
下载地址:http://lanzou.co/i892fa0b1
项目编译入口:
package.json
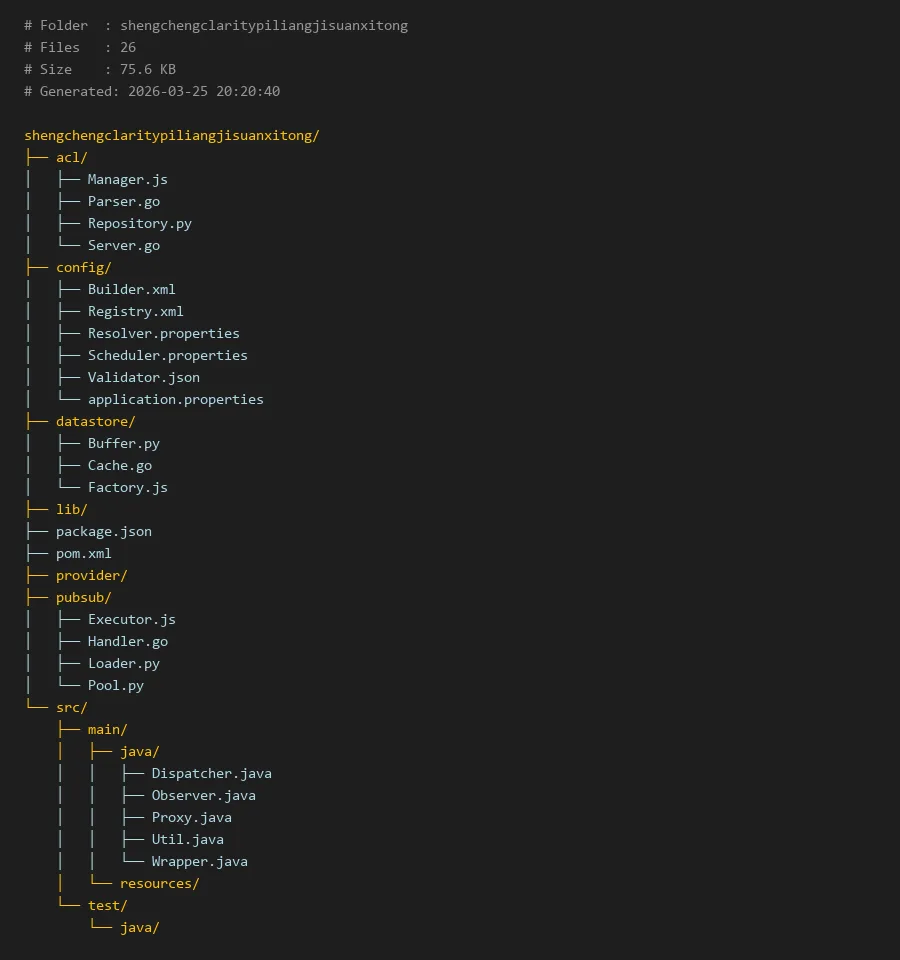
# Folder : shengchengclaritypiliangjisuanxitong
# Files : 26
# Size : 75.6 KB
# Generated: 2026-03-25 20:20:40
shengchengclaritypiliangjisuanxitong/
├── acl/
│ ├── Manager.js
│ ├── Parser.go
│ ├── Repository.py
│ └── Server.go
├── config/
│ ├── Builder.xml
│ ├── Registry.xml
│ ├── Resolver.properties
│ ├── Scheduler.properties
│ ├── Validator.json
│ └── application.properties
├── datastore/
│ ├── Buffer.py
│ ├── Cache.go
│ └── Factory.js
├── lib/
├── package.json
├── pom.xml
├── provider/
├── pubsub/
│ ├── Executor.js
│ ├── Handler.go
│ ├── Loader.py
│ └── Pool.py
└── src/
├── main/
│ ├── java/
│ │ ├── Dispatcher.java
│ │ ├── Observer.java
│ │ ├── Proxy.java
│ │ ├── Util.java
│ │ └── Wrapper.java
│ └── resources/
└── test/
└── java/
shengchengclaritypiliangjisuanxitong:一个多语言批量计算系统的技术实现
简介
shengchengclaritypiliangjisuanxitong(生成清晰批量计算系统)是一个多语言混合架构的分布式计算平台,旨在提供高效、清晰的批量数据处理能力。该系统采用模块化设计,支持多种编程语言(JavaScript、Go、Python)协同工作,通过统一的配置管理和数据存储机制,实现了复杂计算任务的调度与执行。
系统核心特点包括:多语言支持、模块化架构、配置驱动、异步消息处理和分布式计算能力。项目结构清晰,各模块职责分明,便于扩展和维护。
核心模块说明
1. 访问控制层(acl/)
访问控制层负责系统的权限管理和请求处理,包含四个核心组件:
Manager.js:JavaScript实现的权限管理器,处理用户认证和授权Parser.go:Go语言实现的请求解析器,解析和验证输入数据Repository.py:Python实现的数据仓库接口,提供数据访问抽象Server.go:Go语言实现的HTTP服务器,处理外部请求
2. 配置管理(config/)
配置管理模块提供统一的配置管理能力,支持多种配置格式:
Builder.xml:XML格式的构建配置Registry.xml:服务注册与发现配置Resolver.properties:依赖解析配置Scheduler.properties:任务调度配置Validator.json:JSON格式的数据验证规则application.properties:应用主配置文件
3. 数据存储(datastore/)
数据存储模块抽象了数据访问层,提供缓存和缓冲机制:
Buffer.py:Python实现的缓冲区管理Cache.go:Go语言实现的缓存系统Factory.js:JavaScript实现的工厂模式,创建数据存储实例
4. 发布订阅(pubsub/)
发布订阅模块实现异步消息处理:
Executor.js:JavaScript实现的任务执行器Handler.go:Go语言实现的消息处理器Loader.py:Python实现的数据加载器
代码示例
1. 配置解析器示例(config/Resolver.properties)
# 依赖解析配置
dependency.resolver.type=composite
dependency.cache.enabled=true
dependency.cache.size=1000
dependency.timeout.ms=5000
# 仓库配置
repository.central.url=https://repo.central.com
