简介:
本文向您详细介绍如何通过DataWorks数据同步功能,将Hadoop数据同步到阿里云Elasticsearch上,并进行搜索分析。
本文字数:2673
阅读时间:预计10分钟
目录
背景信息
环境准备
数据准备
数据同步
结果验证
数据搜索与分析
以下是正文
背景信息
您也可以使用Java代码进行同步,具体请参考通过ES-Hadoop将Hadoop数据写入阿里云Elasticsearch和在E-MapReduce中使用ES-Hadoop。
环境准备
- 搭建Hadoop集群。在进行数据同步前,您需要保证自己的Hadoop集群环境正常。本文使用阿里云EMR服务自动化搭建Hadoop集群,详细过程请参见步骤三:创建集群。EMR Hadoop的版本信息如下。
- EMR版本:EMR-3.11.0
- 集群类型:HADOOP
- 软件信息:HAFS2.7.2/YARN2.7.2/Hive2.3.3/Ganglia3.7.2/Spark2.3.1/HUE4.1.0/Zeppelin0.8.0/ Tez0.9.1 / Sqoop1.4.7 / Pig0.14.0 / ApacheDS2.0.0 / Knox0.13.0
- Hadoop集群使用VPC网络,区域为华东1(杭州),主实例组ECS计算ziyu 配置公网及内网IP,高可用选择为否(非HA模式),具体配置如下图所示

- 购买和配置Elasticsearch。登录Elasticsearch控制台,参考购买和配置,购买一个Elasticsearch实例。选择与EMR集群相同的区域和VPC网络配置,如下图所示。

- 创建DataWorks工作空间。创建DataWorks项目,区域选择华东1区。本文直接使用已经存在的项目bigdata_DOC。

数据准备
在Hadoop集群中创建测试数据,步骤如下。
- 进入EMR控制台界面,单击左侧菜单栏的交互式工作台。
