创建爬虫项目
scrapy startproject project
在抓取之前,你需要新建一个Scrapy工程
neo@MacBook-Pro ~/Documents % scrapy startproject crawler
New Scrapy project 'crawler', using template directory '/usr/local/lib/python3.6/site-packages/scrapy/templates/project', created in:
/Users/neo/Documents/crawler
You can start your first spider with:
cd crawler
scrapy genspider example example.com
neo@MacBook-Pro ~/Documents % cd crawler
neo@MacBook-Pro ~/Documents/crawler % find .
.
./crawler
./crawler/__init__.py
./crawler/__pycache__
./crawler/items.py
./crawler/middlewares.py
./crawler/pipelines.py
./crawler/settings.py
./crawler/spiders
./crawler/spiders/__init__.py
./crawler/spiders/__pycache__
./scrapy.cfg
Scrapy 工程目录主要有以下文件组成:
scrapy.cfg: 项目配置文件 middlewares.py : 项目 middlewares 文件 items.py: 项目items文件 pipelines.py: 项目管道文件 settings.py: 项目配置文件 spiders: 放置spider的目录
创建爬虫,名字是 netkiller, 爬行的地址是 netkiller.cn
neo@MacBook-Pro ~/Documents/crawler % scrapy genspider netkiller netkiller.cn Created spider 'netkiller' using template 'basic' in module: crawler.spiders.netkiller neo@MacBook-Pro ~/Documents/crawler % find . . ./crawler ./crawler/__init__.py ./crawler/__pycache__ ./crawler/__pycache__/__init__.cpython-36.pyc ./crawler/__pycache__/settings.cpython-36.pyc ./crawler/items.py ./crawler/middlewares.py ./crawler/pipelines.py ./crawler/settings.py ./crawler/spiders ./crawler/spiders/__init__.py ./crawler/spiders/__pycache__ ./crawler/spiders/__pycache__/__init__.cpython-36.pyc ./crawler/spiders/netkiller.py ./scrapy.cfg
打开 crawler/spiders/netkiller.py 文件,修改内容如下
# -*- coding: utf-8 -*-
import scrapy
class NetkillerSpider(scrapy.Spider):
name = 'netkiller'
allowed_domains = ['netkiller.cn']
start_urls = ['http://www.netkiller.cn/']
def parse(self, response):
for link in response.xpath('//div[@class="blockquote"]')[1].css('a.ulink'):
# self.log('This url is %s' % link)
yield {
'name': link.css('a::text').extract(),
'url': link.css('a.ulink::attr(href)').extract()
}
pass
运行爬虫
neo@MacBook-Pro ~/Documents/crawler % scrapy crawl netkiller -o output.json
2017-09-08 11:42:30 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: crawler)
2017-09-08 11:42:30 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'crawler', 'FEED_FORMAT': 'json', 'FEED_URI': 'output.json', 'NEWSPIDER_MODULE': 'crawler.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['crawler.spiders']}
2017-09-08 11:42:30 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2017-09-08 11:42:30 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-09-08 11:42:30 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-09-08 11:42:30 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-09-08 11:42:30 [scrapy.core.engine] INFO: Spider opened
2017-09-08 11:42:30 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-09-08 11:42:30 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-09-08 11:42:30 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.netkiller.cn/robots.txt> (referer: None)
2017-09-08 11:42:31 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.netkiller.cn/> (referer: None)
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Architect 手札'], 'url': ['../architect/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Developer 手札'], 'url': ['../developer/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller PHP 手札'], 'url': ['../php/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Python 手札'], 'url': ['../python/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Testing 手札'], 'url': ['../testing/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Java 手札'], 'url': ['../java/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Cryptography 手札'], 'url': ['../cryptography/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Linux 手札'], 'url': ['../linux/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller FreeBSD 手札'], 'url': ['../freebsd/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Shell 手札'], 'url': ['../shell/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Security 手札'], 'url': ['../security/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Web 手札'], 'url': ['../www/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Monitoring 手札'], 'url': ['../monitoring/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Storage 手札'], 'url': ['../storage/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Mail 手札'], 'url': ['../mail/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Docbook 手札'], 'url': ['../docbook/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Project 手札'], 'url': ['../project/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Database 