repository.local.path=/var/repo/local
# 解析策略
resolution.strategy=latest-compatible
conflict.resolution=strict
2. Go语言缓存实现(datastore/Cache.go)
package datastore
import (
"sync"
"time"
)
type CacheItem struct {
Value interface{
}
Expiration int64
}
type Cache struct {
items map[string]CacheItem
mu sync.RWMutex
}
func NewCache() *Cache {
return &Cache{
items: make(map[string]CacheItem),
}
}
func (c *Cache) Set(key string, value interface{
}, duration time.Duration) {
c.mu.Lock()
defer c.mu.Unlock()
expiration := time.Now().Add(duration).UnixNano()
c.items[key] = CacheItem{
Value: value,
Expiration: expiration,
}
}
func (c *Cache) Get(key string) (interface{
}, bool) {
c.mu.RLock()
item, found := c.items[key]
c.mu.RUnlock()
if !found {
return nil, false
}
if time.Now().UnixNano() > item.Expiration {
c.Delete(key)
return nil, false
}
return item.Value, true
}
func (c *Cache) Delete(key string) {
c.mu.Lock()
defer c.mu.Unlock()
delete(c.items, key)
}
func (c *Cache) Clear() {
c.mu.Lock()
defer c.mu.Unlock()
c.items = make(map[string]CacheItem)
}
3. Python缓冲区管理(datastore/Buffer.py)
```python
class DataBuffer:
def init(self, max_size=10000, flush_threshold=0.8):
self.buffer = []
self.max_size = max_size
self.flush_threshold = flush_threshold
self.flush_callback = None
def add(self, data):
"""添加数据到缓冲区"""
self.buffer.append(data)
# 检查是否需要刷新
if len(self.buffer) >= self.max_size * self.flush_threshold:
self.flush()
def flush(self):
"""刷新缓冲区数据"""
if not self.buffer:
return
if self.flush_callback:
self.flush_callback(self.buffer)
self.buffer.clear()
def set_flush_callback(self, callback):
"""设置刷新回调函数"""
self.flush_callback = callback
def get_size(self):
"""获取当前缓冲区大小"""
return len(self.buffer)
def clear(self):
"""清空缓冲区"""
self.buffer.clear()
class BatchProcessor:
def init(self, buffer_size=5000):
self.buffer = DataBuffer(max_size=buffer_size)
self.buffer.set_flush_callback(self.process_batch)
def process_batch(self, batch_data):
"""处理批量数据"""

