FastAI 之书(面向程序员的 FastAI)(三)(1)https://developer.aliyun.com/article/1483219
为了准确了解这里发生了什么,让我们将所有列放在一起放在一个表中。这里,前两列是我们的激活,然后是目标,行索引,最后是前面代码中显示的结果:
| 3 | 7 | targ | idx | loss |
| 0.602469 | 0.397531 | 0 | 0 | 0.602469 |
| 0.502065 | 0.497935 | 1 | 1 | 0.497935 |
| 0.133188 | 0.866811 | 0 | 2 | 0.133188 |
| 0.99664 | 0.00336017 | 1 | 3 | 0.00336017 |
| 0.595949 | 0.404051 | 1 | 4 | 0.404051 |
| 0.366118 | 0.633882 | 0 | 5 | 0.366118 |
从这个表中可以看出,最后一列可以通过将targ和idx列作为索引,指向包含3和7列的两列矩阵来计算。这就是sm_acts[idx, targ]的作用。
这里真正有趣的是,这种方法同样适用于超过两列的情况。想象一下,如果我们为每个数字(0 到 9)添加一个激活列,然后targ包含从 0 到 9 的数字。只要激活列总和为 1(如果我们使用 softmax,它们将是这样),我们将有一个损失函数,显示我们预测每个数字的准确程度。
我们只从包含正确标签的列中选择损失。我们不需要考虑其他列,因为根据 softmax 的定义,它们加起来等于 1 减去与正确标签对应的激活。因此,使正确标签的激活尽可能高必须意味着我们也在降低其余列的激活。
PyTorch 提供了一个与sm_acts[range(n), targ]完全相同的函数(除了它取负数,因为之后应用对数时,我们将得到负数),称为nll_loss(NLL代表负对数似然):
-sm_acts[idx, targ]
tensor([-0.6025, -0.4979, -0.1332, -0.0034, -0.4041, -0.3661])
F.nll_loss(sm_acts, targ, reduction='none')
tensor([-0.6025, -0.4979, -0.1332, -0.0034, -0.4041, -0.3661])
尽管它的名字是这样的,但这个 PyTorch 函数并不取对数。我们将在下一节看到原因,但首先,让我们看看为什么取对数会有用。
取对数
在前一节中我们看到的函数作为损失函数效果很好,但我们可以让它更好一些。问题在于我们使用的是概率,概率不能小于 0 或大于 1。这意味着我们的模型不会在乎它是预测 0.99 还是 0.999。确实,这些数字非常接近,但从另一个角度来看,0.999 比 0.99 自信程度高 10 倍。因此,我们希望将我们的数字从 0 到 1 转换为从负无穷到无穷。有一个数学函数可以做到这一点:对数(可用torch.log)。它对小于 0 的数字没有定义,并且如下所示:
plot_function(torch.log, min=0,max=4)
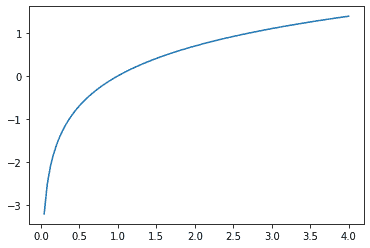
“对数”这个词让你想起了什么吗?对数函数有这个恒等式:
y = b**a a = log(y,b)
在这种情况下,我们假设log(y,b)返回log y 以 b 为底。然而,PyTorch 并没有这样定义log:Python 中的log使用特殊数字e(2.718…)作为底。
也许对数是您在过去 20 年中没有考虑过的东西。但对于深度学习中的许多事情来说,对数是一个非常关键的数学概念,所以现在是一个很好的时机来刷新您的记忆。关于对数的关键事情是这样的关系:
log(a*b) = log(a)+log(b)
当我们以这种格式看到它时,它看起来有点无聊;但想想这实际上意味着什么。这意味着当基础信号呈指数或乘法增长时,对数会线性增加。例如,在地震严重程度的里氏震级和噪音级别的分贝尺中使用。它也经常用于金融图表中,我们希望更清楚地显示复合增长率。计算机科学家喜欢使用对数,因为这意味着可以用加法代替修改,这样可以避免产生计算机难以处理的难以处理的规模。
Sylvain 说
