
基于YOLOv8的道路隐患识别与城市路况安全识别|完整源码数据集+PyQt5界面+完整训练流程+开箱即用!
本项目基于 YOLOv8 深度学习目标检测模型,结合 PyQt5 图形界面工具,实现了面向城市道路的隐患设施识别与路况安全检测系统。系统能够高效识别包括井盖、打开的井盖、道路坑洞、减速带及无标识减速带在内的常见道路设施及潜在安全隐患。
项目特色在于:
- 提供 完整数据集及标注,便于直接训练与微调模型。
- 内置 YOLOv8训练与推理代码,支持自定义训练与快速部署。
- 提供 PyQt5可视化界面,支持图片、文件夹、视频以及实时摄像头输入。
- 配套 开箱即用的权重文件 和详细部署/训练教程,降低模型应用门槛。
该系统可广泛应用于智能交通巡检、城市道路安全管理、自动驾驶环境感知等场景,为提升道路安全和管理效率提供数据与技术支撑。
基本功能演示
https://www.bilibili.com/video/BV1CT65BLE7h/
源码在文末哔哩哔哩视频简介处获取。
包含:
📦完整项目源码
📦 预训练模型权重
🗂️ 数据集地址(含标注脚本)
前言
随着城市道路设施数量的增加与道路交通复杂度的提升,道路隐患识别与安全监测变得尤为重要。传统人工巡检效率低、成本高且存在疏漏,而深度学习目标检测技术的发展为道路安全监控提供了智能化解决方案。
YOLOv8 作为当前性能优异的实时目标检测模型,具有高精度和低延迟的优势,特别适合道路设施和隐患目标的检测任务。结合 PyQt5 图形界面,本项目实现了从数据标注、模型训练到可视化检测的一体化解决方案,使用户无需复杂配置即可快速部署道路安全检测系统。
