
🚀一、单链表的概念
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
链表是由一个个结点组成,每个结点之间通过链接关系串联起来,每个结点都有一个后继结点,最后一个结点的后继结点为空结点。

每个结点只设置一个指向后继结点的指针属性,这样的链表成为线性单项链接表,简称单链表;如果每个结点中设置两个指针属性,分别在于指向其前驱结点和后继结点,这样的链表称为线性双向链接表,简称双链表。无前驱结点或则后继结点的相应指针属性用常量None表示。

注意:在Python中并不存在指针的概念,这里的指针属性实际上存放的是后继结点或者前驱结点的引用,但是为了表述方便仍然会采用 “指针” 一词。
🌈二、单链表的实现
⭐1. 单链表结点类
在单链表中,假定每个结点为LinkNode类对象,它包括存储元素的数据成员,这里用data表示,还包括存储后继结点的指针属性,这里用next表示。LinkNode的定义:
# 单链表结点类 class LinkNode: def __init__(self, data=None): self.data = data self.next = None
设计单链表类为LinkList,其中head属性为单链表的头结点,构造方法用于创建 这个头结点,并且设置head结点的next为空:
# 单链表类 class LinkList: def __init__(self): self.head = LinkNode() self.head.next = None
🎬2. 插入和删除操作
1、元素插入的概念
单向链表的元素插入,就是指给定一个索引 i 和一个元素 data,生成一个值为 data 的结点,并且插入到第 i 个位置上。
(1)、插入结点操作
p(即 pre)代表目前正在遍历的结点,当计数到 3 的时候,p 的后继结点 a (即 aft)也找到了,然后生成值为 5 的结点 vtx,将 p 的后继指向 vtx,将 vtx 的后继指向 a。

步骤:
- 第1步:判断插入位置是否合法,如果不合法则抛出异常(比如:原本只有5个元素,给定的索引是100,那显然这个位置是不合法的)。
- 第2步:对给定的元素,生成一个链表结点。
- 第3步:如果插入位置是 0,则直接把生成的结点的后继结点,设置为当前的链表头结点,并且把生成的结点设置为新的链表头。
- 第4步:如果插入位置不是 0,则遍历到插入位置的前一个位置,把生成的结点插入进来。
