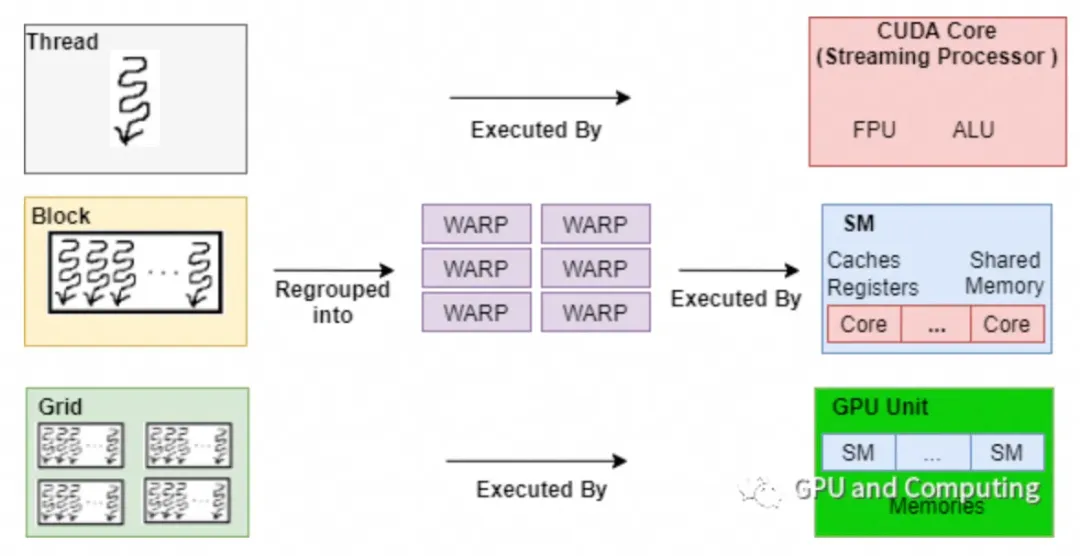
在人工智能(AI)、机器学习(ML)和高性能计算(HPC)飞速发展的今天,数据存储和处理的效率已成为决定项目成败的关键因素。传统的云存储方案往往无法满足GPU密集型工作负载的需求,而GPU云存储性能的优化正成为企业提升计算效率、降低延迟的核心突破口。本文将深入探讨GPU云存储性能的重要性、关键技术及优化策略,助您在数据驱动的竞争中占据先机。
为什么GPU云存储性能如此重要?
GPU的强大并行计算能力使其成为处理AI训练、科学模拟和图形渲染等任务的理想选择。然而,若存储系统无法高效读写数据,GPU的计算能力将无法充分发挥。存储性能瓶颈会导致GPU等待数据输入,造成资源闲置和成本浪费。因此,高性能的云存储不仅是数据仓库,更是GPU计算生态的“燃料库”。
提升GPU云存储性能的关键技术
NVMe与高性能存储介质
传统硬盘(HDD)和普通SSD难以匹配GPU的数据吞吐需求。NVMe(非易失性内存 Express)SSD凭借低延迟和高IOPS(每秒输入输出操作数)成为GPU云存储的首选。其并行访问能力可大幅减少数据加载时间,确保GPU持续高效运行。
并行文件系统与分布式架构
单点存储无法应对海量数据请求。采用如Lustre、GPFS等并行文件系统,可将数据分散到多个节点,实现并发读写。例如,在训练大型AI模型时,分布式存储允许多个GPU同时访问数据集,避免I/O阻塞。
存储与计算节点的协同优化
云服务商(如AWS、Azure、Google Cloud)通过将GPU实例与高性能存储(如AWS的FSx for Lustre)紧耦合,减少网络传输延迟。数据本地化缓存和智能预加载技术进一步缩短GPU等待时间。
软件栈与协议优化
针对GPU工作负载的软件优化至关重要。例如,使用RDMA(远程直接内存访问)技术绕过CPU直接传输数据,或通过GPU Direct Storage(GDS)允许GPU直接访问存储数据,减少内存拷贝开销。
实际应用场景中的性能增益
AI模型训练:高效存储可将数据集加载时间缩短50%以上,加速迭代周期。
科学计算:气象模拟、基因分析等需要实时处理TB级数据的场景,依赖高吞吐存储保障连续性。
媒体渲染:4K/8K视频编辑与渲染中,存储带宽直接影响工作流效率。
如何选择与优化GPU云存储?
评估工作负载特性:顺序读写(如视频流)侧重吞吐量,随机读写(AI训练)需高IOPS。
选择定制化解决方案:主流云平台提供GPU优化存储选项,如Azure的Ultra Disk或Google Cloud的Local SSD。
监控与调优:利用工具监控I/O延迟和带宽,动态调整存储配置(如条带化参数)。
成本效益平衡:采用分层存储策略,将热数据存放于高性能层,冷数据迁移至低成本对象存储。
未来趋势:存储与GPU的深度融合
随着计算需求爆炸式增长,存储技术正与GPU架构更紧密集成。CXL(Compute Express Link)等新互联标准将实现内存和存储资源的池化,进一步提升数据访问效率。同时,硬件加速的数据压缩/解压技术(如NVIDIA的SmartSSD)将进一步释放GPU潜力。
结语
GPU云存储性能是解锁GPU全部算力的基石。通过选择高性能存储介质、分布式架构及软硬件协同优化,企业可显著提升计算效率,降低总拥有成本(TCO)。在AI与HPC浪潮中,投资于下一代存储基础设施已不再是可选项,而是保持竞争力的必然选择。