- 选择文件 > 新建交互式任务。
- 在Notebook对话框中,输入交互式任务的名称,选择默认类型以及关联集群,单击确认。本文新建一个名为es_test_hive的交互式任务,默认类型为Hive,关联集群为环境准备中创建的EMR Hadoop集群。

- 在代码编辑区域中,输入Hive建表语句,单击运行。本文档使用的建表语句如下。
CREATE TABLE IF NOT
EXISTS hive_esdoc_good_sale(
create_time timestamp,
category STRING,
brand STRING,
buyer_id STRING,
trans_num BIGINT,
trans_amount DOUBLE,
click_cnt BIGINT
)
PARTITIONED BY (pt string) ROW FORMAT
DELIMITED FIELDS TERMINATED BY ',' lines terminated by '\n'表创建成功后,系统会提示Query executed successfully。

- 单击文件 > 新建段落,在段落编辑区域输入SQL语句,单击运行,插入测试数据。

您可以选择从OSS或其他数据源导入测试数据,也可以手动插入少量的测试数据。本文使用手动插入数据的方法,脚本如下。
jinsert into
hive_esdoc_good_sale PARTITION(pt =1 ) values('2018-08-21','外套','品牌A','lilei',3,500.6,7),('2018-08-22','生鲜','品牌B','lilei',1,303,8),('2018-08-22','外套','品牌C','hanmeimei',2,510,2),(2018-08-22,'卫浴','品牌A','hanmeimei',1,442