
四、多线程请求信息
此处感谢明佬的指导,省了不少麻烦事@小小明-代码实体
首先介绍一下ThreadPoolExecutor线程库:
导入:
from concurrent.futures import ThreadPoolExecutor
创建线程库:
with ThreadPoolExecutor(max_workers=10) as executor:
按照次序返回结果,并接收:
nums = executor.map(chaxun, df.力扣主页.str.extract( r"leetcode-cn.com/u/([^/]+)(?:/|$)", expand=False))
其中第二个参数就是传入的参数列表,并且.map可以按照输入顺序进行输出。
我们只要将返回的nums转化为list就可以按之前的顺序得到结果。
整体函数:
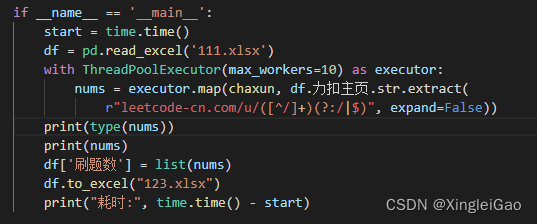


耗时:>得到的结果
五、web前端的书写
此处万分感谢明佬的辛勤劳动:@小小明-代码实体
pandas默认是可以直接生成html的文件的,我们稍加修饰就好了
1.默认的生成结果:

2.改变为整行的颜色显示
查看生成的样式表,我们需要把对应的值改掉#T_18e34_row0_col3变成.row0

利用正则表达式进行替换(这里我真的没看懂,还是求救的明佬,明佬yyds!!!)


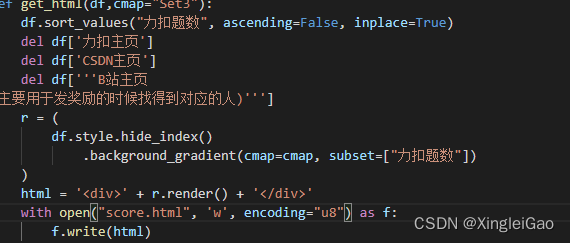
3.完善样式表
最后再加入自己想要定制的显示方式然后返回对应的html信息就好了。

六、其他补充
1.CSRF的获取
requests可以直接获取一个cookie,我们可以从cookies中提取出来 def int_csrf(): global headers sess= requests.session() sess.head("https://leetcode-cn.com/graphql/") headers['x-csrftoken'] = sess.cookies["csrftoken"]
2.web服务器直接写入静态页面地址

可以直接写入对应网页的根目录直接访问,效果可以看手机版万人千题刷题榜单
3.电脑端的呈现页面
电脑和手机的分辨率不同,所以导致显示效果不同,就单独做了一些PC端的页面,使用内嵌的方式来进行数据的浏览。其实就是用ifame做嵌套,做了缩放。
<style> .iframe-body-sty{position: relative;overflow: hidden;height:700px;width: 500px;background-color:#FFF;} .iframe-body-sty>#iframe-shrink{position: absolute;transform:scale(0.43);left: -620px;top: -550px;height:1900px;max-width:1600px;width: 1600px;} </style> <div class="iframe-body-sty"> <iframe id="iframe-shrink" src="https://www.xingleigao.top/score.html"></iframe> </div>
最终效果可以看:PC端万人千题刷题榜单
4.数据的定时更新
利用sh进行对应的操作
cd /home/leetcode date >> log.txt python3 leetcode.py >> log.txt 2>&1
利用cron进行定时任务
crontab -e
七、写在最后
这次的整个优化流程还算是比较顺利,其中也学到了很多东西,算是从一个啥也不懂的小白写出来的。如有问题还请大家批评指正。奉上完整代码:
""" 兴磊的代码 CSDN主页:https://blog.csdn.net/qq_17593855 """ __author__ = '兴磊' __time__ = '2022/1/27' import pandas as pd import re import time from urllib.parse import urlencode import requests import json from concurrent.futures import ThreadPoolExecutor headers={ "x-csrftoken":'', "Referer":"https://leetcode-cn.com", } utf = ''' <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> </head> <script> var _hmt = _hmt || []; (function() { var hm = document.createElement("script"); hm.src = "https://hm.baidu.com/hm.js?f114c8d036eda9fc450e6cbc06a31ebc"; var s = document.getElementsByTagName("script")[0]; s.parentNode.insertBefore(hm, s); })(); </script> ''' payload = {"operation_name": "userPublicProfile", "query": '''query userPublicProfile($userSlug: String!) { userProfilePublicProfile(userSlug: $userSlug) { submissionProgress { acTotal } } } ''', "variables": '{"userSlug":"kingley"}' } def int_csrf(): global headers sess= requests.session() sess.head("https://leetcode-cn.com/graphql/") headers['x-csrftoken'] = sess.cookies["csrftoken"] def chaxun(username): payload['variables'] = json.dumps({"userSlug" : f"{username}"}) res= requests.post("https://leetcode-cn.com/graphql/"+"?"+urlencode(payload),headers = headers) if res.status_code != 200: return -1 return res.json()['data']['userProfilePublicProfile']['submissionProgress']['acTotal'] def get_html(df,cmap="Set3"): df.sort_values("力扣题数", ascending=False, inplace=True) del df['力扣主页'] del df['CSDN主页'] del df['''B站主页 (主要用于发奖励的时候找得到对应的人)'''] r = ( df.style.hide_index() .background_gradient(cmap=cmap, subset=["力扣题数"]) ) #print(r.render()) html = '<div>' + r.render() + '</div>' html = re.sub("#T_.+?(row\d+)_col\d+", r".\1", html) with open("style.css") as f: css = "<style>" + f.read() + "</style>" css = css.format(fontsize=28, justify="center") html = utf + css + html return html if __name__ == '__main__': int_csrf() df = pd.read_excel('111.xlsx') #读取一整列的数据 start = time.time() with ThreadPoolExecutor(max_workers=10) as executor: nums = executor.map(chaxun, df.力扣主页.str.extract( r"leetcode-cn.com/u/([^/]+)(?:/|$)", expand=False)) df['力扣题数']=list(nums) with open("/www/xxxx/score.html", 'w', encoding="u8") as f: f.write(get_html(df)) print("耗时:", time.time() - start)
最后,非常感谢明佬!!yyds


