
下载地址:http://pan38.cn/id458f478
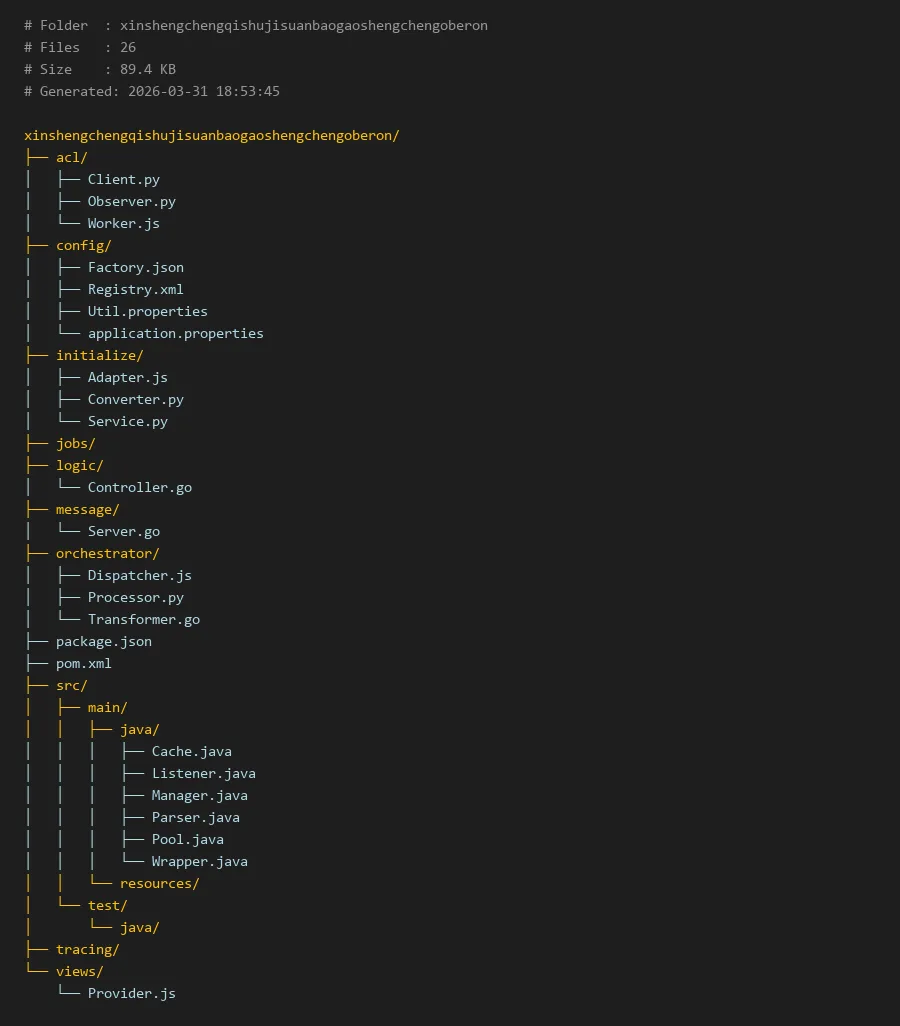
项目编译入口:
package.json
# Folder : xinshengchengqishujisuanbaogaoshengchengoberon
# Files : 26
# Size : 89.4 KB
# Generated: 2026-03-31 18:53:45
xinshengchengqishujisuanbaogaoshengchengoberon/
├── acl/
│ ├── Client.py
│ ├── Observer.py
│ └── Worker.js
├── config/
│ ├── Factory.json
│ ├── Registry.xml
│ ├── Util.properties
│ └── application.properties
├── initialize/
│ ├── Adapter.js
│ ├── Converter.py
│ └── Service.py
├── jobs/
├── logic/
│ └── Controller.go
├── message/
│ └── Server.go
├── orchestrator/
│ ├── Dispatcher.js
│ ├── Processor.py
│ └── Transformer.go
├── package.json
├── pom.xml
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Cache.java
│ │ │ ├── Listener.java
│ │ │ ├── Manager.java
│ │ │ ├── Parser.java
│ │ │ ├── Pool.java
│ │ │ └── Wrapper.java
│ │ └── resources/
│ └── test/
│ └── java/
├── tracing/
└── views/
└── Provider.js
xinshengchengqishujisuanbaogaoshengchengoberon:一个多语言征信生成器技术实现
简介
在当今数据驱动的金融科技领域,生成符合业务规范的模拟数据对于系统开发和测试至关重要。xinshengchengqishujisuanbaogaoshengchengoberon项目(以下简称"征信生成器")正是为此而生——它是一个多语言协同工作的征信报告生成系统,能够高效、灵活地产生结构化的征信数据。该项目巧妙地将Python、JavaScript和Go语言的优势结合起来,通过模块化设计实现了数据生成、转换和分发的完整流程。
这个征信生成器的核心价值在于其可配置性和扩展性。通过配置文件驱动,用户可以根据不同地区的征信规范调整生成规则,而多语言架构则确保了系统能够适应各种技术栈环境。无论是用于开发测试、压力测试还是演示环境,这个工具都能提供高质量的模拟数据。
核心模块说明
项目采用分层架构设计,各模块职责清晰:
配置层(config/):存放所有配置文件,包括JSON、XML和Properties格式,支持灵活的规则配置。
初始化层(initialize/):负责系统启动时的适配、转换和服务初始化工作。
业务逻辑层(logic/):包含核心的业务处理逻辑,特别是征信数据的生成算法。
编排层(orchestrator/):协调各个组件的工作流程,包括任务分发、数据处理和格式转换。
访问控制层(acl/):处理客户端连接、观察者模式和工作者管理。
消息层(message/):负责系统内部和外部的消息通信。
代码示例
1. 配置管理模块
首先让我们看看配置模块如何工作。Factory.json定义了征信数据生成的模板:
{
"credit_report_templates": {
"personal_info": {
"name": "{
{random.chinese_name}}",
"id_number": "{
{random.id_card}}",
"age_range": [20, 65]
},
"credit_history": {
"loan_count": {
"min": 0, "max": 15},
"default_rate": {
"min": 0.0, "max": 0.3},
"credit_score_range": [300, 850]
},
"query_reasons": [
"贷款审批",
"信用卡审批",
"贷后管理",
"本人查询"
]
},
"generation_rules": {
"batch_size": 100,
"concurrent_workers": 5,