- 第5步:更新链表的大小,即对链表的大小执行加一操作。
头插法:
# 头插法: 由数组a整体建立单链表 def CreateListF(self, a): for i in range(0, len(a)): s = LinkNode(a[i]) s.next = self.head.next self.head.next = s
尾插法:
# 尾插法: 由数组a整体建立单链表 def CreateListR(self, a): t = self.head for i in range(0, len(a)): s = LinkNode(a[i]) t.next = s t = s t.next = None
任意位置插入:
# 在线性表中序号为i的位置插入元素e def Insert(self, i, e): assert i >= 0 s = LinkNode(e) p = self.geti(i - 1) assert p is not None s.next = p.next p.next = s
上述指针修改用Python语句描述:
s.next = p.next
p.next = s
注意:这两个语句的顺序不能颠倒,如果先执行p.next = s语句,会找不到指向插入位置的下一个结点,再执行s.next = p.next语句,相当于执行s.next = s,导致插入操作错误。
2、元素删除的概念
单向链表的元素删除,就是指给定一个索引 i,将从链表头开始数到的第 i 个结点删除。
(1)、删除结点操作
删除运算是删除单链表中p结点的后继结点,就是将p结点的next修改为其后继结点的后继结点。

步骤:
- 第1步:判断删除位置是否合法,如果不合法则抛出异常。
- 第2步:如果删除位置为首个结点,直接把链表头更新为它的后继结点。
- 第3步:如果删除位置非首个结点,则遍历到要删除位置的前一个结点,并且把前一个结点的后继结点设置为它后继的后继。
- 第4步:更新链表的大小,也就是将链表的大小执行减一操作。
# 在线性表中删除序号i的位置的元素 def Delete(self, i): assert i >= 0 p = self.geti(i - 1) assert p.next is not None p.next = p.next.next
💥3. 元素查找
1、元素查找的概念
单向链表的元素查找,是指在链表中查找指定元素 x 是否存在,如果存在则返回该结点,否则返回 NULL。由于需要遍历整个链表进行元素对比,所以查找的时间复杂度为 O(n) 。

