
下载地址:http://pan38.cn/i8b10d897
项目编译入口:
package.json
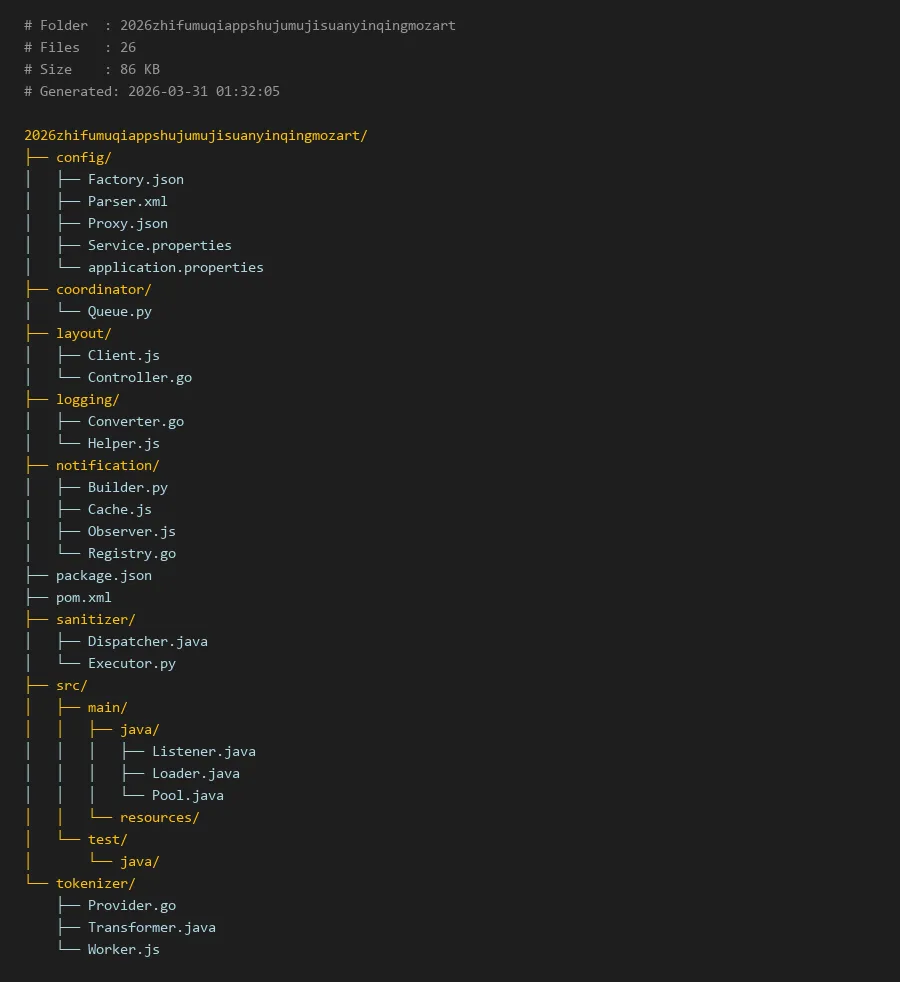
# Folder : 2026zhifumuqiappshujumujisuanyinqingmozart
# Files : 26
# Size : 86 KB
# Generated: 2026-03-31 01:32:05
2026zhifumuqiappshujumujisuanyinqingmozart/
├── config/
│ ├── Factory.json
│ ├── Parser.xml
│ ├── Proxy.json
│ ├── Service.properties
│ └── application.properties
├── coordinator/
│ └── Queue.py
├── layout/
│ ├── Client.js
│ └── Controller.go
├── logging/
│ ├── Converter.go
│ └── Helper.js
├── notification/
│ ├── Builder.py
│ ├── Cache.js
│ ├── Observer.js
│ └── Registry.go
├── package.json
├── pom.xml
├── sanitizer/
│ ├── Dispatcher.java
│ └── Executor.py
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Listener.java
│ │ │ ├── Loader.java
│ │ │ └── Pool.java
│ │ └── resources/
│ └── test/
│ └── java/
└── tokenizer/
├── Provider.go
├── Transformer.java
└── Worker.js
2026zhifumuqiappshujumujisuanyinqingmozart:高仿支付宝模拟器的数据聚合计算引擎
简介
2026zhifumuqiappshujumujisuanyinqingmozart(以下简称Mozart引擎)是一个专为金融模拟应用设计的分布式数据聚合与计算引擎。该引擎的核心目标是为"2026高仿支付宝模拟器app"提供高性能、可扩展的交易数据处理能力,支持实时风控、用户行为分析和模拟交易结算等复杂业务场景。
Mozart引擎采用微服务架构设计,通过模块化的组件实现数据流水线处理。项目包含配置管理、任务协调、界面布局、日志处理、通知系统和数据清洗等核心模块,使用多种编程语言混合开发以充分发挥各语言在特定领域的优势。引擎名称中的"mozart"寓意系统像莫扎特的音乐一样,各个模块和谐协作,处理复杂数据流时展现出优雅与高效。
核心模块说明
配置管理模块 (config/)
该模块集中管理所有运行时配置,支持多种格式的配置文件。Factory.json定义对象工厂配置,Parser.xml配置数据解析规则,Proxy.json设置网络代理,Service.properties定义微服务参数,application.properties为全局应用配置。
任务协调模块 (coordinator/)
Queue.py实现分布式任务队列,负责调度计算任务,确保高并发场景下的任务顺序执行和负载均衡。
界面布局模块 (layout/)
Client.js提供前端数据绑定服务,Controller.go实现业务逻辑控制层,两者协同为"2026高仿支付宝模拟器app"提供响应式界面支持。
日志处理模块 (logging/)
Converter.go负责日志格式转换,Helper.js提供日志工具函数,支持结构化日志和实时日志分析。
通知系统模块 (notification/)
这是最复杂的模块之一,包含观察者模式实现(Observer.js)、缓存管理(Cache.js)、消息构建(Builder.py)和服务注册(Registry.go),确保系统状态变更能及时通知所有相关组件。
数据清洗模块 (sanitizer/)
Dispatcher.java作为数据清洗调度器,负责将原始交易数据分发到不同的清洗管道,确保输入计算引擎的数据质量。
代码示例
1. 任务队列协调器 (coordinator/Queue.py)
# coordinator/Queue.py
import redis
import json
from datetime import datetime
from typing import Dict, Any, Optional
class DistributedTaskQueue:
