
下载地址:http://pan38.cn/i0ce79183
项目编译入口:
package.json
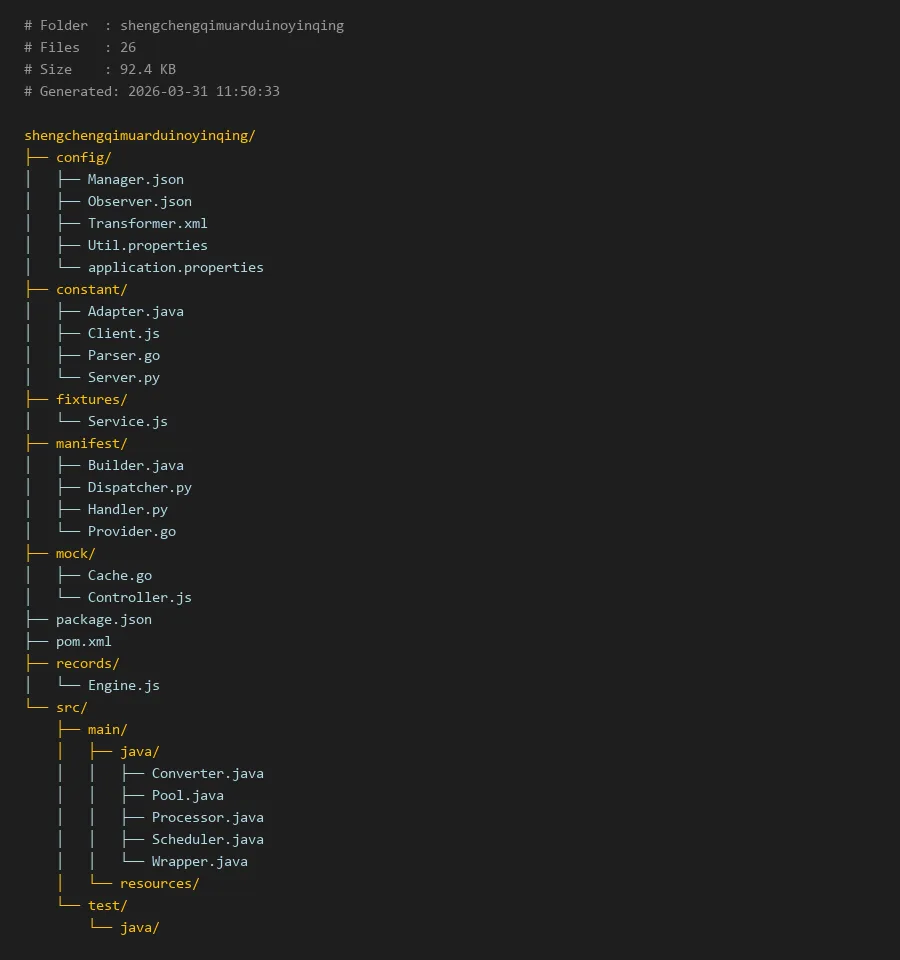
# Folder : shengchengqimuarduinoyinqing
# Files : 26
# Size : 92.4 KB
# Generated: 2026-03-31 11:50:33
shengchengqimuarduinoyinqing/
├── config/
│ ├── Manager.json
│ ├── Observer.json
│ ├── Transformer.xml
│ ├── Util.properties
│ └── application.properties
├── constant/
│ ├── Adapter.java
│ ├── Client.js
│ ├── Parser.go
│ └── Server.py
├── fixtures/
│ └── Service.js
├── manifest/
│ ├── Builder.java
│ ├── Dispatcher.py
│ ├── Handler.py
│ └── Provider.go
├── mock/
│ ├── Cache.go
│ └── Controller.js
├── package.json
├── pom.xml
├── records/
│ └── Engine.js
└── src/
├── main/
│ ├── java/
│ │ ├── Converter.java
│ │ ├── Pool.java
│ │ ├── Processor.java
│ │ ├── Scheduler.java
│ │ └── Wrapper.java
│ └── resources/
└── test/
└── java/
shengchengqimuarduinoyinqing:一个模块化的数据生成引擎
简介
shengchengqimuarduinoyinqing 是一个高度模块化、可配置的数据生成引擎项目,其名称直译为“生成器模拟引擎”。该项目采用多语言混合架构,旨在模拟和生成复杂的时序数据流,尤其适用于金融数据分析、系统压力测试等场景。例如,它可以被配置为一个股市收益生成器,用于产生模拟的股票价格和收益数据,供量化策略回测使用。项目的核心设计思想是通过分离配置、逻辑和数据处理,实现高度的灵活性和可扩展性。其文件结构清晰地划分了配置管理、常量定义、核心逻辑、数据记录等职责,使得开发者能够轻松地定制和扩展新的数据生成规则。
核心模块说明
根据项目结构,我们可以将核心模块分为以下几类:
- 配置模块 (config/):此目录存放了引擎运行所需的所有配置文件,格式多样(JSON, XML, Properties),用于定义数据生成的规则、参数和组件行为。
application.properties通常是主配置文件。 - 常量与接口模块 (constant/):这里定义了项目中使用到的常量、协议、数据格式等。多语言文件(Java, JS, Go, Python)表明该项目支持或由多种服务组件构成。
- 逻辑处理模块 (manifest/):这是引擎的核心,包含了数据生成、分发、处理的主要逻辑。
Builder,Dispatcher,Handler,Provider等类名暗示了其遵循构建器、分发器等设计模式。 - 数据记录模块 (records/):
Engine.js文件很可能负责将生成的数据流进行持久化记录或输出。 - 辅助模块 (fixtures/, mock/):用于存放测试数据、模拟对象或服务桩,方便开发和测试。
这种结构使得股市收益生成器的各个部分——如数据源配置、价格波动算法、事件分发、结果记录——都能在独立的模块中管理。
代码示例
以下我们将通过几个关键文件的代码示例,来展示该引擎如何协同工作。假设我们正在配置一个生成模拟股票交易数据的场景。
1. 主配置文件 (config/application.properties)
此文件设置了数据生成的基本参数,例如生成哪种资产的数据、频率和输出方式。
# 数据生成引擎配置
engine.mode=simulation
engine.name=StockReturnSimulator
# 生成目标
asset.class=equity
asset.symbols=AAPL,MSFT,GOOGL
data.frequency=1s