.5,1),('2018-08-22','生鲜','品牌D','hanmeimei',2,234,3),('2018-08-23','外套','品牌B','jimmy',9,2000,7),('2018-08-23','生鲜','品牌A','jimmy',5,45.1,5),('2018-08-23','外套','品牌E','jimmy',5,100.2,4),('2018-08-24','生鲜','品牌G','peiqi',10,5560,7),('2018-08-24','卫浴','品牌F','peiqi',1,445.6,2),('2018-08-24','外套','品牌A','ray',3,777,3),('2018-08-24','卫浴','品牌G','ray',3,122,3),('2018-08-24','外套','品牌C','ray',1,62,7) ;- 使用同样的方式新建段落,并在段落编辑区域输入
`js -
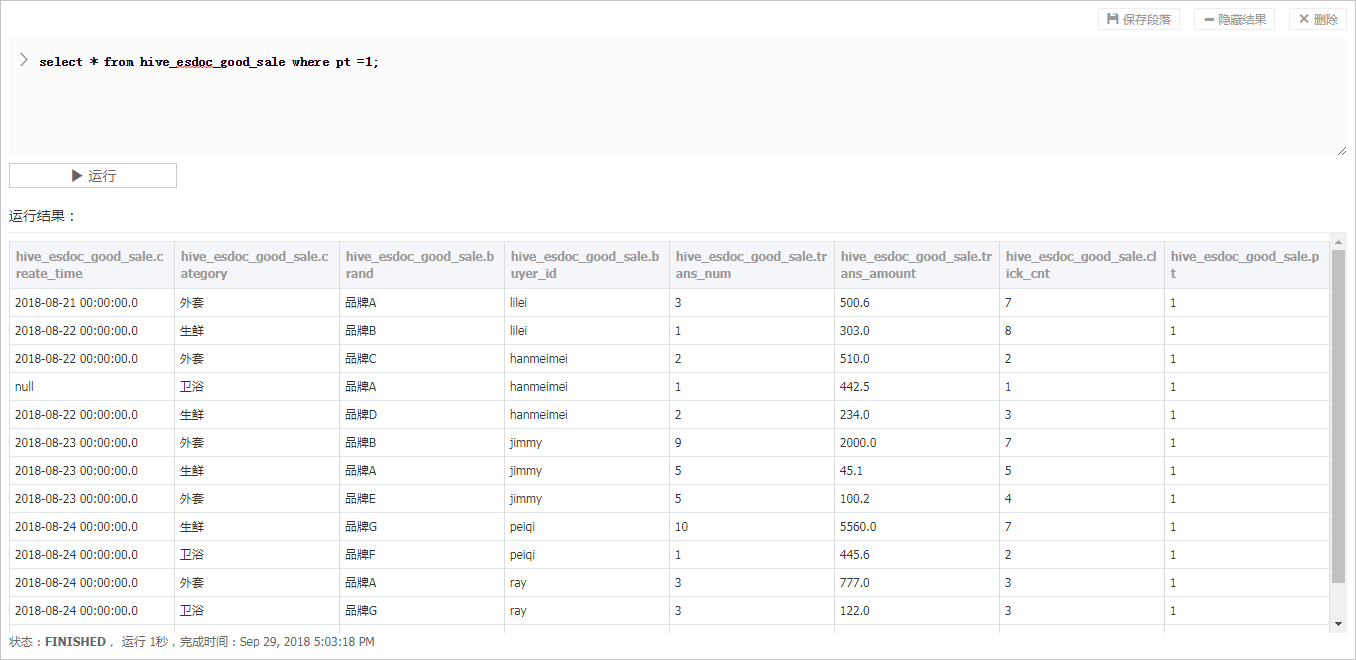
- from hive_esdoc_good_sale where pt =1;
语句,单击**运行**。
此操作可以检查Hadoop集群表中是否已存在数据可用于同步,运行成功结果如下。
### 数据同步
> **说明
**
由于DataWorks项目所处的网络环境与Hadoop集群中的数据节点(Data Node)网络通常不可达,因此您可以通过自定义资源组的方式,将DataWorks的同步任务运行在Hadoop集群的Master节点上(Hadoop集群内Master节点和数据节点通常可达)。
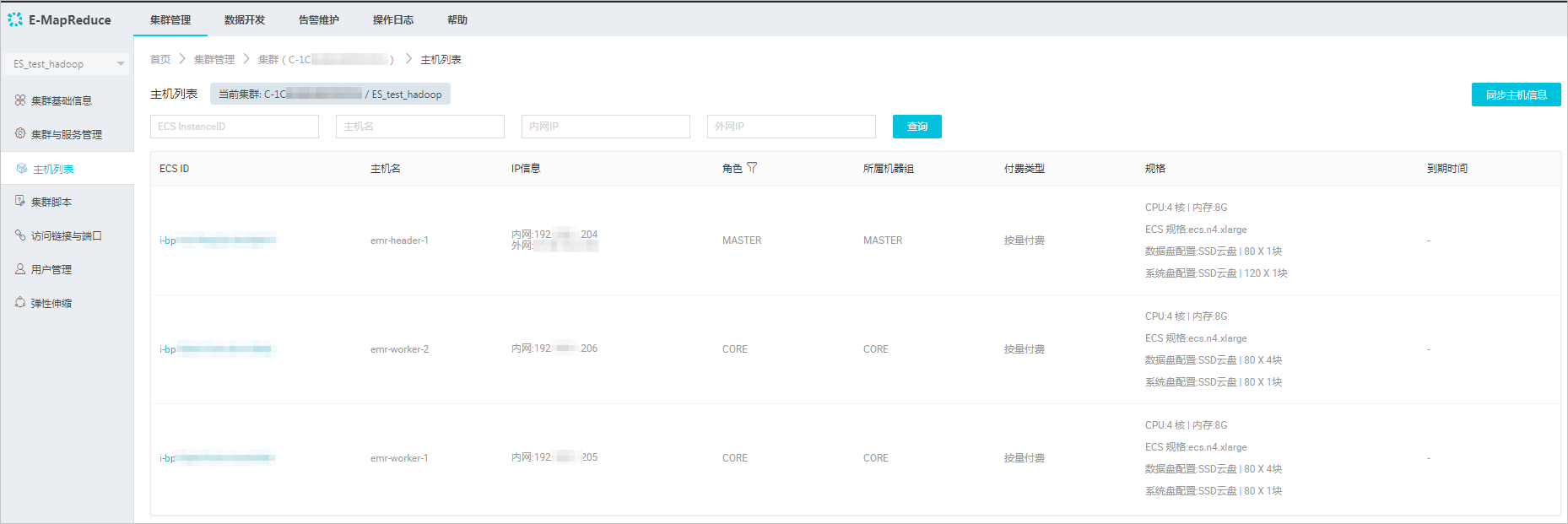
1. 查看Hadoop集群的数据节点。
- 在EMR控制台上,单击左侧菜单栏的集群。
- 选择您的集群,单击右侧的管理。
