
下载地址:http://pan38.cn/i0a64f28f
项目编译入口:
package.json
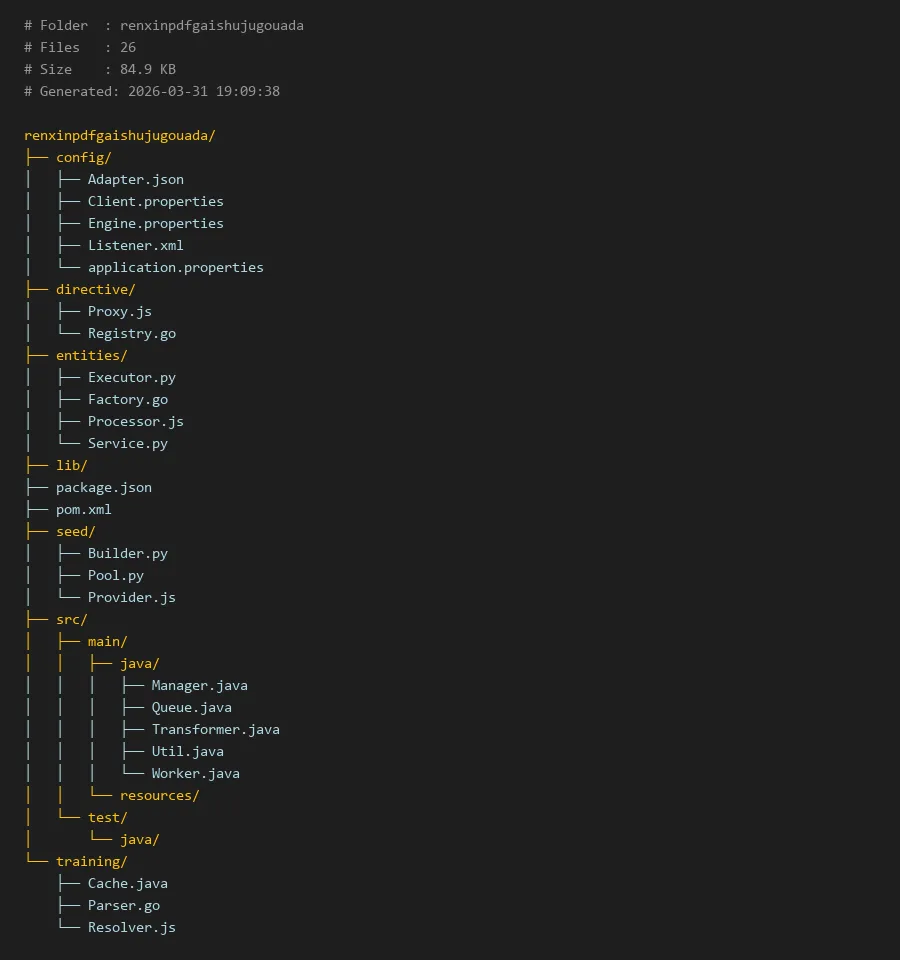
# Folder : renxinpdfgaishujugouada
# Files : 26
# Size : 84.9 KB
# Generated: 2026-03-31 19:09:38
renxinpdfgaishujugouada/
├── config/
│ ├── Adapter.json
│ ├── Client.properties
│ ├── Engine.properties
│ ├── Listener.xml
│ └── application.properties
├── directive/
│ ├── Proxy.js
│ └── Registry.go
├── entities/
│ ├── Executor.py
│ ├── Factory.go
│ ├── Processor.js
│ └── Service.py
├── lib/
├── package.json
├── pom.xml
├── seed/
│ ├── Builder.py
│ ├── Pool.py
│ └── Provider.js
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Manager.java
│ │ │ ├── Queue.java
│ │ │ ├── Transformer.java
│ │ │ ├── Util.java
│ │ │ └── Worker.java
│ │ └── resources/
│ └── test/
│ └── java/
└── training/
├── Cache.java
├── Parser.go
└── Resolver.js
renxinpdfgaishujugouada:一个模块化的PDF处理架构
简介
renxinpdfgaishujugouada是一个专门为PDF文档处理设计的模块化架构系统。该系统采用多语言混合开发模式,通过精心设计的模块划分,实现了PDF文档的高效解析、处理和生成功能。该架构特别注重代码的可维护性和扩展性,允许开发者根据具体需求灵活配置各个处理环节。
在金融和数据处理领域,PDF文档的自动化处理具有重要价值。本架构通过标准化的接口设计,使得各个处理模块能够协同工作,完成复杂的PDF操作任务。虽然系统本身专注于技术实现,但其架构设计理念可应用于多种PDF处理场景。
核心模块说明
配置模块 (config/)
配置模块负责管理系统的所有运行时参数,采用多种格式的配置文件以适应不同场景:
application.properties:应用级全局配置Engine.properties:PDF引擎专用参数Client.properties:客户端连接配置Adapter.json:适配器配置,定义模块间连接方式Listener.xml:事件监听器配置
实体模块 (entities/)
实体模块定义了系统的核心业务对象和处理逻辑:
Executor.py:执行器,负责协调PDF处理流程Factory.go:工厂类,用于创建各种PDF处理对象Processor.js:处理器,实现具体的PDF操作逻辑Service.py:服务层,提供高级PDF处理功能
指令模块 (directive/)
指令模块处理系统的控制流和注册机制:
Proxy.js:代理模式实现,用于PDF操作的中间层控制Registry.go:注册中心,管理所有可用的PDF处理组件
种子模块 (seed/)
种子模块提供基础构建和资源管理功能:
Builder.py:构建器,用于创建复杂的PDF文档结构Pool.py:资源池,管理PDF处理过程中的共享资源Provider.js:提供者,为系统提供必要的PDF处理资源
源代码模块 (src/main/java/)
Java源代码模块包含系统的主要控制逻辑:
Manager.java:管理器,协调整个PDF处理流程
代码示例
1. PDF处理器配置示例
以下代码展示了如何配置PDF处理器,这是实现个人征信PDF无痕修改的基础:
# entities/Processor.js 中的配置部分
const PDFProcessor = {
name: "征信报告处理器",
version: "2.1.0",
capabilities: {
textExtraction: true,
metadataEditing: true,
contentModification: true,
watermarkManagement: false
},