本项目旨在提供一套完整的 “数据集+模型训练+推理部署+图形界面工具” 流程,降低道路安全检测系统的实现门槛,同时为科研、城市管理及智能交通领域提供可落地的参考方案。
一、软件核心功能介绍及效果演示
多目标检测能力
- 支持 5 类道路设施和隐患目标:井盖(Manhole)、打开井盖(Open Manhole)、道路坑洞(Pothole)、减速带(Speed Bump)、无标识减速带(Unmarked Bump)。
- 采用 YOLOv8 模型,实现快速且精准的目标检测。
多输入模式支持
- 图片单张检测
- 文件夹批量检测
- 视频文件检测
- 实时摄像头流检测
图形化交互界面
- PyQt5 界面,可直接拖拽文件进行检测
- 可视化显示检测结果及置信度
- 支持结果导出与标注可视化
完整训练与部署流程
- 提供训练代码与数据集,支持自定义模型训练
- 提供预训练权重文件,实现开箱即用的检测效果
- 提供详细部署教程,轻松在本地或服务器环境运行
实时性能与可扩展性
- YOLOv8 模型保证高帧率检测,适合视频与摄像头实时应用
- 支持自定义类别扩展和迁移训练,方便后续功能升级
二、软件效果演示
为了直观展示本系统基于 YOLOv8 模型的检测能力,我们设计了多种操作场景,涵盖静态图片、批量图片、视频以及实时摄像头流的检测演示。
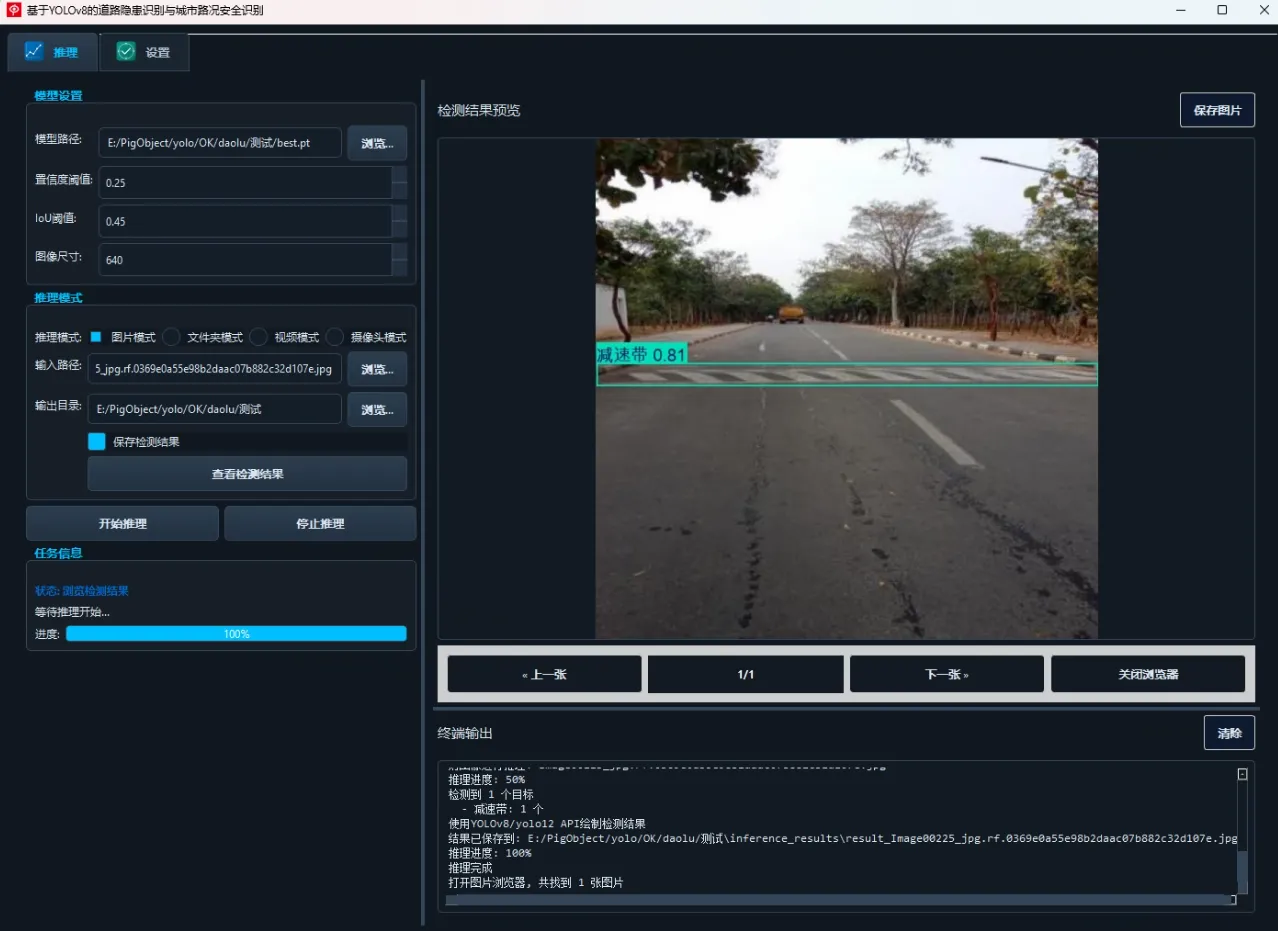
(1)单图片检测演示
用户点击“选择图片”,即可加载本地图像并执行检测:
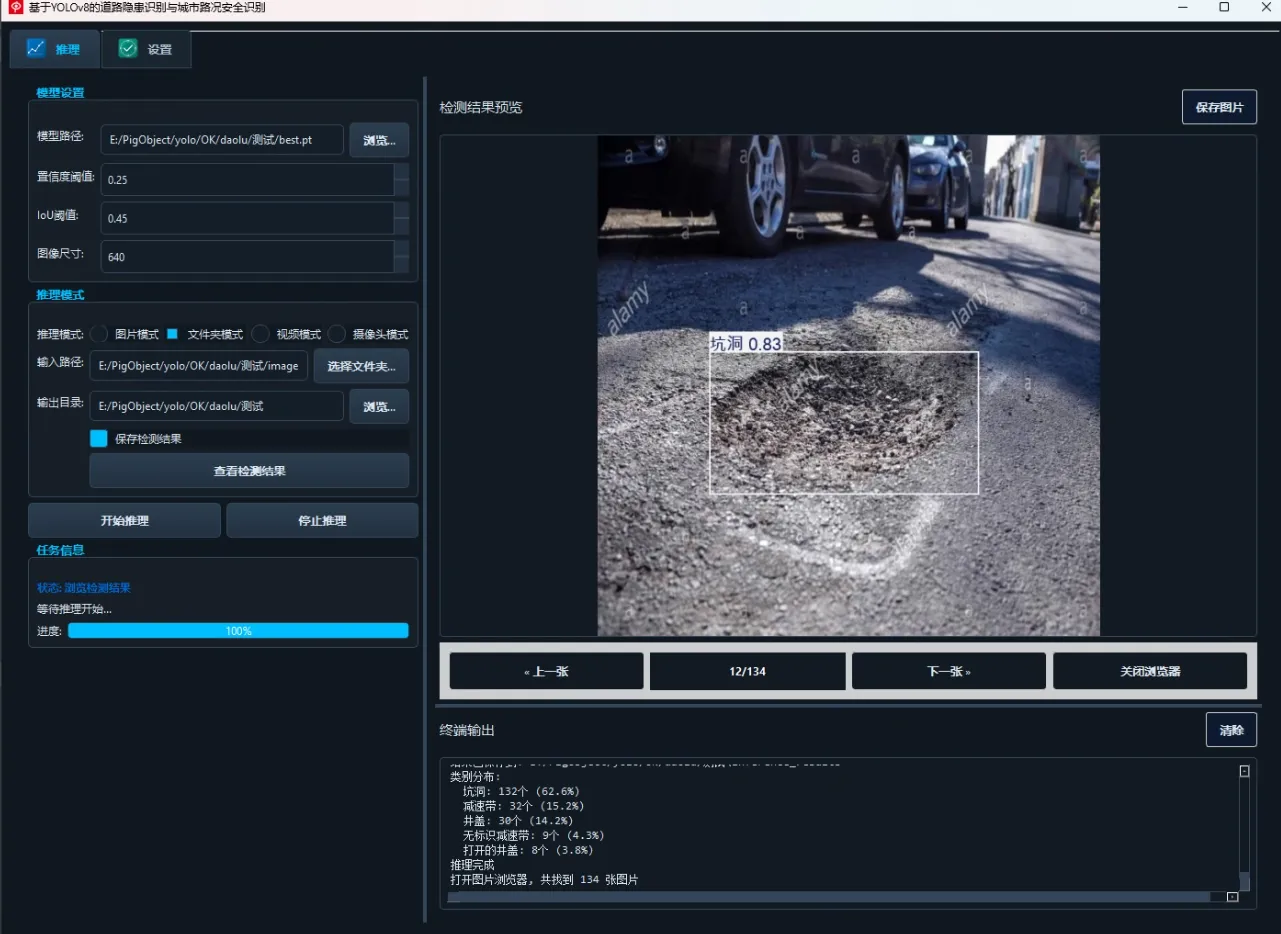
