
此进阶篇相较于前一篇每个item多了工作职责(jobDescription),工作要求(jobRequirement)两个字段。
另外从技术的角度上来说,前一篇在tencent.py文件中只有一个parse函数,此进阶篇要完成链接的跳转,在跳转后新的页面中爬取内容,有3个parse函数。
- 本人操作系统为Win10,python版本为3.6,使用的命令行工具为powershell,所起作用和cmd的作用相差不大。
- 进入powershell:在你的爬虫程序文件夹中,在按住shift键的情况下,单击鼠标右键,显示如下图。
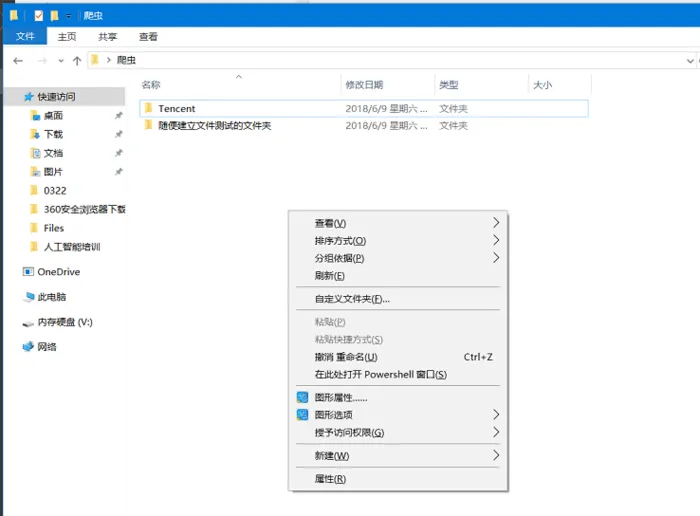
进入powershell.png
点击在此处打开Powershell窗口,可以实现基于当前目录打开powershell
- 在powershell中输入命令scrapy startproject TencentJob2,确认命令正确以后运行,正确运行的结果如下图。
 正确新建项目.png
正确新建项目.png
这个命令起到的效果是新建了一个工程名为TencentJob2的工程目录。
- 在powershell中输入命令cd T,然后按一下Tab键,自动补全为命令cd .\TencentJob2以后,运行该命令。
- 在powershell中输入命令scrapy genspider tencent hr.tencent.com 。
这个命令起到的效果是在TencentJob2/TencentJob2/spiders这个目录中产生一个tencent.py文件,这个文件已经自动生成一部分代码,如果自己新建一个py文件,并且手动输入代码是一样的效果,但是用命令生成py文件会稍微快一点。 - 在已经安装好Pycharam的条件下,打开Pycharm,并打开TencentJob2工程。
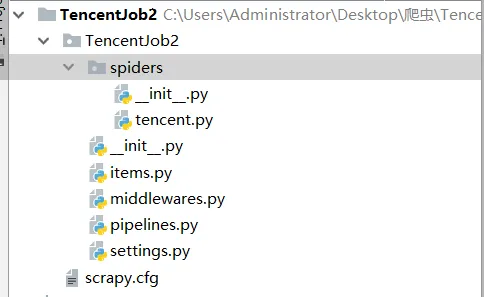
.项目文件结构缩略图
上图是整个工程的缩略图。
- 对工程中的items.py文件编写代码。
一个条目item中有7个字段:职位名称(jobName)、职位类别(jobType)、招聘人数(recruitmentNumber)、工作地点(workplace)、发布时间(publishTime)、工作职责(jobDescription)、工作要求(jobRequirement)。
from scrapy import Field
import scrapy
class Tencentjob2Item(scrapy.Item):
jobName = Field()
jobType = Field()
recruitmentNumber = Field()
workplace = Field()
publishTime = Field()
jobDescription = Field()
jobRequirement = Field()
- 对文件中的tencent.py文件编写代码。
在第一级页面中爬取item的5个字段:工作名字jobName,工作类型jobType,招聘人数recruitmentNumber,工作地点workplace,发布时间publishTime,将已经爬取到的5个字段存入Request函数中的meta关键字参数中。
通过parse2函数爬取第二级页面,这个页面有2个字段:工作职责jobDescription,工作要求jobRequirement。通过item = meta['item']这一句将前一页爬取到5个字段取出,然后再存入新爬取的2个字段,这样总共是7个字段。
parse函数作用是提取出最大页码数,假设最大页码数为300,则把0-299这300个数字和baseurl组成的300页招聘信息作为第一级页面进行爬取。
import scrapy
from TencentJob2.items import Tencentjob2Item
from scrapy.http import Request
class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['hr.tencent.com']
start_urls = ['https://hr.tencent.com/position.php?&start=0']
def parse(self,response):
maxPage = response.xpath("//div[@class='pagenav']/a[last()-1]/text()").extract()[0]
baseUrl = 'https://hr.tencent.com/position.php?&start={}0'
for i in range(int(maxPage)):
yield Request(baseUrl.format(i),callback= self.parse1, dont_filter=True)
def parse1(self, response):
def find(pNode, xpath):
if len(pNode.xpath(xpath)):
return pNode.xpath(xpath).extract()[0]
else:
return ''
