
有的时候,算法本身以及技术并不是难题,最大的问题在于数据收集的维度以及不同数据的打通。
亚马逊最早的理念就是构建一个千人千面的书店,基于你当前的场景和过去的行为,每个读者看到的推荐页都是不一样。
这套推荐系统最早从1998年开始,至今走过了20个年头,其算法已经被广泛地应用在YouTube、Netflix等公司。
这是我们最早对大数据的直观认识,后来基于大数据的推荐系统越来越频繁地出现在我们的日常生活中,大数据也成为炙手可热的技术潜力股。
在无数据不AI的时代下,许多初创公司开始将眼光瞄准其背后的营销场景,比如你是星巴克的会员,想要在外卖平台点一杯咖啡,系统会自动推荐你平常最喜欢的口味。
这背后就是我们今天所采访的智能数据公司创略科技提供的技术支持,从硅谷创业到服务300+标杆企业,创略科技联合创始人杨辰韵和我们聊了聊大数据是如何解放营销天性的。
关于数据的二三事
在美国读书期间,杨辰韵因为对数字营销的兴趣和另外一个合伙人,也就是创略科技的创始人胡世杰一拍即合,开始考虑基于营销场景,用大数据、人工智能或者新兴的区块链等技术,来去让营销场景更加实时智能,高效,创略科技应运而生。

图 | 创略科技联合创始人杨辰韵
相较于国内,国外的大数据应用起步明显更早,尤其是在技术层面。不过,伴随着国内的人口红利优势带来的庞大消费者用户体量,国内的大数据应用场景显然更加丰富。但杨辰韵强调国外对于数据安全的意识明显要高于国内。
“因为Facebook的数据泄露事情,美国加州已经通过法案,隐私数据一定要确保经过用户的授权才能去使用,或者和第三方去做相关的交换。欧洲针对这个问题可能比美国的更早。国内去年6月份的网安法(《网络安全法》)规定了第三方数据交易的情况。但是企业自用的话,相对来说还是比较松的。长期来看,无论是哪个层面的数据,一定要从法律和价值的层面去确保消费者的授权。”
确实,谈及数据,很多人的第一反应就是数据隐私问题,最近因为泄露用户隐私而站在风口浪尖的谷歌,不得不关闭google+的消费者版本。再往前则是Facebook的数据泄露风波。随着移动互联网和AI时代的到来,数据是很多技术以及应用的水之源。但是“不作恶”的前提是尊重用户的数据安全,得到用户的数据确权。
这也是许多大数据公司面临的考验,为了更好地解决这些问题,创略科技开始了区块链方面的研究。区块链的可追溯、不可篡改性决定了它可以确保消费者的隐私数据一定是在已知授权的情况下,企业才可以使用的。当前技术难度在于底层公链的TPS吞吐量。“如果这个场景需要很高的TPS的,在现有情况下就不适合用区块链技术。短期来说,区块链还像20年前的互联网。目前在拨号上网的状态。”
同时,创略科技的业务模式规避了数据风险。杨辰韵介绍,创略科技仅是一家数据及AI技术公司,旗下智能客户数据平台专注应用的是企业第一方客户数据,本身并不是采集数据的第三方供应商,也不充当卖数据的角色。
如何玩转大数据营销?