- 在集群管理控制台上,单击左侧菜单栏的主机列表,查看集群master节点和数据节点信息。
> **说明
**
通常非HA模式的EMR上Hadoop集群的Master节点主机名为emr-header-1,Data Node主机名为emr-worker-X。
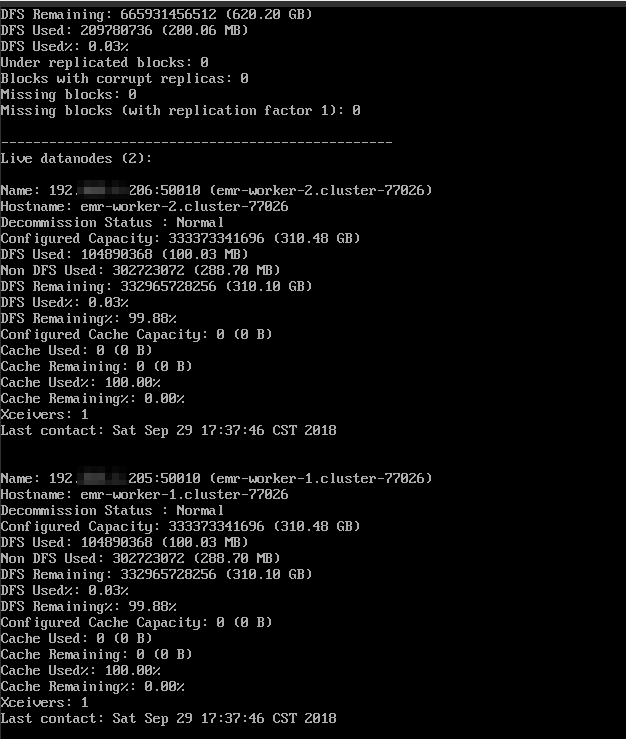
- 单击上图中Master节点的ECS ID,进入ECS实例详情页。单击远程连接进入ECS服务器,通过hadoop dfsadmin -report命令查看数据节点信息。
2. 新建自定义资源组。
- 进入DataWorks的**数据集成**页面,选择**资源组** > **新增资源组**。
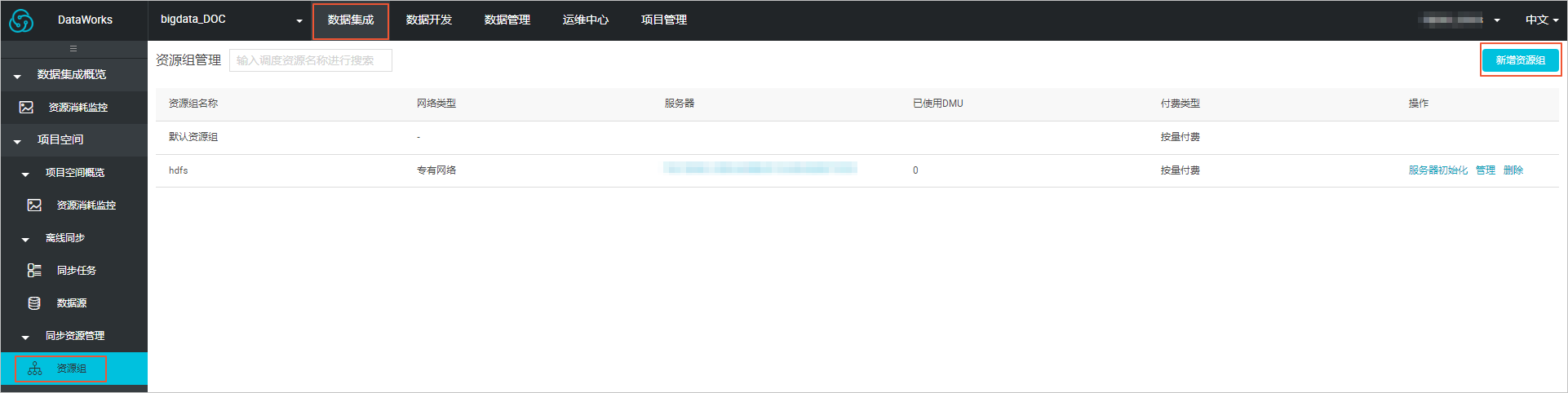
关于自定义资源组的详细信息请参见[新增任务资源](https://help.aliyun.com/document_detail/72979.html?spm=a2c4g.11186623.2.31.341d491ecP7i8I#concept-wfz-j45-q2b)。
- 根据界面提示,输入资源组名称和服务器信息。此服务器为您EMR集群的Master节点,服务器信息说明如下。
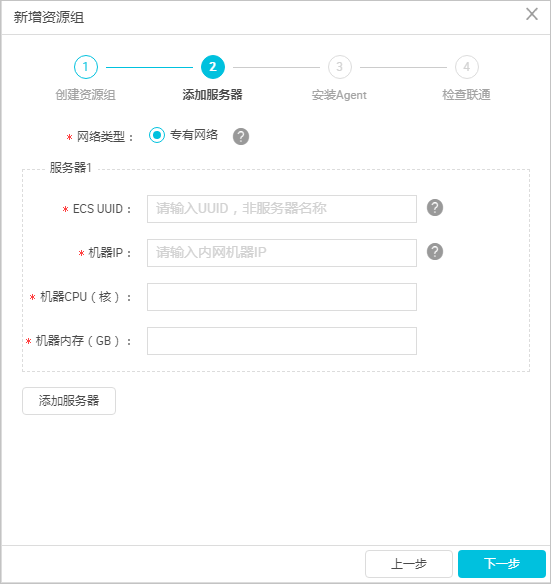
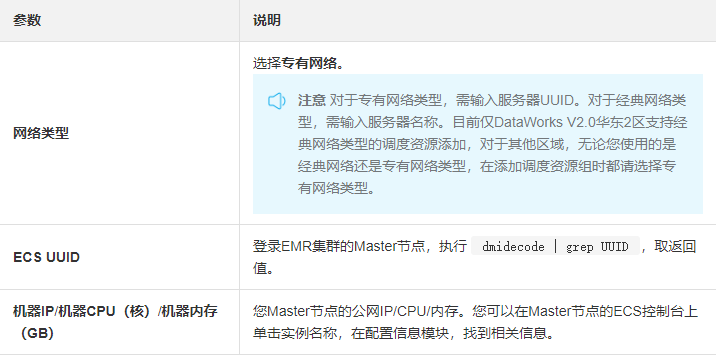
> **注意 **完成添加服务器后,您需要保证Master Node与DataWorks网络可达。
- 如果您使用的是ECS服务器,需设置服务器的安全组。
- 如果您使用的内网IP互通,需要[添加安全组。](https://help.aliyun.com/document_detail/72978.html?spm=a2c4g.11186623.2.33.341d491ecP7i8I#concept-ec4-cj5-q2b)