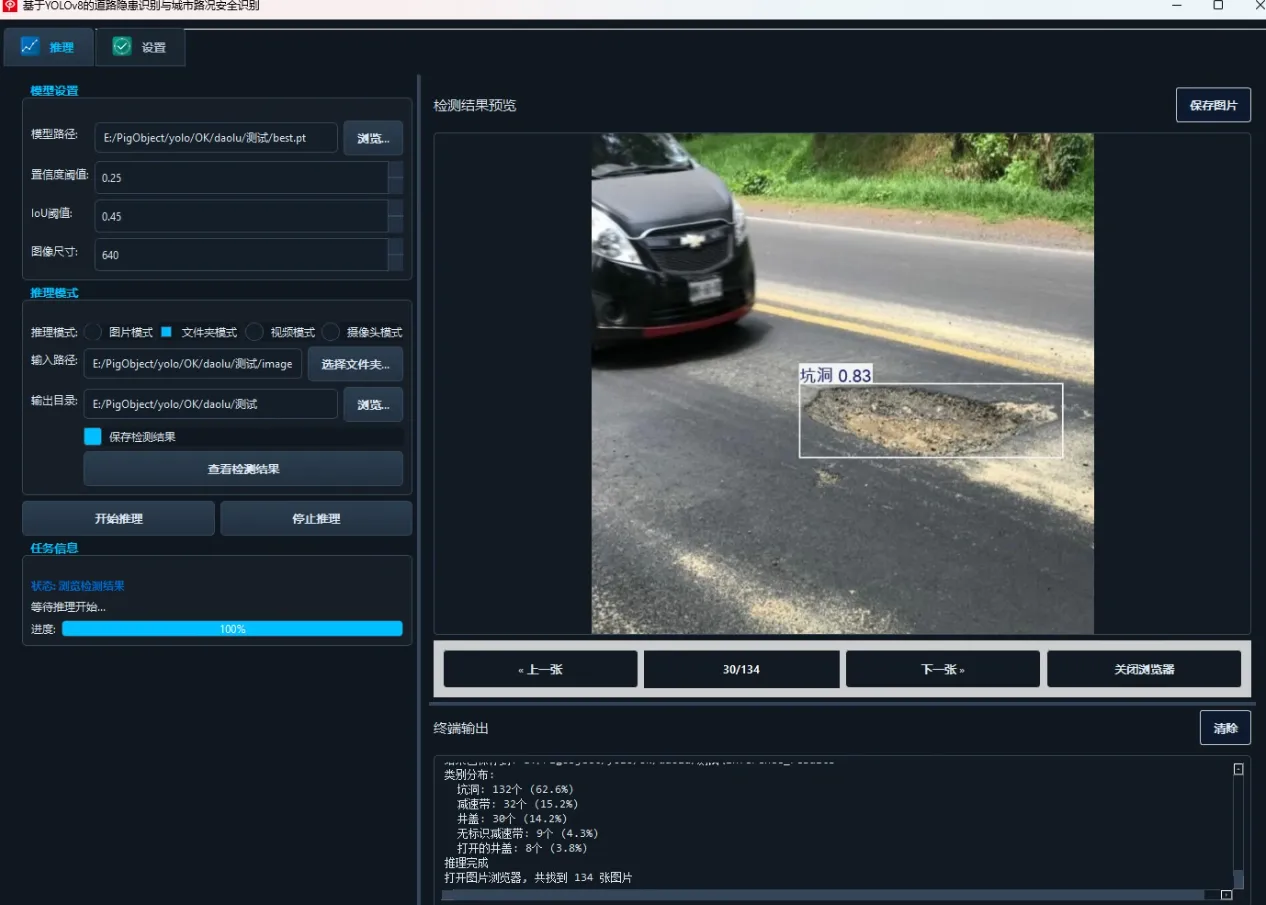
(2)多文件夹图片检测演示
用户可选择包含多张图像的文件夹,系统会批量检测并生成结果图。
(3)视频检测演示
支持上传视频文件,系统会逐帧处理并生成目标检测结果,可选保存输出视频:

(4)摄像头检测演示
实时检测是系统中的核心应用之一,系统可直接调用摄像头进行检测。由于原理和视频检测相同,就不重复演示了。
(5)保存图片与视频检测结果
用户可通过按钮勾选是否保存检测结果,所有检测图像自动加框标注并保存至指定文件夹,支持后续数据分析与复审。
三、模型的训练、评估与推理
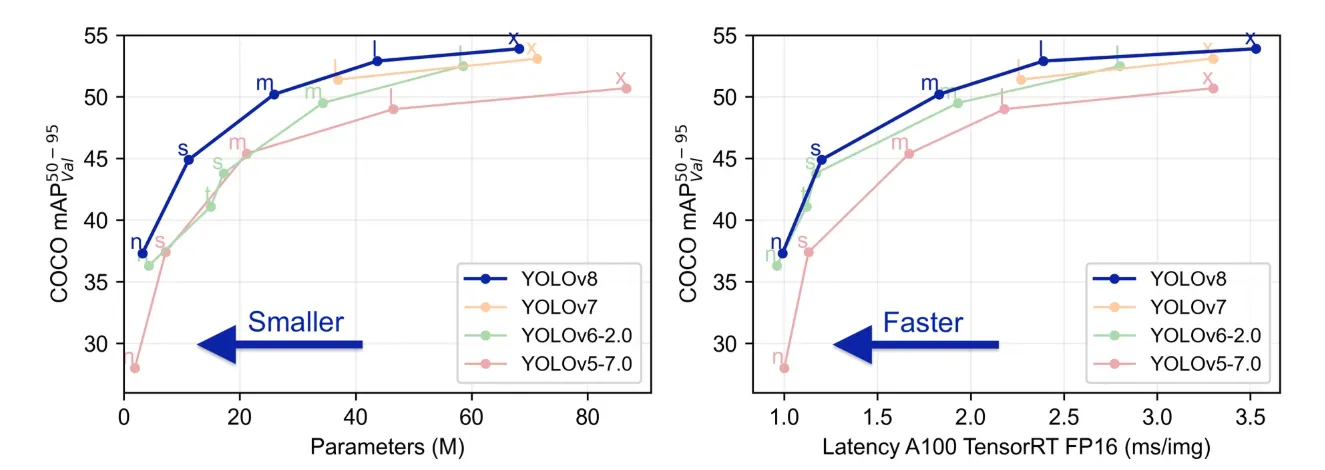
YOLOv8是Ultralytics公司发布的新一代目标检测模型,采用更轻量的架构、更先进的损失函数(如CIoU、TaskAlignedAssigner)与Anchor-Free策略,在COCO等数据集上表现优异。
其核心优势如下:
- 高速推理,适合实时检测任务
- 支持Anchor-Free检测
- 支持可扩展的Backbone和Neck结构
- 原生支持ONNX导出与部署
3.1 YOLOv8的基本原理
YOLOv8 是 Ultralytics 发布的新一代实时目标检测模型,具备如下优势:
- 速度快:推理速度提升明显;
- 准确率高:支持 Anchor-Free 架构;
- 支持分类/检测/分割/姿态多任务;
- 本项目使用 YOLOv8 的 Detection 分支,训练时每类表情均标注为独立目标。