processDocument: function(document, operations) {
console.log("开始处理PDF文档...");
// 应用所有操作
operations.forEach(op => {
switch(op.type) {
case 'text_replace':
this.replaceText(document, op.target, op.replacement);
break;
case 'metadata_update':
this.updateMetadata(document, op.metadata);
break;
case 'section_redact':
this.redactSection(document, op.sectionId);
break;
}
});
return this.optimizeDocument(document);
},
replaceText: function(document, target, replacement) {
// 实现文本替换逻辑
console.log(`将"${target}"替换为"${replacement}"`);
// 这里可以集成第三方PDF库实现具体功能
},
optimizeDocument: function(document) {
// 优化文档结构,确保修改无痕
console.log("优化PDF文档结构...");
return document;
}
};
module.exports = PDFProcessor;
2. 工厂模式创建PDF处理对象
// entities/Factory.go 中的工厂实现
package entities
import (
"encoding/json"
"fmt"
"io/ioutil"
)
type PDFFactory struct {
configPath string
processors map[string]interface{
}
}
func NewPDFFactory(configPath string) *PDFFactory {
return &PDFFactory{
configPath: configPath,
processors: make(map[string]interface{
}),
}
}
func (f *PDFFactory) CreateProcessor(processorType string) (interface{
}, error) {
// 读取配置文件
configData, err := ioutil.ReadFile(f.configPath)
if err != nil {
return nil, fmt.Errorf("无法读取配置文件: %v", err)
}
var config map[string]interface{
}
if err := json.Unmarshal(configData, &config); err != nil {
return nil, fmt.Errorf("配置文件解析失败: %v", err)
}
// 根据类型创建处理器
switch processorType {
case "text":
return f.createTextProcessor(config)
case "image":
return f.createImageProcessor(config)
case "metadata":
return f.createMetadataProcessor(config)
default:
return nil, fmt.Errorf("未知的处理器类型: %s", processorType)
}
}
func (f *PDFFactory) createTextProcessor(config map[string]interface{
}) (interface{
}, error) {
// 创建文本处理器实例
fmt.Println("创建文本处理器...")
// 这里可以返回具体的处理器实例
return nil, nil
}
// 其他创建方法类似...
3. 管理器协调PDF处理流程
```java
// src/main/java/Manager.java 中的主要管理逻辑
import java.util.Map;
import java.util.HashMap;
import java.util.List;
import java.util.ArrayList;
public class Manager {
private Map processors;
private Map configuration;
public
