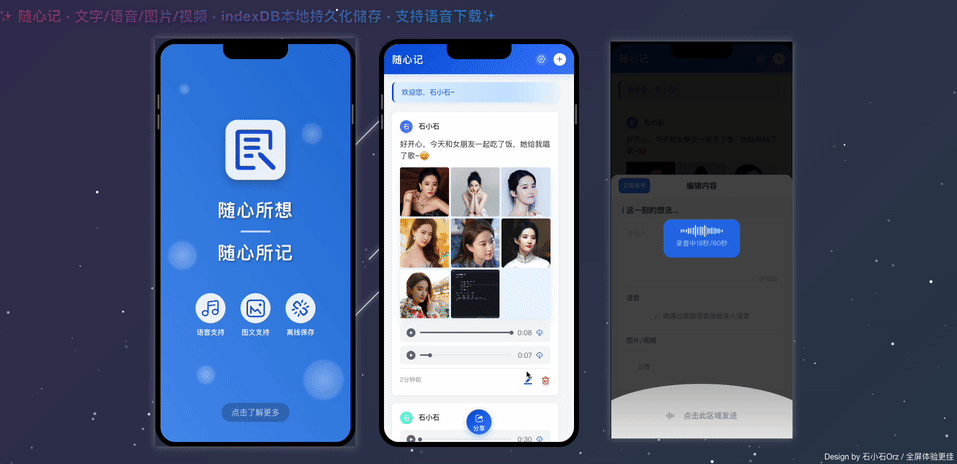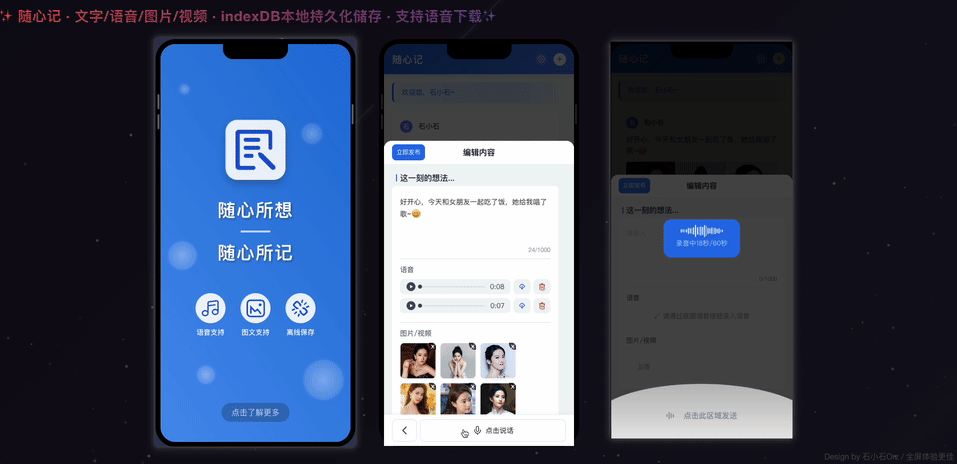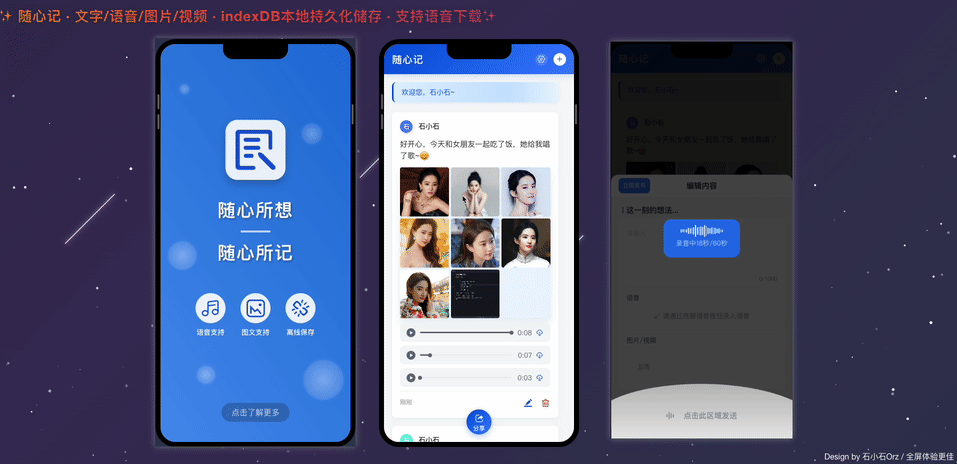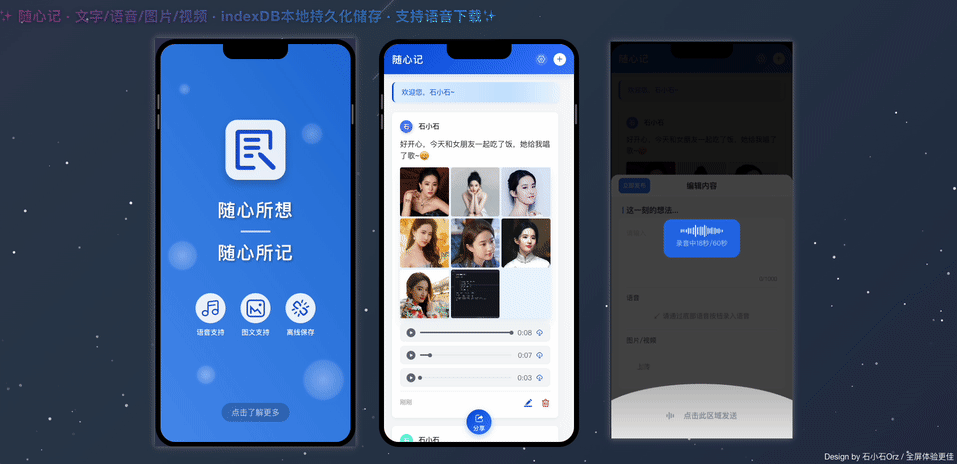
【AI问爱答-双十一返场周】第三场社交娱乐视频
本次主题是AI和社交形态当中的拟合和变化带来新的一些机会,对于中小企业,现在有很多互联网公司都在探索,比如付费订阅、出售进阶版、定制版做商业化。霸道总裁爱上我的AI非常火爆,受到广大女性欢迎。虚拟的导师,虚拟的教练,AI可以在教育和培训的行业做实际应用。甚至个人开发者,在百炼平台上,用智能体搭建帮助男生改掉直男癌的陪练教练,这种是虚拟导师的角色。阿里云有很多客户在尝试AI的应用,今天邀请到听力熊的联合创始人兼CPO苟津川先生,听力熊做青少年智能教育硬件。团队15年也在搞AI相关的东西,基本上有接近十年的AI相关的经验。这十年一直探索AI在教育领域,教育和智能硬件结合领域里面的新的玩法、新的应用、新的场景,发现Token的消耗量不小,希望能解答在终端的设备上,如何更好做端云的协调,让中小企业能够在应用的落地上能够做到更好的性价比和更好的应用产品。
首先关于云端协同,云端协同对于云的能力要求很高,阿里云具备这样的能力,云百炼也已经对接,能够提供比较强劲的现在基础的模型。第二点是端侧的落地和端侧的协同,实际上由于技术的限制,希望在端侧的芯片上去跑,譬如提供在0.3B、1.5B小size的模型,整个在这一块技术上也能探索的比较前沿。还有一个问题是发现有的孩子用AI角色发泄,暴露他心中的不满、低落、自卑。甚至还有一些关于两性的探讨,这些数据对家长来说非常隐私和敏感,如何做数据的安全性。
对AI感兴趣的朋友们可以持续关注AI问爱答。同时可以扫码二维码进行访问,可以到官网当中进行提问,同时可以进入权益中心页面点击云聚AI全面提速,不错过任何AI相关的最新产品技术和促销内容,将AI进行到底。