job_list = response.xpath("//tr[@class='odd' or @class= 'even']")
for job in job_list:
item = Tencentjob2Item()
item['jobName'] = find(job, "td[1]/a/text()")
item['jobType'] = find(job, "td[2]/text()")
item['recruitmentNumber'] = find(job, "td[3]/text()")
item['workplace'] = find(job, "td[4]/text()")
item['publishTime'] = find(job, "td[5]/text()")
details_url = "https://hr.tencent.com/" + find(job, "td[1]/a/@href")
yield Request(details_url,meta={'item':item},callback=self.parse2)
def parse2(self, response):
def contentList2str(contentList):
result = ''
if contentList[0][0] != '1':
for a,b in zip(range(len(contentList)),contentList):
result += str(a+1) + '.' + b + '\n'
else:
result = '\n'.join(contentList)
return result
item = response.meta['item']
item['jobDescription'] = contentList2str(response.xpath("//table/tr[3]/td/ul/li/text()").extract())
item['jobRequirement'] = contentList2str(response.xpath("//table/tr[4]/td/ul/li/text()").extract())
return item
- 对工程中的pipelines.py文件编写代码。
df.to_excel('腾讯社会招聘(详细版).xlsx', columns=[k for k in self.job_list[0].keys()])这一行代码中的columns=[k for k in self.job_list[0].keys()]语句简短高效,在学会这个方法之前笔者曾经有两三个月的时间一直用columns=[‘jobName’,'jobType','recruitmentNumber','workplace','publishTime','jobDescription','jobRequirement']的方法,所以两者对比,前者代码少很多,而且不容易出错。
import pandas as pd
class Tencentjob2Pipeline(object):
job_list = []
def process_item(self, item, spider):
self.job_list.append(dict(item))
return item
def close_spider(self, spider):
df = pd.DataFrame(self.job_list)
df.to_excel('腾讯社会招聘(详细版).xlsx', columns=[k for k in self.job_list[0].keys()])
- 对工程中的settings.py文件编写代码。
第1个修改,下面这一段
#ITEM_PIPELINES = {
# 'TencentJob2.pipelines.Tencentjob2Pipeline': 300,
#}
改为:
ITEM_PIPELINES = {
'TencentJob2.pipelines.Tencentjob2Pipeline': 300,
}
修改的作用就是使工程知道调用名为Tencentjob2Pipeline的管道。
第2个修改,下面这一段
#CONCURRENT_REQUESTS_PER_DOMAIN = 96
#CONCURRENT_REQUESTS_PER_IP = 96
改为:
CONCURRENT_REQUESTS_PER_DOMAIN = 96
CONCURRENT_REQUESTS_PER_IP = 96
修改的作用是增大线程并发数量,使程序能够尽快运行完成。
- 到此为止,所有代码方面的工作已经完成,在之前打开的powershell中输入scrapy crawl tencent,确认命令正确后运行。
如果powershell已经关闭,可以重新打开powershell,并确保已经cd进入TencentJob2工程的任一级目录。
运行工程生成的的"腾讯社会招聘(详细版).xlsx"文件在powershell运行命令时所在的那一个目录。
提示:
- 源代码已经上传github,链接地址:https://github.com/StevenLei2017/TencentJob2
-
结果展示如图。
 excel结果截图.png
excel结果截图.png