创略科技的一个核心要点就是“营销”,目前他们的产品线主要包括三条:多渠道数据打通、整合的NEXUS(企业级客户数据平台),数据建模、分析、预测的IQ(企业级人工智能应用)以及负责保护用户数据隐私的区块链产品APEX。其中,最关键的是一块是基于企业第一方数据的客户数据平台,从客户数据的采集、分析和应用的环节上,做到实时的海量数据处理,最终做实时个性化营销的场景。
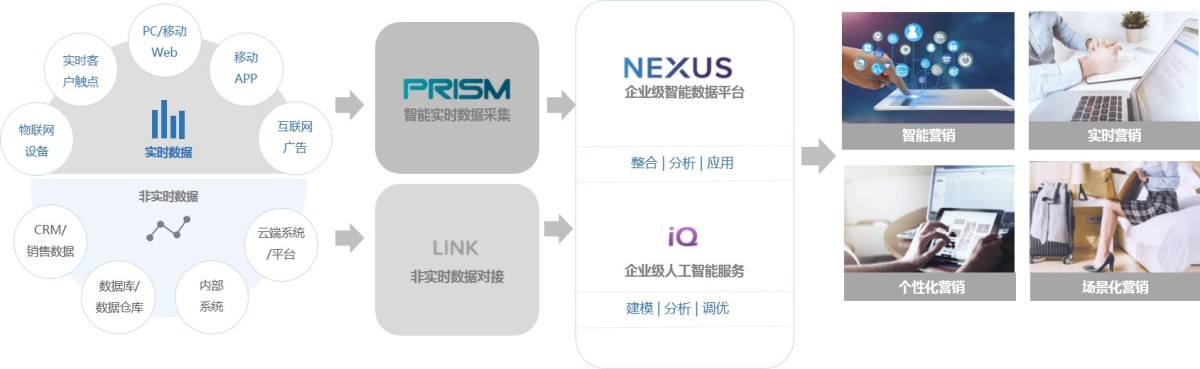
很多企业拥有很多渠道,比如APP、官方网站、微信公号等等,但这些渠道都是彼此隔离的。接入NEXUS后,企业可以将这些渠道的非实时数据和实时数据都输入到NEXUS中,从而发现不同数据集之间的共性和特性,以此来更好地进行企业决策。
据杨辰韵介绍,目前他们在零售和汽车行业的应用最多,其中以星巴克系统为例,创略科技解决的核心问题如何打通线上线下的数据,形成基于用户个人的唯一ID和画像,然后提供相关的分析和营销建议。
而在大数据营销的准确性上,杨辰韵提到他们的算法模型去预测玛莎拉蒂潜在客户的购车意向,预测准确率可以高达95%,这其中的关键因素就是他们的IQ产品,创略科技在分析环节扩展了AI模块,用户可以直接调用模块内已预制的算法和模型,也可以自定义相关模型去分析营销数据。
当然,这条赛道上狂奔的初创企业不仅仅是创略科技一家,谈及他们的技术优势,杨辰韵总结了三点:一是大数据的打通和分析应用,二是算法的准确度,最后是它们产品的迭代以及行业内的先发优势。
“机器会帮助我们做一些机构化数据的分析建模,进行客户分群,同时自然语言处理技术能够快速提取数据中的关键内容,这些都能保证我们在算法准确度上的壁垒。”
大数据应用那么多,难题在哪里?
在学术界,曾经有这样一个观点:“真正能够训练出好的模型的数据量,应当是趋于无穷的,所以即便是拥有了大量数据去训练模型,和理想的智能模型之间,也有着本质的差别。”
在杨辰韵看来,算法本身以及技术并不是难题,最大的问题在于数据收集的维度以及不同数据的打通。同样以营销领域为例,线上用户点击的广告、网页的浏览行为等数据容易收集,同时伴随着IoT的发展,通过WIFI、蓝牙、摄像头等方式,也可以监测到用户的线下行为,最终打通线上线下的闭环。
但是这种数据的融合以及打通并不是一帆风顺,“有的时候和企业的战略组织架构有关系,比如它们的组织架构不允许打通所有数据,一个部门和另一个部门的数据无法打通,这些都不是技术问题,这是架构问题。”

同时,在打通线上以及线下数据过程中,肯定会出现数据孤岛的现象,所以也要关注数据的关联度以及数据清洗等等问题。
其实不管是大数据还是人工智能,从实际应用来看,最终需要达到效率提高的目标。杨辰韵认为,大数据应用的关键在于为正确的人推送正确的有效信息,基于这个大前提,如果现有的一些技术不如上一代技术或者是人工的话,不如弃之不用。衡量技术的标准在于是否创造更多的价值,提升了应用场景的效率。
“至于是大数据、小数据还是样本,我们应该确定企业本身所拥有的原材料数据情况,然后对症下药,不是为了达成某个概念去做这个事情,而是要解决好实际问题。尤其是企业的第一方数据,虽然数据体量相对较小,但是价值非常高。而海量第三方大数据有很多噪音数据和非真实数据,这个情况下它的应用价值并不高。”
结语
大数据已经无处不在,万亿市场留给初创企业的机会很多,关键在于谁能抓到迅速成长的机会,在合理、安全的范围,充分发挥数据的价值。
后续,在业务层面,创略科技也将不断围绕营销和客户生命周期的场景,继续迭代和丰富其智能数据营销产品。
【镁客·请讲】专注于报道科技创新项目;我们敞开心扉面对每一位创业者,力求为您呈现一群鲜活、有性格的品牌和人物;我们倾听创业故事和人生经历、探讨商业模式和行业趋势、对接资本市场和供需双方,以期为产业发展注入新的活力。
欢迎做客【镁客·请讲】,栏目合作请发送邮件至:post@im2maker.com