- 如果您使用的是公网IP,可直接设置安全组公网出入方向规则。
由于本文档的EMR集群使用的是VPC网络,且与DataWorks在同一区域下,因此不需要进行安全组设置。
- 按照提示安装自定义资源组Agent。
> **注意**:由于本文使用的是VPC网络类型,因此不需开通8000端口。
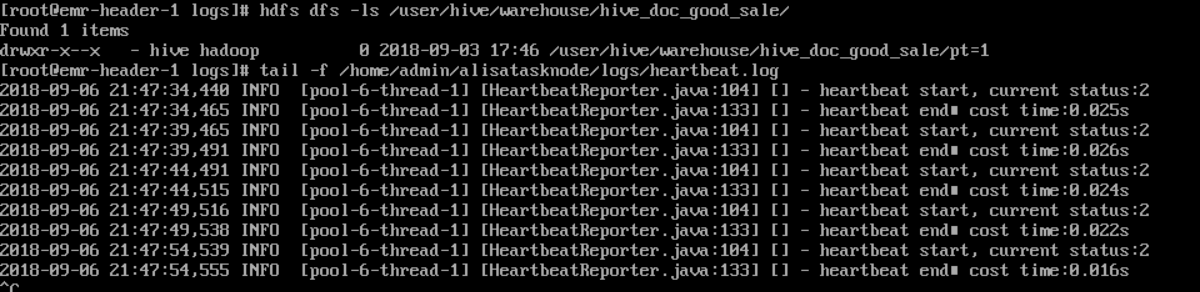
观察到当前状态为**可用**时,说明新增自定义资源组成功。如果状态为不可用,您可以登录Master Node,使用```js
tail –f/home/admin/alisatasknode/logs/heartbeat.log
命```
令查看DataWorks与Master Node之间心跳报文是否超时。
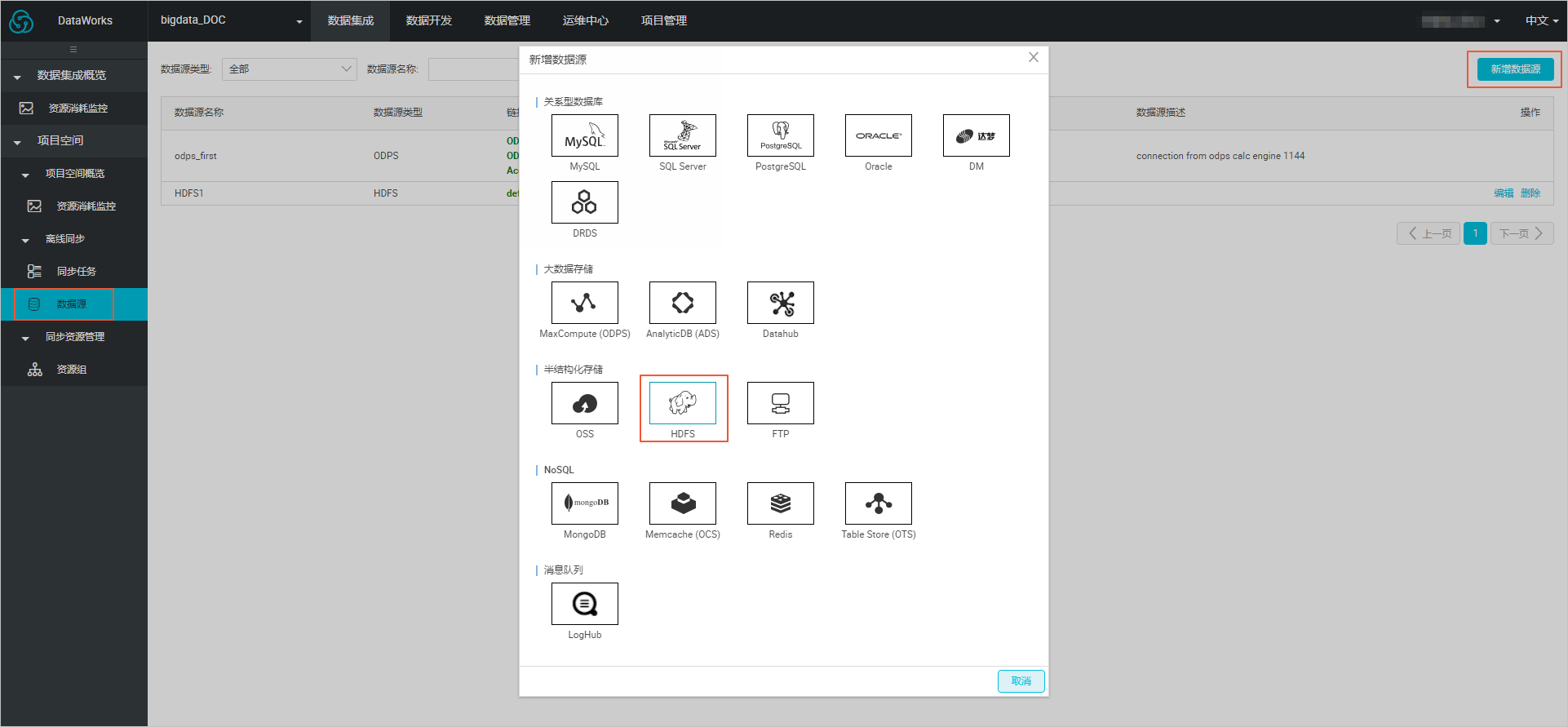
3. 新建数据源
- 在DataWorks的数据集成页面,单击**数据源**>**新增数据源**,在弹框中选择**HDFS**类型的数据源
- 在**新增HDFS**数据源页面中,填写**数据源名称**和**defaultFS。**
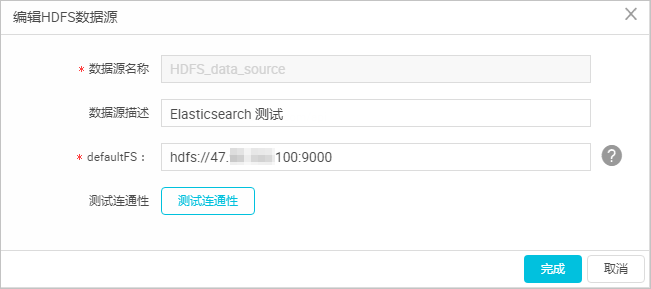
> 注意 对于EMR Hadoop集群而言,如果Hadoop集群为非HA集群,则此处地址为```js
hdfs://emr-header-1的IP:9000
。```
如果Hadoop集群为HA集群,则此处地址为```js
hdfs://emr-header-1的IP:8020
。```
在本文中,emr-header-1与DataWorks通过VPC网络连接,因此此处填写内网IP,且不支持连通性测试。
4. 配置数据同步任务。
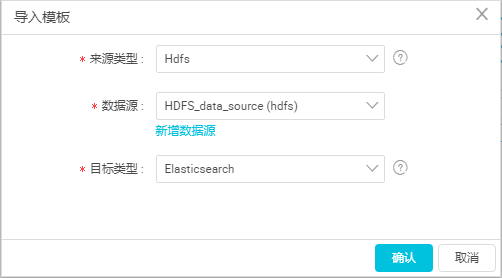