不仅是计算机科学家喜欢对数!在计算机出现之前,工程师和科学家使用一种称为滑尺的特殊尺子,通过添加对数来进行乘法运算。对数在物理学中被广泛用于乘法非常大或非常小的数字,以及许多其他领域。
对我们的概率取正对数或负对数的平均值(取决于是否是正确或不正确的类)给出了负对数似然损失。在 PyTorch 中,nll_loss假设您已经对 softmax 取了对数,因此不会为您执行对数运算。
令人困惑的名称,注意
nll_loss中的“nll”代表“负对数似然”,但实际上它根本不进行对数运算!它假设您已经已经进行了对数运算。PyTorch 有一个名为log_softmax的函数,以快速准确的方式结合了log和softmax。nll_loss设计用于在log_softmax之后使用。
当我们首先进行 softmax,然后对其进行对数似然,这种组合被称为交叉熵损失。在 PyTorch 中,这可以通过nn.CrossEntropyLoss来实现(实际上执行log_softmax然后nll_loss):
loss_func = nn.CrossEntropyLoss()
正如您所看到的,这是一个类。实例化它会给您一个像函数一样行为的对象:
loss_func(acts, targ)
tensor(1.8045)
所有 PyTorch 损失函数都以两种形式提供,刚刚显示的类形式以及在F命名空间中提供的普通函数形式:
F.cross_entropy(acts, targ)
tensor(1.8045)
两者都可以正常工作,并且可以在任何情况下使用。我们注意到大多数人倾向于使用类版本,并且在 PyTorch 的官方文档和示例中更常见,因此我们也会倾向于使用它。
默认情况下,PyTorch 损失函数取所有项目的损失的平均值。您可以使用reduction='none'来禁用这一点:
nn.CrossEntropyLoss(reduction='none')(acts, targ)
tensor([0.5067, 0.6973, 2.0160, 5.6958, 0.9062, 1.0048])
Sylvain 说
当我们考虑交叉熵损失的梯度时,一个有趣的特性就出现了。cross_entropy(a,b)的梯度是softmax(a)-b。由于softmax(a)是模型的最终激活,这意味着梯度与预测和目标之间的差异成比例。这与回归中的均方误差相同(假设没有像y_range添加的最终激活函数),因为(a-b)**2的梯度是2*(a-b)。由于梯度是线性的,我们不会看到梯度的突然跳跃或指数增加,这应该导致模型的平滑训练。
我们现在已经看到了隐藏在我们损失函数背后的所有部分。但是,虽然这可以对我们的模型表现如何(好或坏)进行评估,但它对于帮助我们知道它是否好并没有任何帮助。现在让我们看看一些解释我们模型预测的方法。
模型解释
直接解释损失函数非常困难,因为它们被设计为计算机可以区分和优化的东西,而不是人类可以理解的东西。这就是为什么我们有指标。这些指标不用于优化过程,而只是帮助我们这些可怜的人类理解发生了什么。在这种情况下,我们的准确率已经看起来相当不错!那么我们在哪里犯了错误呢?
我们在第一章中看到,我们可以使用混淆矩阵来查看模型表现好和表现不佳的地方:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix(figsize=(12,12), dpi=60)

哦,亲爱的——在这种情况下,混淆矩阵很难阅读。我们有 37 种宠物品种,这意味着在这个巨大矩阵中有 37×37 个条目!相反,我们可以使用most_confused方法,它只显示混淆矩阵中预测错误最多的单元格(这里至少有 5 个或更多):
interp.most_confused(min_val=5)
[('american_pit_bull_terrier', 'staffordshire_bull_terrier', 10), ('Ragdoll', 'Birman', 6)]
由于我们不是宠物品种专家,很难知道这些类别错误是否反映了识别品种时的实际困难。因此,我们再次求助于谷歌。一点点搜索告诉我们,这里显示的最常见的类别错误是即使是专家育种者有时也会对其存在分歧的品种差异。因此,这让我们有些安慰,我们正在走在正确的道路上。
我们似乎有一个良好的基线。现在我们可以做些什么来使它变得更好呢?