手札'], 'url': ['../database/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller PostgreSQL 手札'], 'url': ['../postgresql/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller MySQL 手札'], 'url': ['../mysql/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller NoSQL 手札'], 'url': ['../nosql/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller LDAP 手札'], 'url': ['../ldap/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Network 手札'], 'url': ['../network/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Cisco IOS 手札'], 'url': ['../cisco/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller H3C 手札'], 'url': ['../h3c/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Multimedia 手札'], 'url': ['../multimedia/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Perl 手札'], 'url': ['../perl/index.html']}
2017-09-08 11:42:31 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.netkiller.cn/>
{'name': ['Netkiller Amateur Radio 手札'], 'url': ['../radio/index.html']}
2017-09-08 11:42:31 [scrapy.core.engine] INFO: Closing spider (finished)
2017-09-08 11:42:31 [scrapy.extensions.feedexport] INFO: Stored json feed (28 items) in: output.json
2017-09-08 11:42:31 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 438,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 6075,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 9, 8, 3, 42, 31, 157395),
'item_scraped_count': 28,
'log_count/DEBUG': 31,
'log_count/INFO': 8,
'memusage/max': 49434624,
'memusage/startup': 49434624,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 9, 8, 3, 42, 30, 931267)}
2017-09-08 11:42:31 [scrapy.core.engine] INFO: Spider closed (finished)
你会看到返回结果
{'name': ['Netkiller Architect 手札'], 'url': ['../architect/index.html']}
下面我们演示爬虫翻页,例如我们需要遍历这部电子书《Netkiller Linux 手札》 https://netkiller.cn/linux/index.html,首先创建一个爬虫任务
neo@MacBook-Pro ~/Documents/crawler % scrapy genspider book netkiller.cn Created spider 'book' using template 'basic' in module: crawler.spiders.book
编辑爬虫任务
# -*- coding: utf-8 -*-
import scrapy
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['netkiller.cn']
start_urls = ['https://netkiller.cn/linux/index.html']
def parse(self, response):
yield {'title': response.css('title::text').extract()}
# 这里取出下一页连接地址
next_page = response.xpath('//a[@accesskey="n"]/@href').extract_first()
self.log('Next page: %s' % next_page)
# 如果页面不为空交给 response.follow 来爬取这个页面
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
pass
下面的例子是将 response.body 返回采集内容保存到文件中
# -*- coding: utf-8 -*-
import scrapy
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['netkiller.cn']
start_urls = ['https://netkiller.cn/linux/index.html']
def parse(self, response):
yield {'title': response.css('title::text').extract()}
filename = '/tmp/%s' % response.url.split("/")[-1]
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
next_page = response.xpath('//a[@accesskey="n"]/@href').extract_first()
self.log('Next page: %s' % next_page)
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
pass
任务运维结束后查看采集出来的文件
neo@MacBook-Pro ~/Documents/crawler % ls /tmp/*.html /tmp/apt-get.html /tmp/disc.html /tmp/infomation.html /tmp/lspci.html /tmp/svgatextmode.html /tmp/aptitude.html /tmp/dmidecode.html /tmp/install.html /tmp/lsscsi.html /tmp/swap.html /tmp/author.html /tmp/do-release-upgrade.html /tmp/install.partition.html /tmp/lsusb.html /tmp/sys.html /tmp/avlinux.html /tmp/dpkg.html /tmp/introduction.html /tmp/package.html /tmp/sysctl.html /tmp/centos.html /tmp/du.max-depth.html /tmp/kernel.html /tmp/pr01s02.html /tmp/system.infomation.html /tmp/cfdisk.html /tmp/ethtool.html /tmp/kernel.modules.html /tmp/pr01s03.html /tmp/system.profile.html /tmp/console.html /tmp/framebuffer.html /tmp/kudzu.html /tmp/pr01s05.html /tmp/system.shutdown.html /tmp/console.timeout.html /tmp/gpt.html /tmp/linux.html /tmp/preface.html /tmp/tune2fs.html /tmp/dd.clone.html /tmp/hdd.label.html /tmp/locale.html /tmp/proc.html /tmp/udev.html /tmp/deb.html /tmp/hdd.partition.html /tmp/loop.html /tmp/rpm.html /tmp/upgrades.html /tmp/device.cpu.html /tmp/hwinfo.html /tmp/lsblk.html /tmp/rpmbuild.html /tmp/yum.html /tmp/device.hba.html /tmp/index.html /tmp/lshw.html /tmp/smartctl.html
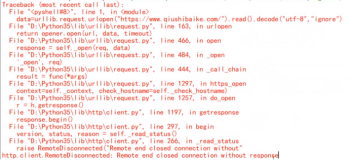
这里只是做演示,生产环境请不要在 parse(self, response) 中处理,后面会讲到 Pipeline。
Item 在 scrapy 中的类似“实体”或者“POJO”的概念,是一个数据结构类。爬虫通过ItemLoader将数据放到Item中
下面是 items.py 文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CrawlerItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
ctime = scrapy.Field()
pass
下面是爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.loader import ItemLoader