a. 在DataWorks数据集成页面,单击左侧菜单栏的**同步任务**,选择**新建** > **脚本模式**。
b. 在**导入模板**对话框中,选择数据源类型如下,单击**确认**。
c. 完成导入模板后,同步任务会转入[脚本模式](https://help.aliyun.com/document_detail/74304.html?spm=a2c4g.11186623.2.38.341d491ecP7i8I#concept-olb-drc-p2b),本文中配置脚本如下,相关解释请参见脚本模式配置,Elasticsearch的配置规则请参考[配置Elasticsearch Writer。](https://help.aliyun.com/document_detail/74362.html?spm=a2c4g.11186623.2.39.341d491ecP7i8I#concept-okj-c24-q2b)
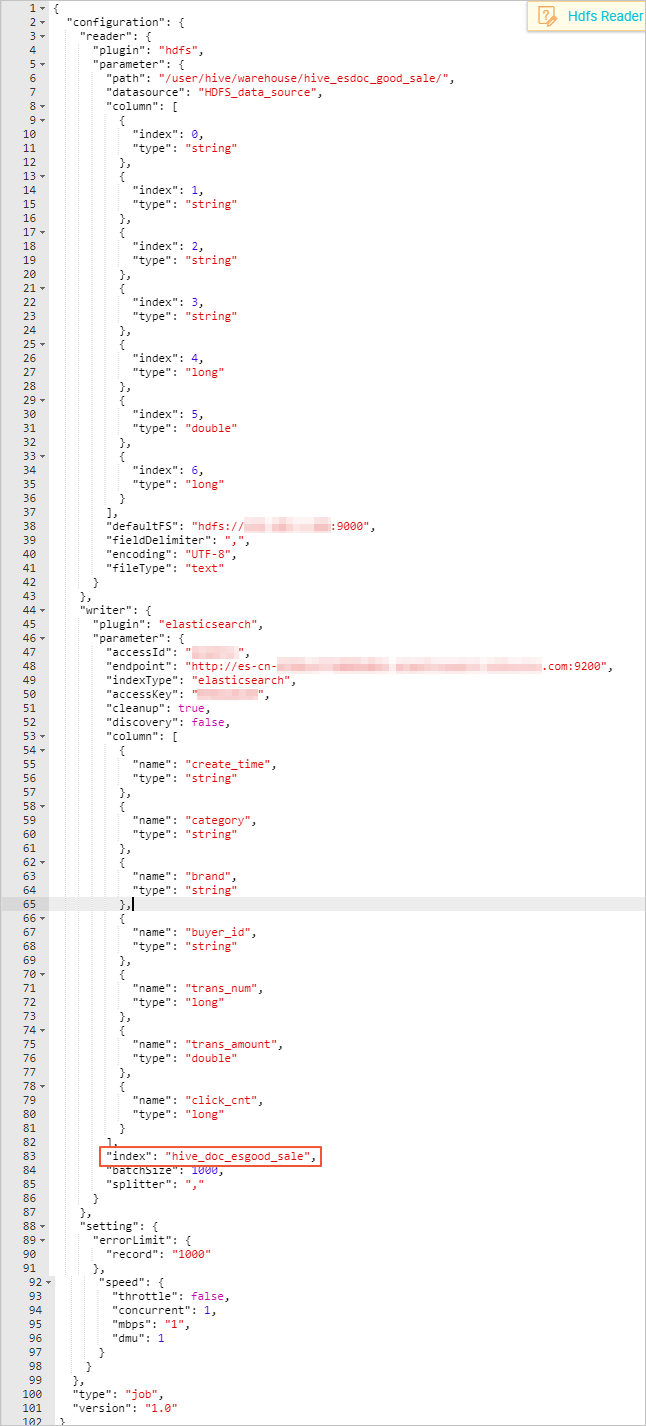
- 同步脚本的配置分为三个部分,Reader用来配置您上游数据源(待同步数据的云产品)的config,Writer用来配置 Elasticsearch的config,setting用来配置同步中的一些丢包和最大并发等。
- path为数据在Hadoop集群中存放的位置,您可以在登录master node后,```js
使用hdfs dfs –ls /user/hive/warehouse/hive_esdoc_good_sale
命```
令确认。对于分区表,您可以不指定分区,DataWorks数据同步会自动递归到分区路径。
- 由于Elasticsearch不支持timestamp类型,本文档将**creat_time**字段的类型设置为string。
