

在深度学习领域,目前训练有很多层和数百万连接的深度神经网络(DNN)的常规方法,是随机梯度下降(SGD)。很多人认为,SGD有效计算梯度的能力至关重要。
然而,我们要发布5篇系列论文,支持一种正在兴起的认识:通过用进化算法来优化神经网络的神经进化(neuroevolution)也是为强化学习(RL)训练深度神经网络的一种有效方法。
遗传算法是训练深度神经网络的一种有效替代方法
我们发明了一项新技术来有效地演化DNN,发现一个极度简单的遗传算法(GA)可以用来训练有400多万个参数的深度卷积网络来靠输入像素玩雅达利游戏,在很多游戏上胜过了现代的深度强化学习算法,比如DQN、A3C、和进化策略(ES),也因为并行性更好而实现了更快的速度。
这样的结果会让人惊讶,既是因为没想到不基于梯度的GA能很好地适应这么大的参数空间,也是因为没想到把GA用到RL上能够实现媲美或超越最先进的技术。
我们进一步表明,GA的新颖性搜索等增强提高了它的能力,也适用于DNN的规模,可以促进探索,解决DQN、A3C、ES、GA等奖励最大化算法容易遇到的局部最优等欺骗性问题。
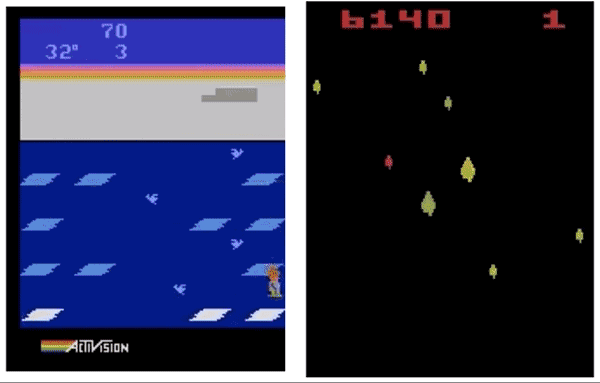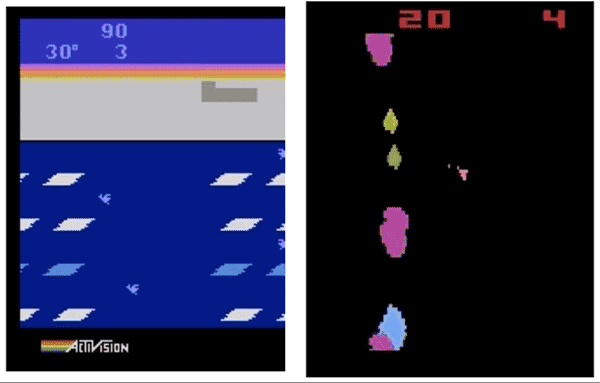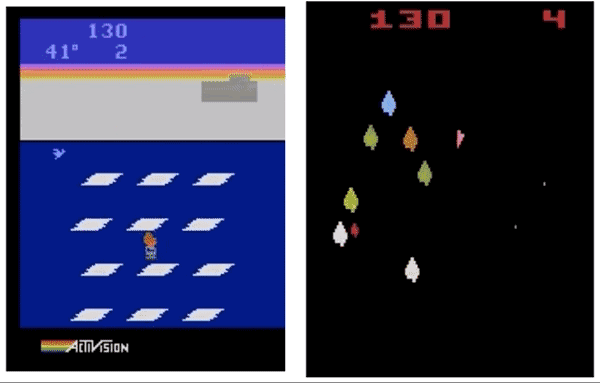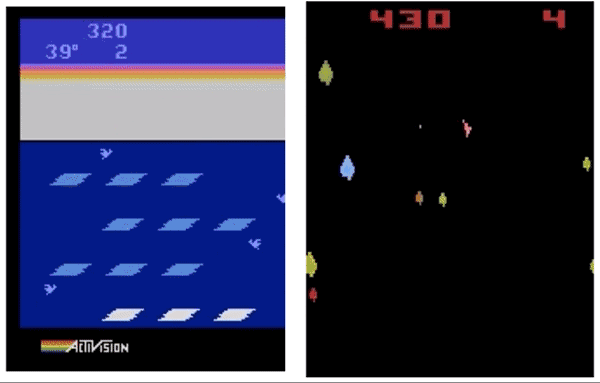
左:GA策略在Frostbite游戏中得到了10500分,DQN、A3C、ES等得分不足1000。
右:GA策略玩行星游戏玩得不错,平均分超过了DQN和ES,但不及A3C。
通过梯度计算实现安全变异
在另一篇论文中,我们展示了梯度可以与神经进化结合起来,提高演化循环神经网络和非常深的深度神经网络的能力,实现100层以上DNN的演化,远超过以前神经进化可能达到的水平。
我们通过计算网络输出相对于权重的梯度来实现这一点,不同于传统深度学习中的误差梯度。这让我们能校准随机变异,来更惊喜地处理最敏感的参数,也就解决了大型网络随机突变的主要问题。