YOLOv8 由Ultralytics 于 2023 年 1 月 10 日发布,在准确性和速度方面具有尖端性能。在以往YOLO 版本的基础上,YOLOv8 引入了新的功能和优化,使其成为广泛应用中各种物体检测任务的理想选择。
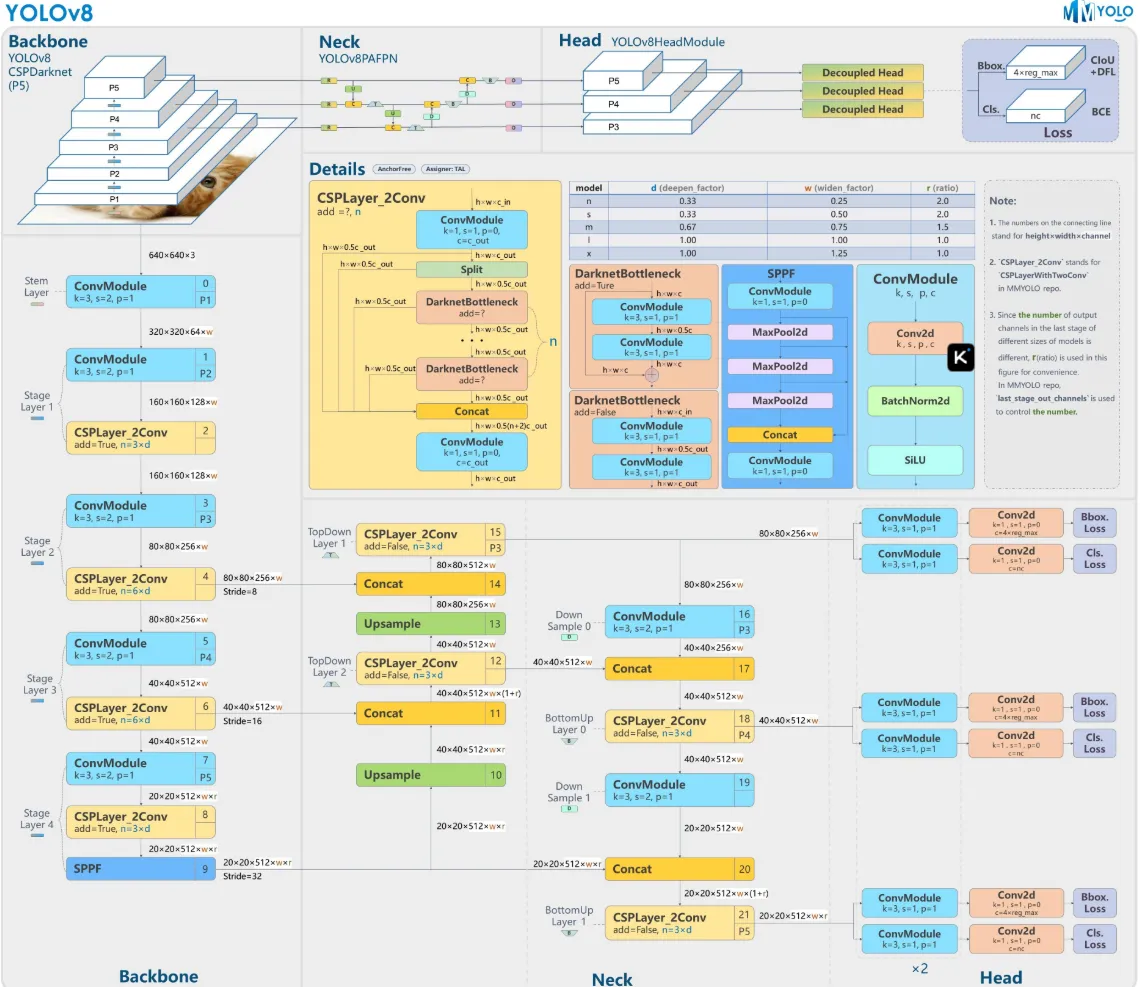
YOLOv8原理图如下:
3.2 数据集准备与训练
采用 YOLO 格式的数据集结构如下:
dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
每张图像有对应的 .txt 文件,内容格式为:
4 0.5096721233576642 0.352838390077821 0.3947600423357664 0.31825755058365757
分类包括(可自定义):

3.3. 训练结果评估
训练完成后,将在 runs/detect/train 目录生成结果文件,包括:
results.png:损失曲线和 mAP 曲线;weights/best.pt:最佳模型权重;confusion_matrix.png:混淆矩阵分析图。
若 mAP@0.5 达到 90% 以上,即可用于部署。
在深度学习领域,我们通常通过观察损失函数下降的曲线来评估模型的训练状态。YOLOv8训练过程中,主要包含三种损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss)。训练完成后,相关的训练记录和结果文件会保存在runs/目录下,具体内容如下:

3.4检测结果识别