"output_format": "json"
}
}
Util.properties包含工具类配置:
# 征信生成器核心配置
data.source=simulated
validation.enabled=true
logging.level=INFO
cache.enabled=true
cache.ttl=3600
# 多语言协调设置
python.entry=orchestrator/Processor.py
js.entry=orchestrator/Dispatcher.js
go.entry=logic/Controller.go
2. 业务逻辑控制器
logic/Controller.go展示了征信生成的核心逻辑:
package logic
import (
"encoding/json"
"math/rand"
"time"
)
type CreditReport struct {
ReportID string `json:"report_id"`
PersonalInfo Person `json:"personal_info"`
CreditScore int `json:"credit_score"`
Loans []Loan `json:"loans"`
QueryRecords []Query `json:"query_records"`
GeneratedAt time.Time `json:"generated_at"`
}
type Person struct {
Name string `json:"name"`
IDNumber string `json:"id_number"`
Age int `json:"age"`
}
type CreditController struct {
config map[string]interface{
}
}
func NewCreditController(configPath string) *CreditController {
return &CreditController{
config: loadConfig(configPath),
}
}
func (cc *CreditController) GenerateReport(userID string) (string, error) {
report := CreditReport{
ReportID: generateReportID(),
CreditScore: cc.generateCreditScore(),
GeneratedAt: time.Now(),
}
// 生成个人信息
report.PersonalInfo = cc.generatePersonalInfo()
// 生成贷款记录
report.Loans = cc.generateLoanHistory()
// 生成查询记录
report.QueryRecords = cc.generateQueryRecords()
// 转换为JSON
jsonData, err := json.MarshalIndent(report, "", " ")
if err != nil {
return "", err
}
return string(jsonData), nil
}
func (cc *CreditController) generateCreditScore() int {
baseScore := 600
variation := rand.Intn(250) - 50
return baseScore + variation
}
func (cc *CreditController) generatePersonalInfo() Person {
names := []string{
"张三", "李四", "王五", "赵六", "钱七"}
return Person{
Name: names[rand.Intn(len(names))],
IDNumber: generateIDNumber(),
Age: 25 + rand.Intn(40),
}
}
3. 流程编排器
orchestrator/Dispatcher.js负责任务分发:
```javascript
const { Worker } = require('worker_threads');
const path = require('path');
class CreditReportDispatcher {
constructor(config) {
this.config = config;
this.workers = [];
this.maxWorkers = config.concurrent_workers || 3;
}
async dispatchGeneration