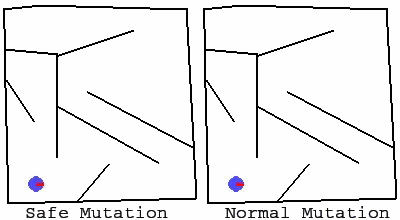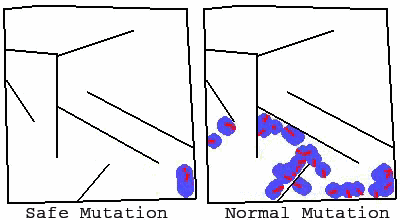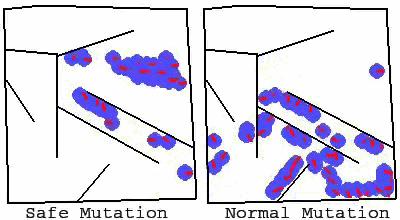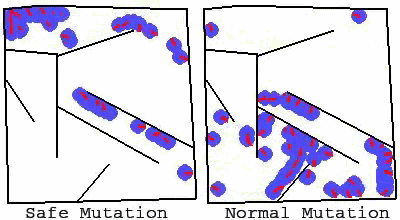
△ 两个动画分别显示了一个走迷宫(从左下角到左上角)的网络中的一组变异,普通变体大多不能到达终点,而安全变体基本上保留了这种能力,同时还产生了多样性,这说明安全变异具有显著优势。
ES和SGD的关系
我们有一篇论文对OpenAI首先提出的一个发现做了补充,这个发现是:神经元进化策略的变体可以在深度RL任务上对深度神经网络进行有竞争力的优化。然而到目前为止,这个结果仍然隐含着大量猜测。
为了给基于ES的进一步探索奠定基础,我们进行了全面的研究,检测了在MNIST上,ES梯度近似与SGD为每个mini-batch计算出的最佳梯度有多接近,以及这个近似值要有多接近才能表现良好。通过这些研究,我们更深入地探索了ES与SGD的关系。
研究显示,如果有足够的计算力来优化梯度近似,ES在MNIST上可以达到99%的准确率,这也暗示出了ES在深度强化学习中为什么越来越具有竞争力:随着计算力的增加,没有哪种方法能获得完美的梯度信息。
ES不只是传统有限差分
还有一项研究,在经验上证实了ES在有足够大的扰动参数时,行为与SGD不同,因为它为由概率分布描述的预期奖励而优化,而SGD为一个单独的策略而优化奖励,前者是搜索空间中的一个晕,而后者是搜索空间中的一个点。
这种不同,让ES会访问搜索空间中的不同区域,无论好坏。对一群参数扰动进行整体优化的另一个结果是,ES获得了SGD所不具备的奖状性特征。
强调ES对一群参数进行优化同样也凸显了ES和贝叶斯方法之间的联系。
△ 由TRPO学习的步行者权重发生随机扰动,导致它与ES演化出来的相同质量步行者发生随机扰动相比,步态明显更不稳定。每个九宫格中心显示的是原始的步行者。