def __init__(self, config_path: str = "../config/application.properties"):
self.config = self._load_config(config_path)
self.redis_client = redis.Redis(
host=self.config['redis_host'],
port=self.config['redis_port'],
db=self.config['redis_db']
)
self.queue_name = "mozart:task:queue"
def _load_config(self, path: str) -> Dict[str, Any]:
"""加载配置文件"""
config = {
}
with open(path, 'r') as f:
for line in f:
if '=' in line and not line.startswith('#'):
key, value = line.strip().split('=', 1)
config[key] = value
return config
def enqueue_transaction_task(self, task_data: Dict[str, Any]) -> str:
"""入队交易处理任务"""
task_id = f"task_{datetime.now().strftime('%Y%m%d%H%M%S%f')}"
task = {
'id': task_id,
'type': 'transaction_process',
'data': task_data,
'timestamp': datetime.now().isoformat(),
'source': '2026高仿支付宝模拟器app'
}
# 序列化任务数据
serialized_task = json.dumps(task)
# 推送到Redis队列
self.redis_client.lpush(self.queue_name, serialized_task)
# 发布通知事件
self.redis_client.publish('mozart:task:new', task_id)
return task_id
def dequeue_task(self, timeout: int = 30) -> Optional[Dict[str, Any]]:
"""出队任务"""
result = self.redis_client.brpop(self.queue_name, timeout=timeout)
if result:
_, task_json = result
return json.loads(task_json)
return None
def get_queue_stats(self) -> Dict[str, Any]:
"""获取队列统计信息"""
return {
'queue_length': self.redis_client.llen(self.queue_name),
'queue_name': self.queue_name,
'pending_tasks': self.redis_client.lrange(self.queue_name, 0, -1)
}
2. 数据清洗调度器 (sanitizer/Dispatcher.java)
```java
// sanitizer/Dispatcher.java
package sanitizer;
import java.util.Map;
import java.util.HashMap;
import java.util.List;
import java.util.ArrayList;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Dispatcher {
private Map pipelines;
private ObjectMapper objectMapper;
private static final String TRANSACTION_PREFIX = "ALIPAYSIM";
public Dispatcher() {
this.pipelines = new HashMap<>();
this.objectMapper = new ObjectMapper();
initializePipelines();
}
private void initializePipelines() {
// 初始化数据清洗管道
pipelines.put("financial", new FinancialDataPipeline());
pipelines.put("user_behavior", new UserBehaviorPipeline