2、元素查找的步骤
- 第1步:遍历整个链表,对链表中的每个元素,和指定元素进行比较,如果相等则返回当前遍历到的结点;
- 第2步:如果遍历完整个链表,都没有找到相等的元素,则返回 NULL。
# 求序号i的元素 def __getitem__(self, i): assert i >= 0 p = self.geti(i) assert p is not None return p.data
❤️4. 单向链表的元素索引
1、元素索引的概念
单向链表的元素索引,是指给定一个索引值 i,从链表头结点开始数,数到第 i 个结点并且返回它,时间复杂度 O(n)。
2、元素索引的步骤
- 第1步:首先判断给定的索引是否合法,不合法就抛出异常。
- :直接通过索引访问即可获得对应的元素。
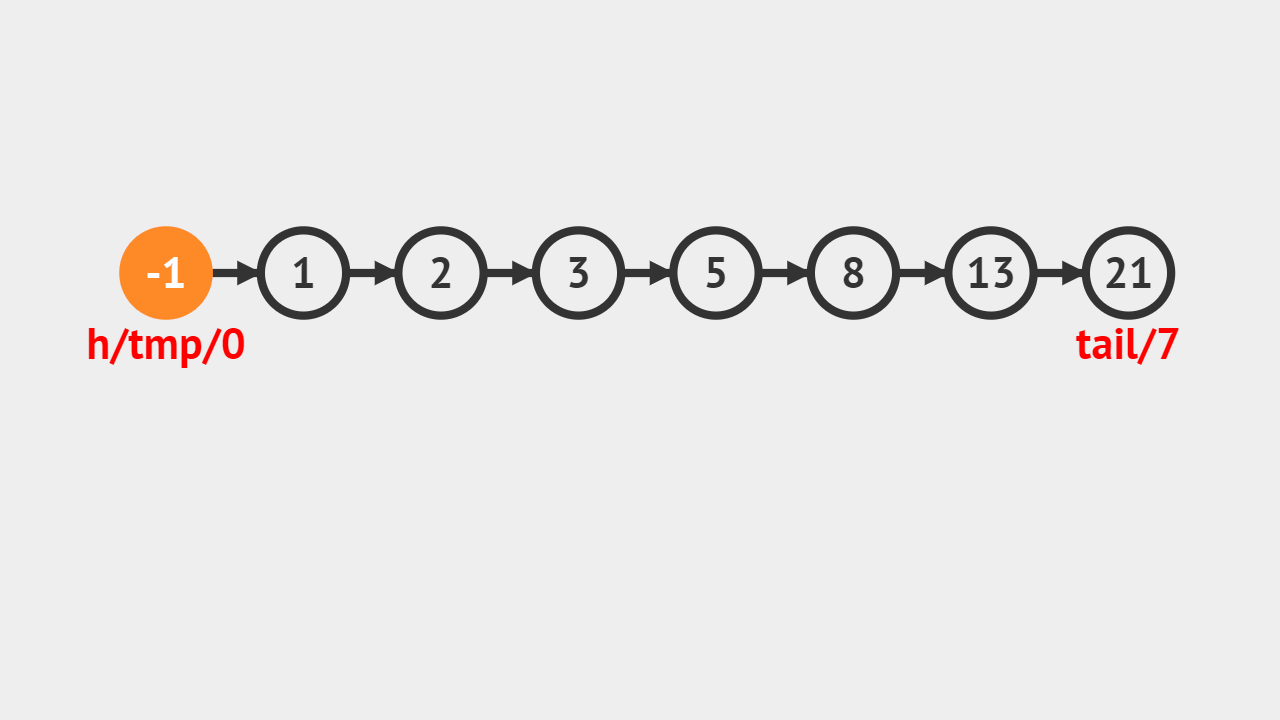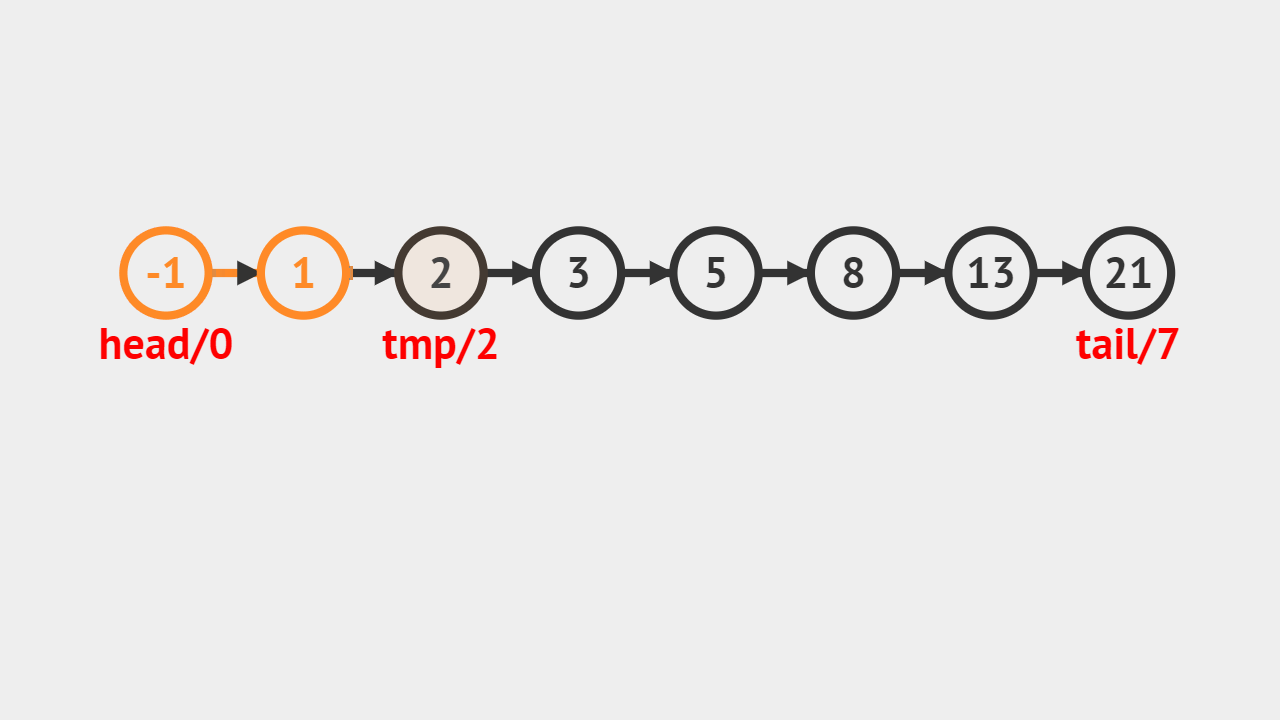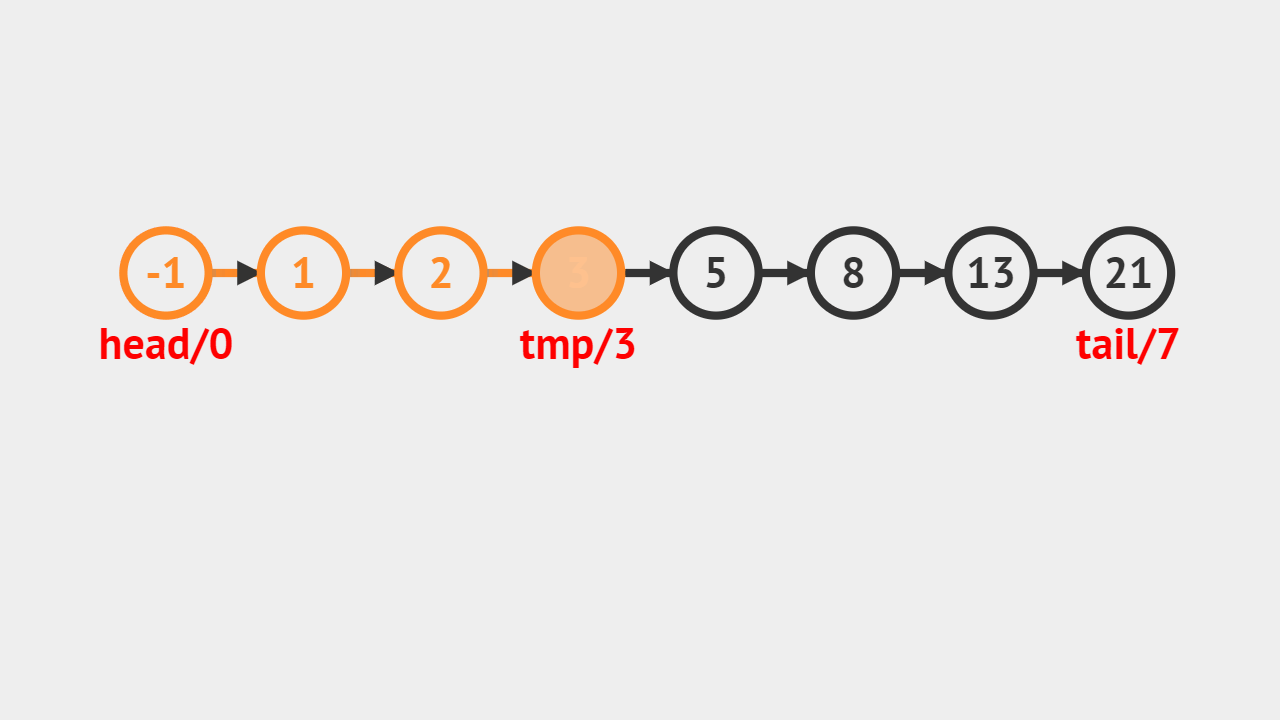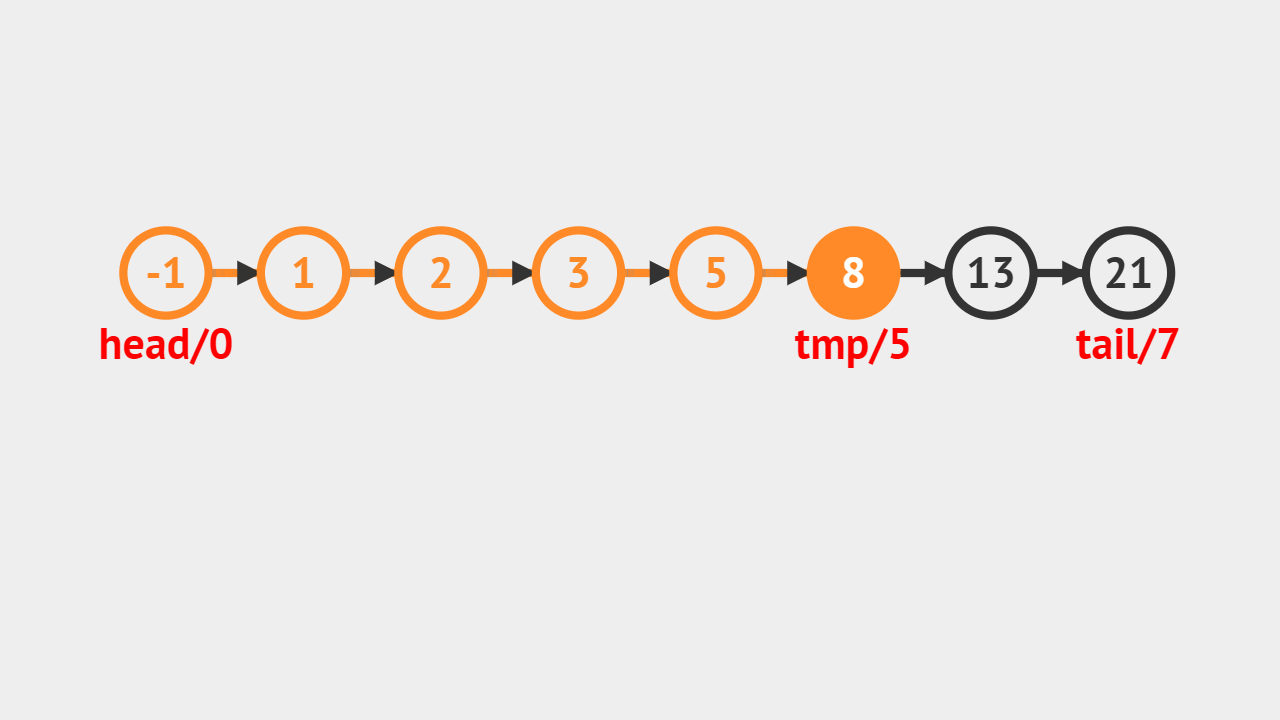
# 查找第一个为e的元素的序号 def GetNo(self, e): j = 0 p = self.head.next while p is not None and p.data != e: j += 1 p = p.next if p is None: return -1 else: return j
☔5. 单向链表的元素修改
1、元素修改的概念
单向链表的元素修改是指将链表中指定索引的元素更新为新的值。
2、元素修改的步骤
- 第1步:直接通过索引访问即可获得对应的结点,修改成指定的值。

# 设置序号为i的元素 def __setitem__(self, i, x): assert i >= 0 p = self.geti(i) assert p is not None p.data = x
返回序号为i的结点
返回序号为i的结点 # 返回序号为i的结点
👊6. 输出单链表
顾名思义就是一次便利单链表中各数据结点并输出结点值。
# 输出线性表 def display(self): p = self.head.next while p is not None: print(p.data, end=' ') p = p.next print()
时间复杂度为O(n),n表示顺序表中的元素个数。