改进我们的模型
我们现在将探讨一系列技术,以改进我们模型的训练并使其更好。在此过程中,我们将更详细地解释迁移学习以及如何尽可能最好地微调我们的预训练模型,而不破坏预训练权重。
在训练模型时,我们需要设置的第一件事是学习率。我们在上一章中看到,它需要恰到好处才能尽可能高效地训练,那么我们如何选择一个好的学习率呢?fastai 提供了一个工具来帮助。
学习率查找器
在训练模型时,我们可以做的最重要的事情之一是确保我们有正确的学习率。如果我们的学习率太低,训练模型可能需要很多个 epoch。这不仅浪费时间,还意味着我们可能会出现过拟合的问题,因为每次完整地遍历数据时,我们都给了模型记住数据的机会。
那么我们就把学习率调得很高,对吗?当然,让我们试试看会发生什么:
learn = cnn_learner(dls, resnet34, metrics=error_rate) learn.fine_tune(1, base_lr=0.1)
| epoch | train_loss | valid_loss | error_rate | time |
| 0 | 8.946717 | 47.954632 | 0.893775 | 00:20 |
| epoch | train_loss | valid_loss | error_rate | time |
| — | — | — | — | — |
| 0 | 7.231843 | 4.119265 | 0.954668 | 00:24 |
这看起来不太好。发生了什么呢。优化器朝着正确的方向迈出了一步,但它迈得太远,完全超过了最小损失。多次重复这样的过程会使其越来越远,而不是越来越接近!
我们该如何找到完美的学习率——既不太高也不太低?在 2015 年,研究员 Leslie Smith 提出了一个绝妙的想法,称为学习率查找器。他的想法是从一个非常非常小的学习率开始,一个我们永远不会认为它太大而无法处理的学习率。我们用这个学习率进行一个 mini-batch,找到之后的损失,然后按一定百分比增加学习率(例如每次加倍)。然后我们再做另一个 mini-batch,跟踪损失,并再次加倍学习率。我们一直这样做,直到损失变得更糟,而不是更好。这是我们知道我们走得太远的时候。然后我们选择一个比这个点稍低的学习率。我们建议选择以下任一:
- 比最小损失达到的地方少一个数量级(即最小值除以 10)
- 最后一次损失明显减少的点
学习率查找器计算曲线上的这些点来帮助您。这两个规则通常给出大致相同的值。在第一章中,我们没有指定学习率,而是使用了 fastai 库的默认值(即 1e-3):
learn = cnn_learner(dls, resnet34, metrics=error_rate) lr_min,lr_steep = learn.lr_find()

print(f"Minimum/10: {lr_min:.2e}, steepest point: {lr_steep:.2e}")
Minimum/10: 8.32e-03, steepest point: 6.31e-03
我们可以看到在 1e-6 到 1e-3 的范围内,没有什么特别的事情发生,模型不会训练。然后损失开始减少,直到达到最小值,然后再次增加。我们不希望学习率大于 1e-1,因为这会导致训练发散(您可以自行尝试),但 1e-1 已经太高了:在这个阶段,我们已经离开了损失稳定下降的阶段。
在这个学习率图中,看起来学习率约为 3e-3 可能是合适的,所以让我们选择这个:
learn = cnn_learner(dls, resnet34, metrics=error_rate) learn.fine_tune(2, base_lr=3e-3)
| epoch | train_loss | valid_loss | error_rate | time |
| 0 | 1.071820 | 0.427476 | 0.133965 | 00:19 |
| epoch | train_loss | valid_loss | error_rate | time |
| — | — | — | — | — |
| 0 | 0.738273 | 0.541828 | 0.150880 | 00:24 |
| 1 | 0.401544 | 0.266623 | 0.081867 | 00:24 |
对数刻度
学习率查找器图表采用对数刻度,这就是为什么在 1e-3 和 1e-2 之间的中间点在 3e-3 和 4e-3 之间。这是因为我们主要关心学习率的数量级。
有趣的是,学习率查找器是在 2015 年才被发现的,而神经网络自上世纪 50 年代以来一直在发展。在那段时间里,找到一个好的学习率可能是从业者面临的最重要和最具挑战性的问题。解决方案不需要任何高级数学、巨大的计算资源、庞大的数据集或其他任何使其对任何好奇的研究人员不可及的东西。此外,Smith 并不是某个独家的硅谷实验室的一部分,而是作为一名海军研究员工作。所有这些都是为了说:在深度学习中的突破性工作绝对不需要访问大量资源、精英团队或先进的数学思想。还有很多工作需要做,只需要一点常识、创造力和坚韧不拔。
现在我们有了一个好的学习率来训练我们的模型,让我们看看如何微调预训练模型的权重。
解冻和迁移学习
我们在第一章中简要讨论了迁移学习的工作原理。我们看到基本思想是,一个预训练模型,可能在数百万数据点(如 ImageNet)上训练,被为另一个任务进行微调。但这到底意味着什么?
