
下载地址:http://lanzou.co/i93bf4762
项目编译入口:
package.json
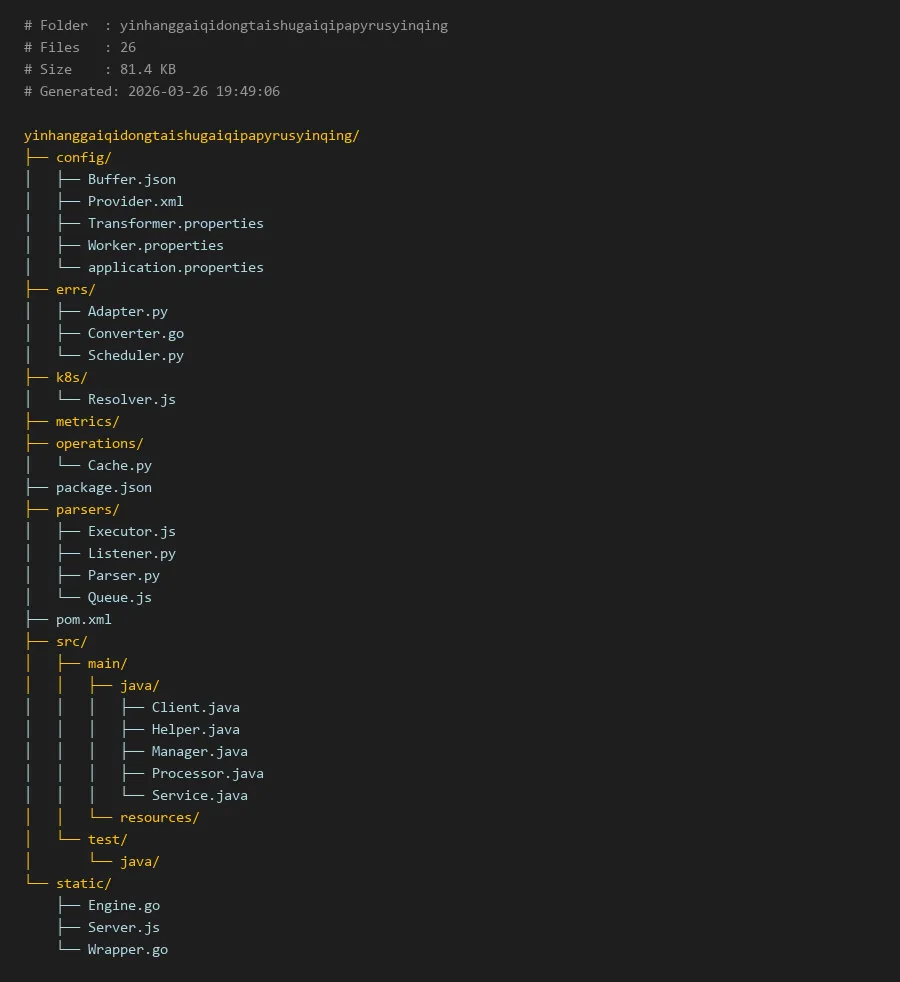
# Folder : yinhanggaiqidongtaishugaiqipapyrusyinqing
# Files : 26
# Size : 81.4 KB
# Generated: 2026-03-26 19:49:06
yinhanggaiqidongtaishugaiqipapyrusyinqing/
├── config/
│ ├── Buffer.json
│ ├── Provider.xml
│ ├── Transformer.properties
│ ├── Worker.properties
│ └── application.properties
├── errs/
│ ├── Adapter.py
│ ├── Converter.go
│ └── Scheduler.py
├── k8s/
│ └── Resolver.js
├── metrics/
├── operations/
│ └── Cache.py
├── package.json
├── parsers/
│ ├── Executor.js
│ ├── Listener.py
│ ├── Parser.py
│ └── Queue.js
├── pom.xml
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Client.java
│ │ │ ├── Helper.java
│ │ │ ├── Manager.java
│ │ │ ├── Processor.java
│ │ │ └── Service.java
│ │ └── resources/
│ └── test/
│ └── java/
└── static/
├── Engine.go
├── Server.js
└── Wrapper.go
yinhanggaiqidongtaishugaiqipapyrusyinqing:一个动态数据引擎的技术解析
简介
yinhanggaiqidongtaishugaiqipapyrusyinqing(以下简称“引擎”)是一个专注于金融数据处理与转换的高性能动态引擎。该引擎的核心设计目标是处理来自不同银行系统的实时数据流,并将其转换为统一、可操作的格式。其名称中的“papyrus”暗示了其作为数据载体的角色,而“动态树”则体现了其灵活、可扩展的数据结构处理能力。在复杂的金融数据处理场景中,例如构建一个银行余额修改器的支撑系统,该引擎能够提供稳定、高效的数据转换服务。
引擎采用微服务架构设计,支持多语言模块(Python、Go、JavaScript等)协同工作,通过配置文件驱动数据处理流程。项目结构清晰,将配置、错误处理、解析逻辑、操作和部署等关注点分离到不同的目录中。
核心模块说明
引擎的核心功能围绕parsers/、operations/和config/目录展开,并通过errs/目录进行统一的错误处理。
- 解析器模块 (
parsers/): 这是引擎的心脏,负责从原始数据源(如银行API、消息队列)中读取、解析和初步处理数据。Parser.py定义了基础解析接口,Executor.js和Listener.py分别处理不同类型的触发事件,Queue.js管理内部数据流队列。 - 操作模块 (
operations/): 包含核心的业务逻辑单元。例如,Cache.py实现了数据缓存策略,确保高频访问的数据(如用户账户信息)能够快速响应,这对于实时银行余额修改器的后台逻辑至关重要。 - 配置模块 (
config/): 采用多种格式(JSON, XML, Properties)的配置文件,使得引擎的行为可以高度定制。application.properties是主配置文件,Buffer.json、Provider.xml等则定义了数据缓冲区、数据提供者等具体组件的参数。 - 错误处理模块 (
errs/): 提供了跨语言的错误适配与转换机制。Adapter.py确保不同模块抛出的异常能被统一处理,Converter.go可能负责将错误代码转换为标准消息,Scheduler.py则可能管理错误重试策略。
代码示例
以下我们将通过几个关键文件的代码片段,来展示引擎的工作机制。
1. 主解析器 (parsers/Parser.py)