△ 传统有限差分(梯度下降)不能跨越低适应性的窄沟,而ES能够轻松跨越它,到右侧寻找更高的适应性。

△ 当高适应性路径收窄时,ES迟疑了;而传统的有限差分(梯度下降)没有任何问题地穿过了相同的路径。这与上面的视频一起显示出了两种方法的差异和取舍。
增强ES中的探索
深度神经进化的研究带来了一个非常exciting的结果:为神经进化而开发的那些工具,现在成了加强深度神经网络训练的备选方法。
为抓住这个领域的机会,我们提出了一种新算法,将ES的优化能力和可扩展性,与专门用于神经进化的方法——激励一群agent用不同的方式行动来探索强化学习域两者结合起来。
后面这种基于群体的探索,与包括深度强化学习最新探索在内的传统单一agent强化学习方法不同。我们的实验表明,增加这种新型的探索,能在很多需要通过探索来避开欺骗性局部最优化的领域提高ES的性能,包括一些Atari游戏和Mujoco模拟器中的人形机器人动作任务。
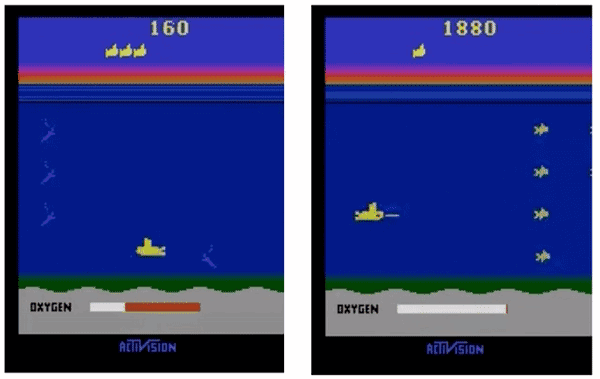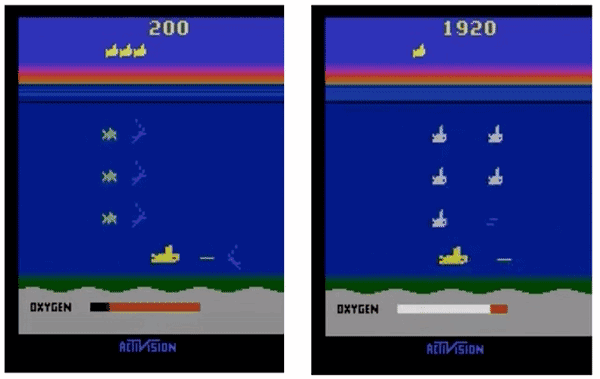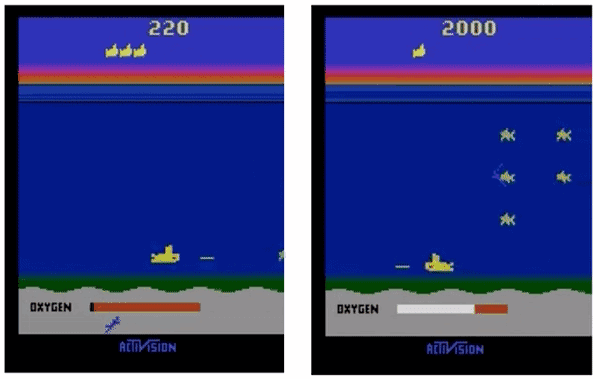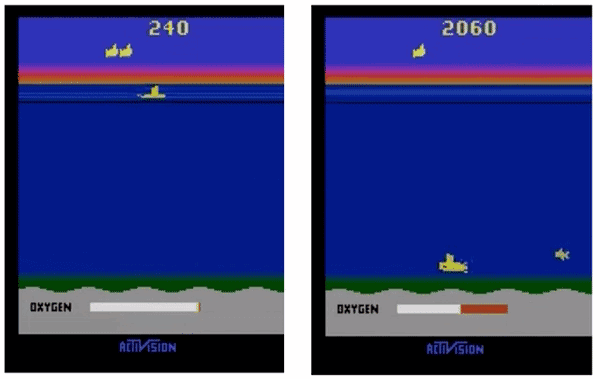
△ ES(左)和增加了探索方法的ES(右)
用我们的超参数设置,图左展示的ES会快速收敛到局部最优,agent不会暂时放弃奖励、上浮获取氧气。而加上探索方法之后,agent学会了浮到水面上获取氧气,从而在未来获取更多奖励。

△ 训练过程中的奖励
在没有探索方法的情况下,ES会无限期地卡在某个局部最优里面。
△ ES(左)和增加了探索方法的ES(右)
上图中agent的任务是往前跑得尽可能远。ES总是掉进陷阱里,而加上探索的压力之后,agent学会了绕过陷阱。

△ 训练过程中的奖励
结论
对想走近深度神经网络的神经进化研究者来说,有这几项重要的事情需要考虑:
首先,这类实验比过去所需要的计算力更高,上文所提及新论文中的实验,每次运行都同时用到了上百个、甚至上千个CPU。然而,这种对更多CPU或GPU的需求不应该被视作一种负担,从长远来看,将进化策略用到大规模平行计算中心所带来的简单程度,意味着神经进化可能是未来世界的最佳选择。
新结果和之前在低维神经进化中观察到的截然不同,它们有效地推翻了多年以来的直觉,特别是高维搜索的影响。
正如在深度学习中所发现的那样,在某种复杂性的门槛之上,高维上的搜索其实越来越容易,因为它不易受局部最优的影响。这种在深度学习领域广为人知的思考方式,正在神经进化领域开始慢慢被消化和理解。
神经进化的再度出现,也是旧算法和现代计算力良好结合的一个例子,神经进化的可行性很有意思,因为神经进化的研究群体已经开发出来的很多技术可以立即在DNN上规模化使用,每一种技术都为解决挑战性问题提供了不同的工具。
另外,正如我们在上述论文中提到的,神经进化的搜索方法与SGD不同,因此为机器学习提供了一种有趣的替代性工具。
我们想知道深度神经进化是否会像深度学习一样复兴,如果是这样,2017年可能就标志着这个时代的开端,我们也激动于看到今后还会发生什么。
今天我们发布的论文共有5篇,以下是它们的下载地址:
Deep Neuroevolution: Genetic Algorithms are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
http://eng.uber.com/wp-content/uploads/2017/12/deep-ga-arxiv.pdf
Safe Mutations for Deep and Recurrent Neural Networks through Output Gradients
http://eng.uber.com/wp-content/uploads/2017/12/arxiv-sm.pdf
On the Relationship Between the OpenAI Evolution Strategy and Stochastic Gradient Descent
http://eng.uber.com/wp-content/uploads/2017/12/ES_SGD.pdf
ES Is More Than Just a Traditional Finite Difference Approximator
http://eng.uber.com/wp-content/uploads/2017/12/arxiv-fd.pdf
Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
http://eng.uber.com/wp-content/uploads/2017/12/improving-es-arxiv.pdf
博客原文:
https://eng.uber.com/deep-neuroevolution/