- **endpoint**为Elasticsearch 的内网或外网地址。如果您使用的是内网地址,请在Elasticsearch的集群配置页面,配置Elasticsearch的系统白名单。如果您是用的是外网地址,请在Elasticsearch的网络配置页面,配置 Elasticsearch的公网地址访问白名单(包括DataWorks服务器的IP地址和您所使用的资源组的IP地址)。
- Elasticsearch Writer中**accessId**和**accessKey**需要配置您的Elasticsearch的访问用户名(默认为elastic)和密码。
- **index**为Elasticsearch实例的索引,您需要使用该索引名称访问Elasticsearch的数据。
- 在创建同步任务时,DataWorks的默认配置脚本中,**errorLimit**的**record**字段值为0,您需要将其修改为大一些的数值,比如1000。
d. 完成配置后,单击页面右侧的**配置任务资源组**,选择您创建的资源组名称,完成后单击**运行**。如果提示**任务运行成功**,则说明同步任务已完成。如果运行失败,可通过复制日志进行进一步排查。
### 结果验证
1. 进入[Elasticsearch控制台](https://elasticsearch.console.aliyun.com/?spm=a2c4g.11186623.2.41.341d491ecP7i8I),单击实例名称>可视化控制,在Kibana区域中,单击右下角进入控制台。
2. 输入用户名和密码,单击登录进入kibana控制台,选择Dev Tools。
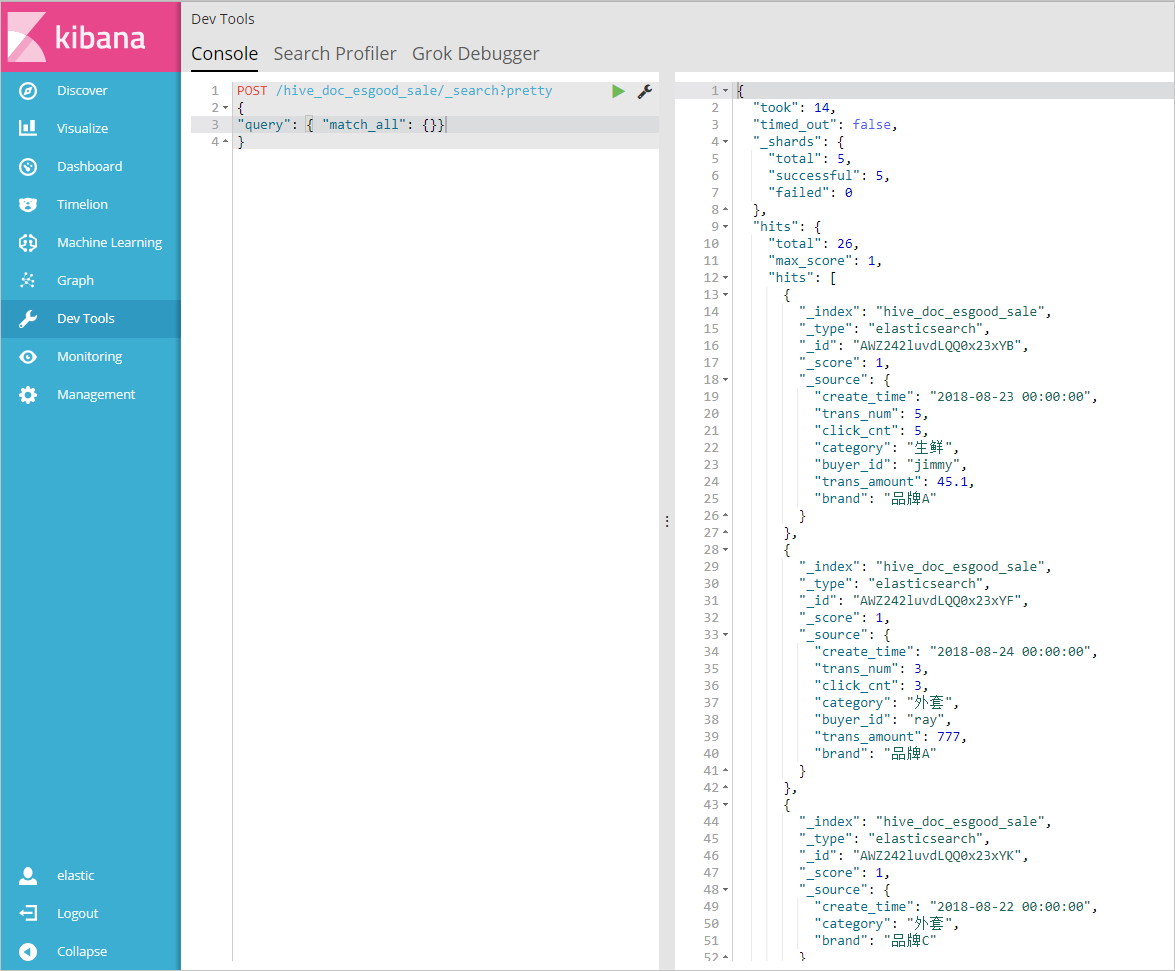
3. 在**Console**控制台中,执行如下命令,查看已经同步过来的数据POST /hive_doc_esgood_sale/_search?pretty