这个文件定义了所有数据解析器的基类,规定了数据解析的标准流程。
class BaseParser:
def __init__(self, config_path):
self.config = self._load_config(config_path)
self._buffer_size = self.config.get('buffer_size', 1024)
def _load_config(self, path):
# 模拟加载配置,实际可能从config/目录读取
import json
with open(path, 'r') as f:
return json.load(f)
def parse(self, raw_data):
"""解析原始数据的抽象方法,子类必须实现"""
raise NotImplementedError
def validate(self, parsed_data):
"""验证解析后数据的有效性"""
if not parsed_data.get('account_id'):
raise ValueError("Invalid data: missing account_id")
return True
def execute(self, data_stream):
"""执行解析流程的标准模板方法"""
parsed_results = []
for raw in data_stream:
try:
parsed = self.parse(raw)
if self.validate(parsed):
parsed_results.append(parsed)
except Exception as e:
# 错误将被传递到errs模块处理
raise
return parsed_results
2. 缓存操作 (operations/Cache.py)
缓存模块用于提升频繁数据访问(如查询或更新余额)的性能。
import time
from collections import OrderedDict
class LRUCache:
"""一个简单的LRU缓存实现,用于暂存账户信息"""
def __init__(self, capacity: int, ttl_seconds: int = 300):
self.cache = OrderedDict()
self.capacity = capacity
self.ttl = ttl_seconds
def get(self, key):
"""获取缓存项,并刷新其位置"""
if key not in self.cache:
return None
value, timestamp = self.cache[key]
if time.time() - timestamp > self.ttl:
# 缓存过期
self.delete(key)
return None
self.cache.move_to_end(key)
return value
def put(self, key, value):
"""添加或更新缓存项"""
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = (value, time.time())
if len(self.cache) > self.capacity:
self.cache.popitem(last=False)
def delete(self, key):
"""删除缓存项"""
if key in self.cache:
del self.cache[key]
# 全局缓存实例,可在其他模块中导入使用
account_cache = LRUCache(capacity=1000)
3. 错误适配器 (errs/Adapter.py)
错误适配器将不同来源的异常包装成引擎内部的标准格式。
```python
class EngineError(Exception):
"""引擎标准错误类"""
def init(self, code, message, original_exception=None):
self.code = code
self.message = message
self.original = original_exception
super().init(self.message)
class ErrorAdapter:
_error_mapping

