过模型探索可以对整个标签模型进行全局的分析查看。
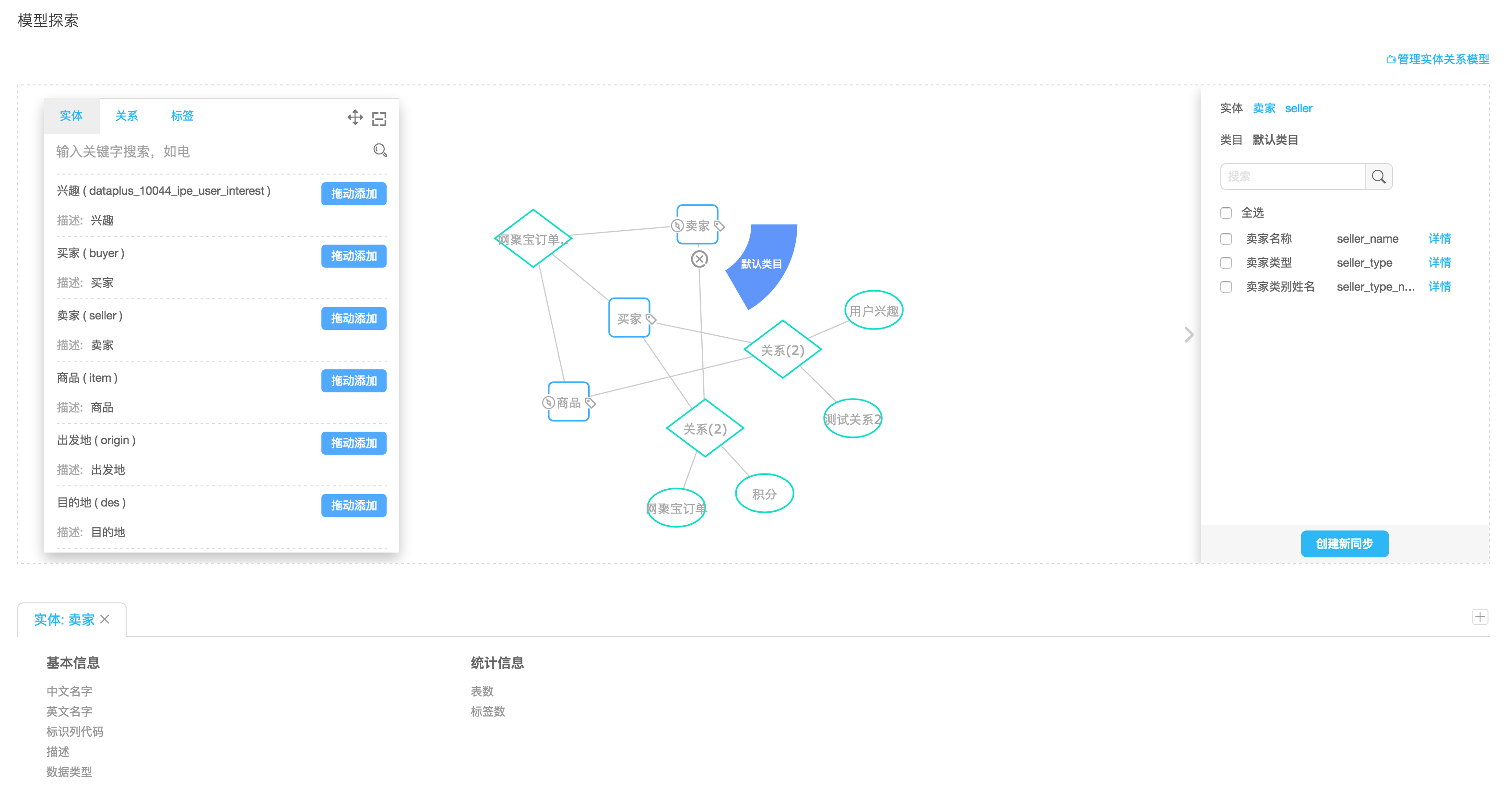
标签数据订阅是DTBoost处理跨计算数据流转的重要功能之一。在相应的数据服务需要使用到数据的时候,标签中心提供了将分散在多个存储当中的数据订阅至数据服务需要计算的位置的功能。对于同步且相应时间要求高的场景来说,需要用户在相应的数据服务当中进行提前的手工订阅操作,对于异步或者请求相应要求不高的同步的计算场景来说,这个订阅过程对于用户来说透明。
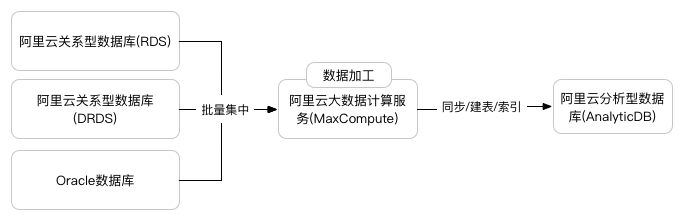
智能搬运内置了针对几套典型的架构路径
• 对于整合分析这类OLAP/ADHOC场景来说,提供了将Oracle, 关系型数据库(MySQL)等业务库中的数据同步至大数据计算(MaxCompute)中,再订阅到所使用的分析库当中(阿里云分析型数据库(AnalyticDB),关系型数据库(RDS)等)
• 对于规则引擎这类流式计算的场景来说,提供了将离线数据、流式数据进行归并,将规则所需要的离线历史数据订阅至阿里云表格存储当中,并根据规则计算结果订阅至所需要的存储计算资源当中(MySQL/MaxCompute/AnalyticDB等)
• 对于目前尚未以标准方式提供的订阅路径,可以进行相应的定制
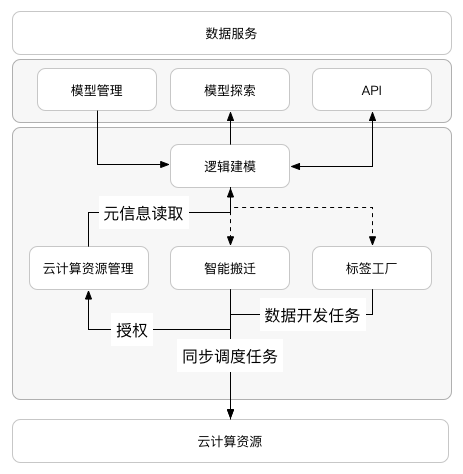
技术架构
产品特性
对于这种数据体系的规划上来说,往往是由业务驱动的,是累积增加的,随着不同的业务板块的开展会逐渐纳入更多的数据源。如果按照传统数据仓库的做法会面临几个问题:
- 其一、需要不断地在物理层进行数据表的归并,下层表的频繁变化可能会造成数据使用的不稳定;