from crawler.items import CrawlerItem
import time
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['netkiller.cn']
start_urls = ['https://netkiller.cn/java/index.html']
def parse(self, response):
item_selector = response.xpath('//a/@href')
for url in item_selector.extract():
if 'html' in url.split('.'):
url = response.urljoin(url)
yield response.follow( url, callback=self.parse_item)
next_page = response.xpath('//a[@accesskey="n"]/@href').extract_first()
self.log('Next page: %s' % next_page)
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
def parse_item(self, response):
l = ItemLoader(item=CrawlerItem(), response=response)
l.add_css('title', 'title::text')
l.add_value('ctime', time.strftime( '%Y-%m-%d %X', time.localtime() ))
l.add_value('content', response.body)
return l.load_item()
yield response.follow( url, callback=self.parse_item) 会回调 parse_item(self, response) 将爬到的数据放置到 Item 中
Pipeline 管道线,主要的功能是对 Item 的数据处理,例如计算、合并等等。通常我们在这里做数据保存。下面的例子是将爬到的数据保存到 json 文件中。
默认情况 Pipeline 是禁用的,首先我们需要开启 Pipeline 支持,修改 settings.py 文件,找到下面配置项,去掉注释。
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'crawler.pipelines.CrawlerPipeline': 300,
}
修改 pipelines.py 文件。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class CrawlerPipeline(object):
def open_spider(self, spider):
self.file = open('items.json', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
# self.log("PIPE: %s" % item)
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
下面是 items.py 文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CrawlerItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
ctime = scrapy.Field()
pass
下面是爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.loader import ItemLoader
from crawler.items import CrawlerItem
import time
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['netkiller.cn']
start_urls = ['https://netkiller.cn/java/index.html']
def parse(self, response):
item_selector = response.xpath('//a/@href')
for url in item_selector.extract():
if 'html' in url.split('.'):
url = response.urljoin(url)
yield response.follow( url, callback=self.parse_item)
next_page = response.xpath('//a[@accesskey="n"]/@href').extract_first()
self.log('Next page: %s' % next_page)
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
def parse_item(self, response):
l = ItemLoader(item=CrawlerItem(), response=response)
l.add_css('title', 'title::text')
l.add_value('ctime', time.strftime( '%Y-%m-%d %X', time.localtime() ))
l.add_value('content', response.body)
return l.load_item()
items.json 文件如下
{"title": ["5.31.\u00a0Spring boot with Data restful"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.30.\u00a0Spring boot with Phoenix"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.29.\u00a0Spring boot with Apache Hive"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.28.\u00a0Spring boot with Elasticsearch 5.5.x"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.27.\u00a0Spring boot with Elasticsearch 2.x"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.23.\u00a0Spring boot with Hessian"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.22.\u00a0Spring boot with Cache"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.26.\u00a0Spring boot with HTTPS SSL"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.25.\u00a0Spring boot with Git version"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.24.\u00a0Spring boot with Apache Kafka"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.21.\u00a0Spring boot with Scheduling"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.20.\u00a0Spring boot with Oauth2"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.19.\u00a0Spring boot with Spring security"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.16.\u00a0Spring boot with PostgreSQL"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.18.\u00a0Spring boot with Velocity template"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.13.\u00a0Spring boot with MongoDB"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.11.\u00a0Spring boot with Session share"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.17.\u00a0Spring boot with Email"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.15.\u00a0Spring boot with Oracle"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.14.\u00a0Spring boot with MySQL"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.10.\u00a0Spring boot with Logging"], "ctime": ["2017-09-11 11:57:53"]}
{"title": ["5.9.\u00a0String boot with RestTemplate"], "ctime": ["2017-09-11 11:57:53"]}
原文出处:Netkiller 系列 手札
本文作者:陈景峯
转载请与作者联系,同时请务必标明文章原始出处和作者信息及本声明。