{
"query": { "match_all": {}}
}
```hive_doc_esgood_sale``` 为您同步数据时,设置的index字段的值。
### 数据搜索与分析
1. 在**Console**控制台中,执行如下命令,返回品牌为A的所有文档。
POST /hive_doc_esgood_sale/_search?pretty
{
"query": { "match_all": {} },
"sort": { "click_cnt": { "order": "desc" } },
"_source": ["category", "brand","click_cnt"]
}
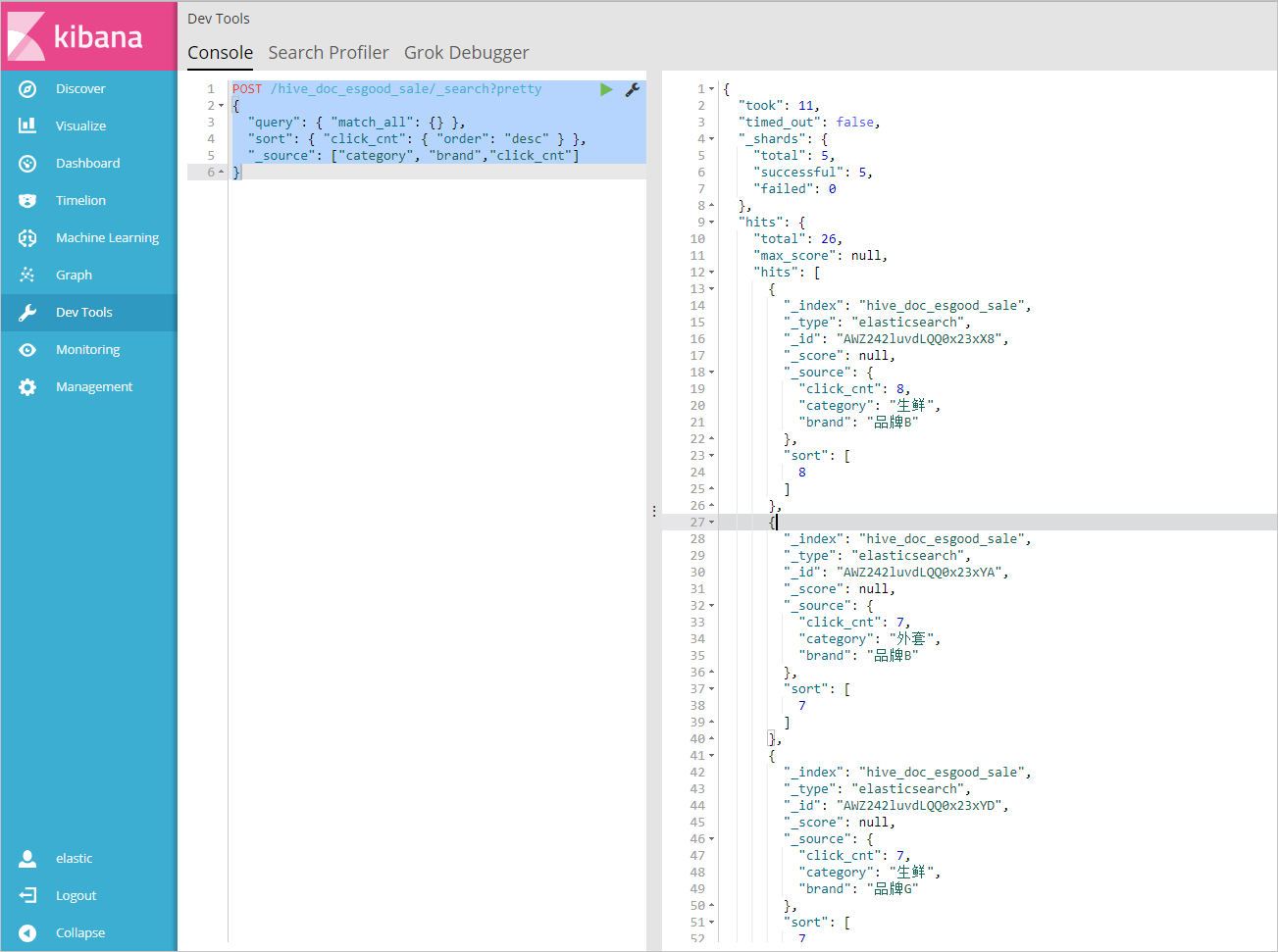
2. 在**Console**控制台中,执行如下命令,按照**点击次数**进行排序,判断各品牌产品的热度。POST /hive_doc_esgood_sale/_search?pretty
{
"query": { "match_all": {} },
"sort": { "click_cnt": { "order": "desc" } },
"_source": ["category", "brand","click_cnt"]
}
` 
更多命令和访问方式,请参见阿里云Elasticsearch官方文档和Elastic.co官方帮助中心。
加入我们
加入《Elasticsearch中文技术社区》,与更多开发者探讨交流

订阅《阿里云Elasticsearch技术交流期刊》每月定期为大家推送相关干货

2019年阿里云云栖大会上,Elasticsearch背后的商业公司Elastic与阿里云Elasticsearch确定战略合作升级,在100%兼容开源的基础上,完成了ELK的完整生态云上闭环,欢迎开通使用。
点击了解更多产品信息
