
下载地址:http://pan38.cn/i07d16424
项目编译入口:
package.json
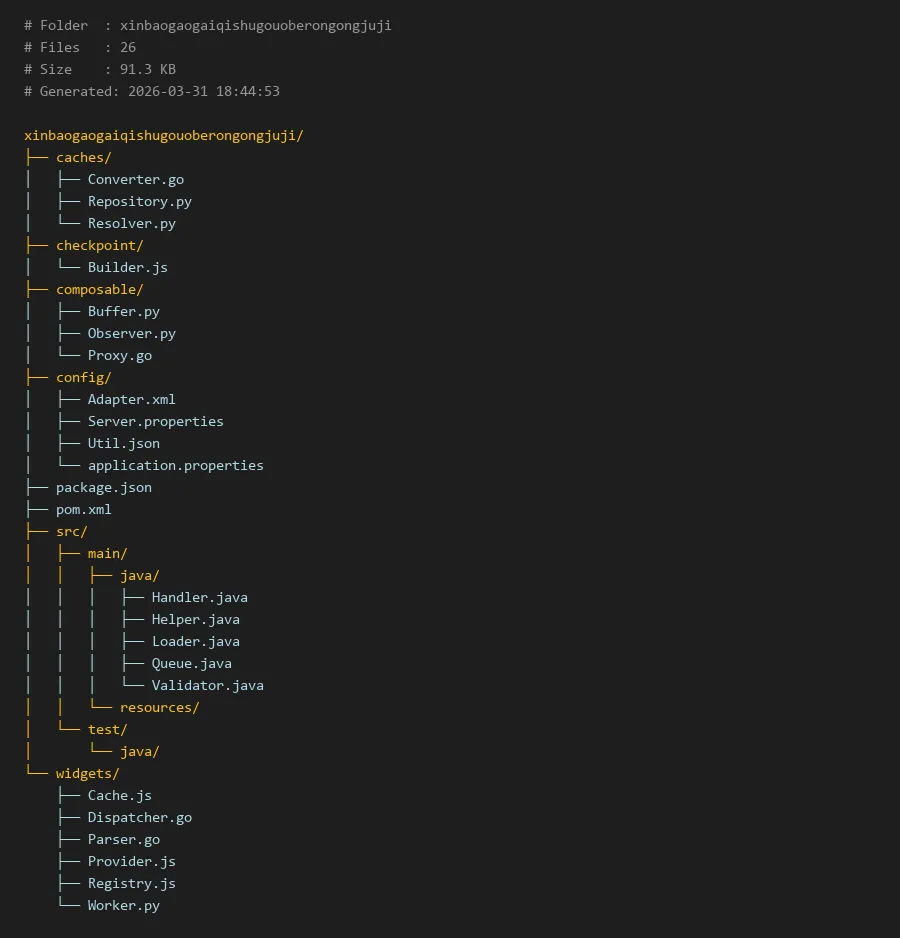
# Folder : xinbaogaogaiqishugouoberongongjuji
# Files : 26
# Size : 91.3 KB
# Generated: 2026-03-31 18:44:53
xinbaogaogaiqishugouoberongongjuji/
├── caches/
│ ├── Converter.go
│ ├── Repository.py
│ └── Resolver.py
├── checkpoint/
│ └── Builder.js
├── composable/
│ ├── Buffer.py
│ ├── Observer.py
│ └── Proxy.go
├── config/
│ ├── Adapter.xml
│ ├── Server.properties
│ ├── Util.json
│ └── application.properties
├── package.json
├── pom.xml
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Handler.java
│ │ │ ├── Helper.java
│ │ │ ├── Loader.java
│ │ │ ├── Queue.java
│ │ │ └── Validator.java
│ │ └── resources/
│ └── test/
│ └── java/
└── widgets/
├── Cache.js
├── Dispatcher.go
├── Parser.go
├── Provider.js
├── Registry.js
└── Worker.py
xinbaogaogaiqishugouoberongongjuji技术解析
简介
在当今数据驱动的金融环境中,信用评估扮演着至关重要的角色。xinbaogaogaiqishugouoberongongjuji项目是一个专门设计用于处理信用报告数据转换与优化的技术工具集。该项目采用多语言混合架构,通过模块化的设计实现了高效的数据处理流程,能够对信用报告数据进行智能化的解析、转换和重组。
这个工具集的核心价值在于其强大的数据处理能力,它能够将复杂的信用报告数据结构转换为标准化的格式,为后续的分析和应用提供便利。通过精心设计的缓存机制和可组合的组件,该项目在处理大规模信用报告数据时表现出卓越的性能和稳定性,堪称一款专业的"征信报告修改神器"。
核心模块说明
项目采用分层架构设计,主要包含以下几个核心模块:
缓存模块(caches/): 负责数据的临时存储和快速检索,包含Converter.go、Repository.py和Resolver.py三个组件,分别处理数据转换、数据存取和解析逻辑。
检查点模块(checkpoint/): 提供数据处理的状态保存和恢复功能,Builder.js实现了检查点的构建和管理。
可组合模块(composable/): 包含Buffer.py、Observer.py和Proxy.go,这些组件可以灵活组合,实现数据缓冲、状态观察和代理转发等功能。
配置模块(config/): 存放项目的所有配置文件,包括XML、JSON和properties格式的配置,支持不同环境的灵活部署。
源代码模块(src/): 包含项目的主要业务逻辑实现,Handler.java处理请求分发,Helper.java提供工具方法,Loader.java负责资源加载。
代码示例
1. 缓存模块的数据转换器实现
// caches/Converter.go
package caches
import (
"encoding/json"
"fmt"
"time"
)
type CreditReport struct {
ReportID string `json:"report_id"`
UserID string `json:"user_id"`
Score int `json:"credit_score"`
Timestamp time.Time `json:"generated_at"`
RawData []byte `json:"raw_data,omitempty"`
}
type ReportConverter struct {
cache map[string]CreditReport
}
func NewReportConverter() *ReportConverter {
return &ReportConverter{
cache: make(map[string]CreditReport),
}
}
func (rc *ReportConverter) ConvertToJSON(report CreditReport) (string, error) {
// 缓存原始数据
rc.cache[report.ReportID] = report