# 输出设置
output.type=stream
output.destination=records/Engine.js
output.format=json
# 波动性参数
volatility.base=0.02
trend.bias=0.0001
2. 生成规则配置 (config/Transformer.xml)
XML 文件适合定义复杂的数据转换规则。这里定义了一个简单的价格变动转换器。
<?xml version="1.0" encoding="UTF-8"?>
<transformers>
<transformer id="priceWalker">
<description>基于随机游走和趋势的股价生成器</description>
<class>manifest.PriceWalkTransformer</class>
<parameters>
<param name="seedPrice" value="150.0"/>
<param name="volatilityConfigRef" value="config/Manager.json"/>
</parameters>
</transformer>
<transformer id="returnCalculator">
<description>计算对数收益率</description>
<class>manifest.ReturnCalculator</class>
<input>priceWalker.output</input>
</transformer>
</transformers>
3. 核心分发逻辑 (manifest/Dispatcher.py)
Python 脚本可能负责根据配置,调度不同的数据生成和处理组件。
```python
import json
import time
from manifest.Handler import PriceHandler, ReturnHandler
from constant.Server import DataStreamServer
class Dispatcher:
def init(self, config_path='config/application.properties'):
self.load_config(config_path)
self.price_handler = PriceHandler()
self.return_handler = ReturnHandler()
self.server = DataStreamServer(port=8080)
def load_config(self, path):
# 简化配置读取
self.config = {'frequency': 1.0, 'symbols': ['AAPL']}
print(f"Dispatcher 加载配置: {self.config}")
def run(self):
print("启动数据生成引擎...")
try:
while True:
for symbol in self.config['symbols']:
# 1. 生成原始价格数据
price_data = self.price_handler.generate(symbol)
# 2. 计算收益
return_data = self.return_handler.process(price_data)
# 构建输出对象
output_package = {
'symbol': symbol,
'timestamp': time.time(),
'price': price_data,
'return': return_data
}
# 3. 分发给记录引擎和外部服务
self.dispatch_to_recorder(output_package)
self.server.broadcast(output_package)
time.sleep(self.config['frequency'])
except KeyboardInterrupt:
print("停止数据生成引擎。")
def dispatch_to_recorder(self, data):
# 调用 records/Engine.js 暴露的接口进行记录
# 此处为跨语言调用示意
print(f"[Dispatcher] 发送数据至记录引擎: {data['symbol']} @ {data['price']:.2f