使用 PyTorch 推理接口加载模型:
import cv2
from ultralytics import YOLO
import torch
from torch.serialization import safe_globals
from ultralytics.nn.tasks import DetectionModel
# 加入可信模型结构
safe_globals().add(DetectionModel)
# 加载模型并推理
model = YOLO('runs/detect/train/weights/best.pt')
results = model('test.jpg', save=True, conf=0.25)
# 获取保存后的图像路径
# 默认保存到 runs/detect/predict/ 目录
save_path = results[0].save_dir / results[0].path.name
# 使用 OpenCV 加载并显示图像
img = cv2.imread(str(save_path))
cv2.imshow('Detection Result', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
预测结果包含类别、置信度、边框坐标等信息。

四.YOLOV8+YOLOUI完整源码打包
本文涉及到的完整全部程序文件:包括python源码、数据集、训练代码、UI文件、测试图片视频等(见下图):
4.1 项目开箱即用
作者已将整个工程打包。包含已训练完成的权重,读者可不用自行训练直接运行检测。
运行项目只需输入下面命令。
python main.py
读者也可自行配置训练集,或使用打包好的数据集直接训练。
自行训练项目只需输入下面命令。
yolo detect train data=datasets/expression/loopy.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 batch=16 lr0=0.001
总结
本项目基于 YOLOv8 目标检测模型与 PyQt5 图形界面,实现了面向城市道路的 隐患设施识别与路况安全检测系统。系统支持图片、视频、摄像头及批量文件夹多种输入模式,能够快速识别井盖、打开的井盖、道路坑洞、减速带及无标识减速带等道路设施和潜在安全隐患。
项目特点在于提供 完整数据集及标注、训练代码、预训练权重和部署教程,用户可直接开箱使用或进行自定义训练。该系统兼具 高精度识别、实时性能和易用性,可广泛应用于智能交通巡检、城市道路安全管理及自动驾驶环境感知等场景,为提升城市道路安全和管理效率提供数据和技术支撑。

![基于YOLOv8的无人机道路损伤检测[四类核心裂缝/坑洼识别]的识别项目|完整源码数据集+PyQt5界面+完整训练流程+开箱即用!](https://ucc.alicdn.com/6x3ykqt6vixgc/developer-article1706376/20260115/954e69a4aa204a2091758160713e38ec.png?x-oss-process=image/format,webp/resize,h_160,m_lfit)