🚀三、完整代码
# 单链表结点类 class LinkNode: def __init__(self, data=None): self.data = data self.next = None # 单链表类 class LinkList: def __init__(self): self.head = LinkNode() self.head.next = None # 头插法: 由数组a整体建立单链表 def CreateListF(self, a): for i in range(0, len(a)): s = LinkNode(a[i]) s.next = self.head.next self.head.next = s # 尾插法: 由数组a整体建立单链表 def CreateListR(self, a): t = self.head for i in range(0, len(a)): s = LinkNode(a[i]) t.next = s t = s t.next = None # 返回序号为i的结点 def geti(self, i): p = self.head j = -1 while j < i and p is not None: j += 1 p = p.next return p # 在线性表的末尾添加一个元素e def Add(self, e): s = LinkNode(e) p = self.head while p.next is not None: p = p.next p.next = s # 返回长度 def getsize(self): p = self.head cnt = 0 while p.next is not None: cnt += 1 p = p.next return cnt # 求序号i的元素 def __getitem__(self, i): assert i >= 0 p = self.geti(i) assert p is not None return p.data # 设置序号为i的元素 def __setitem__(self, i, x): assert i >= 0 p = self.geti(i) assert p is not None p.data = x # 查找第一个为e的元素的序号 def GetNo(self, e): j = 0 p = self.head.next while p is not None and p.data != e: j += 1 p = p.next if p is None: return -1 else: return j # 在线性表中序号为i的位置插入元素e def Insert(self, i, e): assert i >= 0 s = LinkNode(e) p = self.geti(i - 1) assert p is not None s.next = p.next p.next = s # 在线性表中删除序号i的位置的元素 def Delete(self, i): assert i >= 0 p = self.geti(i - 1) assert p.next is not None p.next = p.next.next # 输出线性表 def display(self): p = self.head.next while p is not None: print(p.data, end=' ') p = p.next print()
🚲四、代码验证
if __name__ == '__main__': L = LinkList() print('建立空单链表L') a = [1, 2, 3, 4, 5, 6] print('1~6创建L') L.CreateListR(a) print('L[长度 = %d]: ' % (L.getsize()), end=' '), L.display() print('插入6~10') for i in range(6, 11): L.Add(i) print('L[长度 = %d]: ' % (L.getsize()), end=' '), L.display() print('序号为2的元素 = %d' % (L[2])) print('设置序号为2的元素为20') L[2] = 20 print('L[长度 = %d]: ' % (L.getsize()), end=' '), L.display() x = 6 print('第一个值为%d的元素序号 = %d' % (x, L.GetNo(x))) n = L.getsize() for i in range(n - 2): print('删除首元素') L.Delete(0) print('L[长度 = %d]: ' % (L.getsize()), end=' '), L.display()

