
classification_report()是python在机器学习中常用的输出模型评估报告的方法。
classification_report()函数介绍
classification_report()语法如下:
classification_report(
y_true,
y_pred,
labels=None,
target_names=None,
sample_weight=None,
digits=2,
output_dict=False,
zero_division=“warn”
)
| 参数 | 描述 |
|---|---|
| y_true | 真实值 ,一维数组形式(也可以是列表元组之类的) |
| y_pred | 预测值,一维数组形式(也可以是列表元组之类的) |
| labels | 标签索引列表,可选参数,数组形式 |
| target_names | 与标签匹配的名称,可选参数,数组形式 |
| sample_weight | 样本权重,数组形式 |
| digits | 格式化输出浮点值的位数。默认为2。当“output_dict”为“True”时,这将被忽略,并且返回的值不会四舍五入。 |
| output_dict | 是否输出字典。默认为False,如果为True则输出结果形式为字典。 |
| zero_division | 设置存在零除法时返回的值。默认为warn。如果设置为“warn”,这相当于0,但也会引发警告。 |
使用示例
from sklearn.metrics import classification_report
# 测试集真实数据
y_test = [1, 2, 3, 1, 2, 3, 1, 2, 3]
# 预测结果
y_predicted = [1, 2, 3, 3, 2, 1, 3, 2, 3]
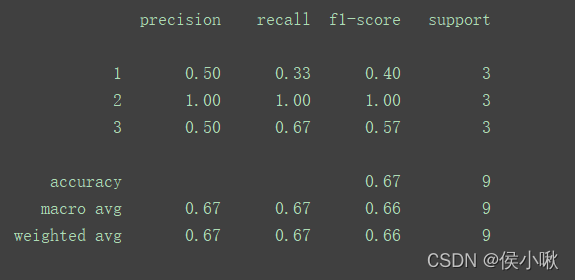
以这两行数据为例,不难直接看出,
预测中预测了
- 2次1标签,成功1次,1标签预测的准确率率为0.5
- 3次2标签,成功3次,2标签预测的准确率为1.0
- 4次3标签,成功2次,3标签预测的准确率为0.5
print(classification_report(y_test, y_predicted))
也可以加上target_names参数,效果如下:
print(classification_report(y_test, y_predicted, target_names=['a类', 'b类', 'c类']))
如图左边显示出了新传入的标签名。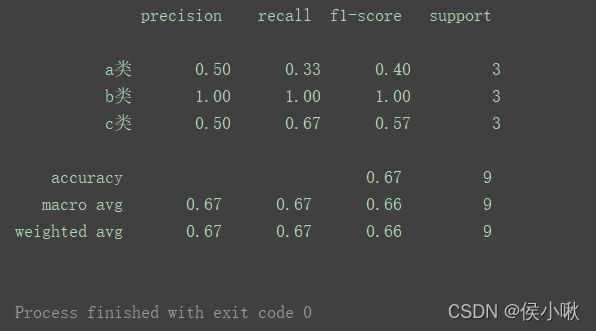
输出分析
由图可见,precisoin即准确率,也称查准率。
recall是召回率 ,也称查全率,
f1-score简称F1
对于其中一个标签预测结果进行评估,引入以下概念:
| 名称 | 简写 | 通俗描述 |
|---|---|---|
| 真正例 | TP | 预测结果是该标签,实际是该标签的样例个数 |
| 假正例 | FP | 预测结果是该标签,实际不是该标签的样例个数 |
| 假反例 | FN | 预测结果不是该标签,实际是该标签的样例个数 |
| 真反例 | TN | 预测结果不是该标签,实际是该标签的样例个数 |
其中, 满足TP+FP+FN+TN=样例总数
查准率的定义公式为
可以描述为 预测结果是该标签的样例中,实际是该标签的所占比。
查全率的定义公式为
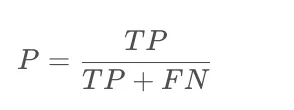
可以描述为 实际是该标签的样例中,预测结果是该标签的所占比。
以该例的标签’3’为例,
‘3’标签预测了4次,成功了2次,则查准率为
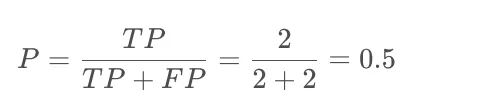
所有标签一共预测了9次,其中3标签预测了4次,则其它标签预测了5次,这五次中有1次是3标签,即FN=1则查全率为:
查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往会偏低,查全率高时,查准率往往会偏低。通常只可能在一些简单任务中,才可能使查准率和查全率都很高。
此时结合名字,不难看出:查全率,是在衡量关于某标签的预测结果涵盖的是否“周全”,查全率高意味着,即某个标签预测得准确率不一定高,但是其真实值会大量存在于或者被包含于预测值中。
f1-score也称F1,

F1是基于查准率与查重率 的调和平均定义的:
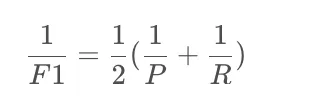
accruracy 整体的准确率 即正确预测样本量与总样本量的比值。(不是针对某个标签的预测的正确率)
macro avg 即宏均值,可理解为普通的平均值。
macro-P 宏查准率
macro-R 宏查全率
macro-F1 宏F1
对应的概念还有 微均值 micro avg
公式经过等价转换,分子分母同时乘以标签个数,micro-P等价于所有类别中预测正确量与总样本量的比值。
micro-R 同理,即所有类别中预测正确的量占该标签实际数量的比例。
