
简介
MapStruct是用于生成类型安全的bean映射类的Java注解处理器。
你所要做的就是定义一个映射器接口,声明任何需要映射的方法。在编译过程中,MapStruct将生成该接口的实现。此实现使用纯Java的方法调用源对象和目标对象之间进行映射,并非Java反射机制。
与手工编写映射代码相比,MapStruct通过生成冗长且容易出错的代码来节省时间。在配置方法的约定之后,MapStruct使用了合理的默认值,但在配置或实现特殊行为时将不再适用。
与动态映射框架相比,MapStruct具有以下优点:
- 使用纯Java方法代替Java反射机制快速执行
- 编译时类型安全:只能映射彼此的对象和属性,不能映射一个Order实体到一个Customer DTO中等等
- 如果无法映射实体或属性,则在编译时清除错误报告
原理
MapStruct是基于JSR 269的Java注解处理器,因此可以在命令行构建中使用(javac、Ant、Maven等等),也可以在IDE内使用。
它包括以下工件:
- org.mapstruct:mapstruct:包含了必要的注解,例如@Mapping;在Java 8或更高版本中,使用org.mapstruct:mapstruct-jdk8,而不是利用Java 8中引入的语言进行改进。
- org.mapstruct:mapstruct-processor:包含生成映射器实现的注解处理器
在使用过程中需要只需要配置完成后运行 mvn compile就会发现 target文件夹中生成了一个mapper接口的实现类。打开实现类会发现实体类中自动生成了字段一一对应的get、set方法的文件。
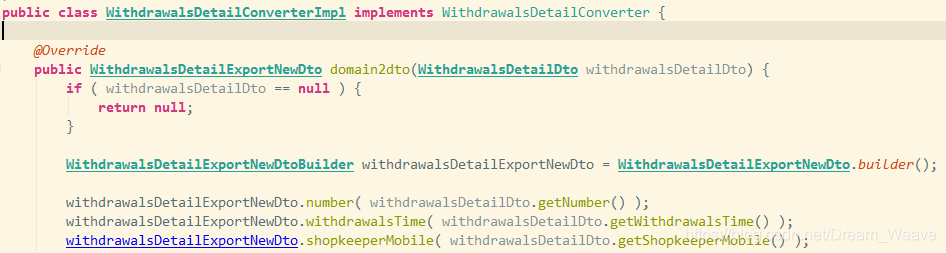
这就是为什么mapstruct的效率比较高的原因,相比于反射获取对象进行拷贝的方法,这种更贴近于原生get、set方法的框架显得更为高效。
这个文件是通过在mapper中的注解,使用生成映射器的注解处理器从而自动生成了这段代码。
看到这里是不是感觉JSR 269注解处理器很熟悉。确实在很多地方都是用到了他,在我之前了解lombok原理时也看到他的身影。那么总让我在这里好好介绍一下他。
注解处理器
1. Java代码编译过程
Java代码编译和执行的整个过程包含了以下三个重要的机制:1)Java源码编译机制;2)类加载机制;3)类执行机制
其中,Java源码编译由以下三个过程组成:1)分析和输入到符号表;2)注解处理;3)语义分析和生成class文件
流程图如下所示:

其中的annotation processing就是代码的注解处理,jdk7之前访问和处理Annotation的工具统称APT(Annotation Processing Tool)(jdk7后就被废除了),jdk7及之后采用了JSR 269 API。
2. 注解处理器的作用
Annotation就像代码里的特殊标记,这些标记可以在编译、类加载、运行时被读取。读取到了程序元素的元数据,就可以执行相应的处理。通过注解,程序开发人员可以在不改变原有逻辑的情况下,在源代码文件中嵌入一些补充信息。代码分析工具、开发工具和部署工具可以通过解析这些注解获取到这些补充信息,从而进行验证或者进行部署等。
接下来回头来理解lombok通过添加注解来标识实体类,在源码编译的过程中告诉注解处理器这里需要添加get、set方法就很顺理成章了。