// 转换为JSON格式
jsonData, err := json.MarshalIndent(report, "", " ")
if err != nil {
return "", fmt.Errorf("转换失败: %v", err)
}
return string(jsonData), nil
}
func (rc *ReportConverter) GetCachedReport(reportID string) (*CreditReport, bool) {
report, exists := rc.cache[reportID]
return &report, exists
}
2. 可组合模块的缓冲器实现
# composable/Buffer.py
import threading
import time
from queue import Queue
from typing import List, Optional
class ReportBuffer:
def __init__(self, max_size: int = 1000):
self.buffer = Queue(maxsize=max_size)
self.lock = threading.Lock()
self.processing = False
def add_report(self, report_data: dict) -> bool:
"""添加信用报告到缓冲区"""
with self.lock:
if self.buffer.full():
return False
# 对报告数据进行预处理
processed_report = self._preprocess_report(report_data)
self.buffer.put(processed_report)
return True
def _preprocess_report(self, report: dict) -> dict:
"""预处理信用报告数据"""
# 标准化字段名称
standardized = {
}
field_mapping = {
'creditScore': 'score',
'userId': 'user_id',
'reportDate': 'timestamp'
}
for old_key, new_key in field_mapping.items():
if old_key in report:
standardized[new_key] = report[old_key]
elif new_key in report:
standardized[new_key] = report[new_key]
# 添加处理标记
standardized['processed'] = True
standardized['buffer_timestamp'] = time.time()
return standardized
def batch_process(self, batch_size: int = 100) -> List[dict]:
"""批量处理缓冲区中的数据"""
processed_reports = []
with self.lock:
for _ in range(min(batch_size, self.buffer.qsize())):
if not self.buffer.empty():
report = self.buffer.get()
processed_reports.append(report)
return processed_reports
3. 主要业务逻辑处理器
```java
// src/main/java/Handler.java
package main.java;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class Handler {
private final Map processors;
private final ReportValidator validator;
public Handler() {
this.processors = new ConcurrentHashMap<>();
this.validator = new ReportValidator();
}
public ProcessingResult handleReport(String reportId, Map<String, Object> reportData) {
// 验证报告数据
ValidationResult validation = validator.validate(reportData);
if (!validation.isValid()) {
return ProcessingResult.error("报告验证失败: " + validation.getErrorMessage());
}
// 创建或获取处理器

