在 Hive 中使用 OSS
要在 Hive 中读写 OSS,需要在使用 OSS 的 URI 时加上 AccessKeyId、AccessKeySecret 以及endpoint。如下示例介绍了如何创建一个 external 的表:
- CREATE EXTERNAL TABLE eusers (
- userid INT)
- LOCATION 'oss://emr/users';
为了保证能正确访问 OSS,这个时候需要修改这个 OSS URI 为:
- CREATE EXTERNAL TABLE eusers (
- userid INT)
- LOCATION 'oss://${AccessKeyId}:${AccessKeySecret}@${bucket}.${endpoint}/users';
参数说明:
${accessKeyId}:您账号的 accessKeyId。
${accessKeySecret}:该 accessKeyId 对应的密钥。
${endpoint}:访问 OSS 使用的网络,由您集群所在的 region 决定,对应的 OSS也需要是在集群对应的 region。
具体的值参考
OSS Endpoint
使用Tez作为计算引擎
从E-MapReduce产品版本2.1.0+开始,引入了Tez,Tez是一个用来优化处理复杂DAG调度任务的计算框架。在很多场景下可以有效的提高Hive作业的运行速度。
用户在作业中,可以通过设置Tez作为执行引擎来优化作业,如下:
- set hive.execution.engine=tez
示例 1
请参见如下步骤:
编写如下脚本,保存为 hiveSample1.sql,并上传到 OSS 上。 USE DEFAULT;- set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- set hive.stats.autogather=false;
- DROP TABLE emrusers;
- CREATE EXTERNAL TABLE emrusers (
- userid INT,
- movieid INT,
- rating INT,
- unixtime STRING )
- ROW FORMAT DELIMITED
- FIELDS TERMINATED BY '\t'
- STORED AS TEXTFILE
- LOCATION 'oss://${AccessKeyId}:${AccessKeySecret}@${bucket}.${endpoint}/yourpath';
- SELECT COUNT(*) FROM emrusers;
- SELECT * from emrusers limit 100;
- SELECT movieid,count(userid) as usercount from emrusers group by movieid order by usercount desc limit 50;
测试用数据资源。您可通过下面的地址下载 Hive 作业需要的资源,然后将其放到您 OSS 对应的目录下。
资源下载:
公共测试数据
创建作业。在 E-MapReduce 中新建一个作业,使用类似如下的参数配置:
- -f ossref://${bucket}/yourpath/hiveSample1.sql
这里的 ${bucket} 是您的一个 OSS bucket,yourPath 是这个 bucket 上的一个路径,需要您填写实际保存 Hive脚本的位置。
创建执行计划并运行。创建一个执行计划,您可以关联一个已有的集群,也可以自动按需创建一个,然后关联上这个作业。请将作业保存为“手动运行”,回到界面上就可以点击“立即运行”来运行作业了。
示例 2
以
HiBench 中的 scan为例,若输入输出来自 OSS,则需进行如下过程运行 Hive 作业,代码修改源于 AccessKeyId、AccessKeySecret以及存储路径的设置。请注意 OSS 路径的设置形式为oss://${accesskeyId}:${accessKeySecret}@${bucket}.${endpoint}/object/path。
请参见如下操作步骤:
编写如下脚本。 USE DEFAULT;- set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
- set mapreduce.job.maps=12;
- set mapreduce.job.reduces=6;
- set hive.stats.autogather=false;
- DROP TABLE uservisits;
- CREATE EXTERNAL TABLE uservisits (sourceIP STRING,destURL STRING,visitDate STRING,adRevenue DOUBLE,userAgent STRING,countryCode STRING,languageCode STRING,searchWord STRING,duration INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS SEQUENCEFILE LOCATION 'oss://${AccessKeyId}:${AccessKeySecret}@${bucket}.${endpoint}/sample-data/hive/Scan/Input/uservisits';
准备测试数据。您可通过下面的地址下载作业需要的资源,然后将其放到您 OSS 对应的目录下。
资源下载:
uservisits
创建作业。将步骤 1 中编写的脚本存储到 OSS 中,假设存储路径为oss://emr/jars/scan.hive,在E-MapReduce 中创建如下作业:
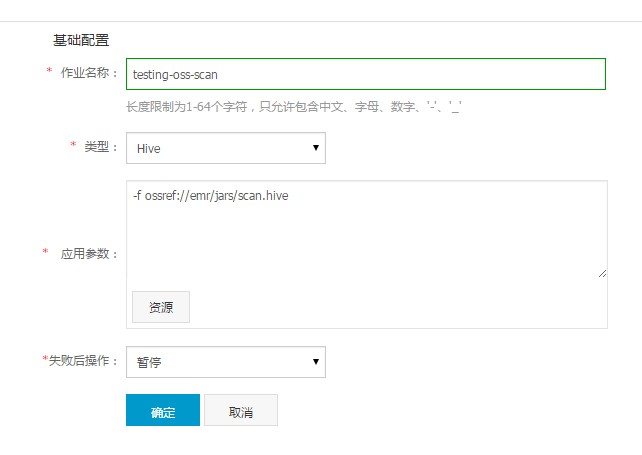
创建执行计划并运行。创建一个执行计划,您可以关联一个已有的集群,也可以自动按需创建一个,然后关联上这个作业。请将作为保存为“手动运行”,回到界面上就可以点击“立即运行”来运行作业了。