- 其二、当标签的需求越来越多,因为不可能无限制的在物理层将数据拼在一张宽表当中,那分散的数据表也会越来越多,会造成检索和管理的困难。
- 其三、在不同的应用当中不可能是整表使用,往往是需要多张表中的某几列,那多个应用不断的抽取再整合也会造成管理和检索的困难。
- 其四、标签可能是实时数据、也有可能是离线数据,数据存储方式不同同样造成管理使用的困难;
由此,标签体系建模和传统BI分析建模有几大特性
业务视角管理
围绕实体-关系-标签这三个元素进行建模,是从业务的角度出发对数据进行组织管理,而不是从表的概念出发进行建模,便于应用层对数据运用和管理的理解、操作,以近似于概念模型的形态透出,让人人都能看得懂。
跨计算的统一逻辑模型
传统建模的数据来源和模型的使用一般在同一数据库当中,而大数据环境下因为数据采集类型的多样性,和数据计算的多样性使得来源和使用分散在不同的计算存储资源当中,数据产生与加工首先就可能分布在不同的数据库当中,其次同一份数据需要进行跨流式、Adhoc类多维分析、离线算法加工等多种方式的计算,数据需要能在多个存储和计算资源当中自由流转。
所以标签体系是把多个计算当中的拷贝在逻辑视图上进行唯一映射,即一个标签对应到多个计算当中的物理字段。
灵活拓展性
呈上,表/标签之间的逻辑关系的建立也是在逻辑层上完成的,这就使得模型的维护是可以动态建设的,便于模型的维护和管理,而无需在物理层将数据进行归并后再使用。每一个标签之间可以独立使用,这种离散的列化操作方式也使的数据的使用上更为灵活。
从另一方面来说,计算能力的增强和数据使用场景的丰富,更多的数据计算是需要直接作用在明细的行为数据上,而非只是对指标的多维统计。传统数据集市建模的“指标-维度”体系就略显狭窄。标签的定义上涵盖了多种数值类型,既可以是单列,也可以是维度+标签组成的复合标签(这种方式通常用于描述某种行为),赋予应用操作上更大的灵活度。