我们现在知道,卷积神经网络由许多线性层组成,每对之间有一个非线性激活函数,然后是一个或多个最终的线性层,最后是一个诸如 softmax 之类的激活函数。最终的线性层使用一个具有足够列数的矩阵,使得输出大小与我们模型中的类数相同(假设我们正在进行分类)。
当我们在迁移学习设置中进行微调时,这个最终的线性层对我们来说可能没有任何用处,因为它专门设计用于对原始预训练数据集中的类别进行分类。因此,在进行迁移学习时,我们会将其移除、丢弃,并用一个新的线性层替换,该线性层具有我们所需任务的正确输出数量(在这种情况下,将有 37 个激活)。
这个新添加的线性层将完全随机的权重。因此,在微调之前,我们的模型具有完全随机的输出。但这并不意味着它是一个完全随机的模型!最后一个层之前的所有层都经过精心训练,以便在一般的图像分类任务中表现良好。正如我们在Zeiler 和 Fergus 论文中看到的那样,在第一章中(参见图 1-10 到 1-13),前几层编码了一般概念,比如找到梯度和边缘,后面的层编码了对我们仍然有用的概念,比如找到眼球和毛发。
我们希望以这样的方式训练模型,使其能够记住预训练模型中的所有这些通常有用的想法,用它们来解决我们的特定任务(分类宠物品种),并仅根据我们特定任务的具体要求进行调整。
在微调时,我们的挑战是用能够正确实现我们所需任务(分类宠物品种)的权重替换我们添加的线性层中的随机权重,而不破坏精心预训练的权重和其他层。一个简单的技巧可以实现这一点:告诉优化器仅更新那些随机添加的最终层中的权重。根本不要改变神经网络的其他部分的权重。这被称为冻结那些预训练的层。
当我们从预训练网络创建模型时,fastai 会自动为我们冻结所有预训练层。当我们调用fine_tune方法时,fastai 会做两件事:
- 训练随机添加的层一个周期,同时冻结所有其他层
- 解冻所有层,并根据请求的周期数进行训练
尽管这是一个合理的默认方法,但对于您的特定数据集,您可能通过稍微不同的方式做事情来获得更好的结果。fine_tune方法有一些参数可以用来改变其行为,但如果您想获得自定义行为,直接调用底层方法可能更容易。请记住,您可以使用以下语法查看该方法的源代码:
learn.fine_tune??
所以让我们尝试手动操作。首先,我们将使用fit_one_cycle训练随机添加的层三个周期。正如在第一章中提到的,fit_one_cycle是在不使用fine_tune的情况下训练模型的建议方法。我们将在本书后面看到原因;简而言之,fit_one_cycle的作用是以低学习率开始训练,逐渐增加学习率进行第一部分的训练,然后在最后一部分的训练中逐渐降低学习率:
learn = cnn_learner(dls, resnet34, metrics=error_rate) learn.fit_one_cycle(3, 3e-3)
| epoch | train_loss | valid_loss | error_rate | time |
| 0 | 1.188042 | 0.355024 | 0.102842 | 00:20 |
| 1 | 0.534234 | 0.302453 | 0.094723 | 00:20 |
| 2 | 0.325031 | 0.222268 | 0.074425 | 00:20 |
然后我们将解冻模型:
learn.unfreeze()
并再次运行lr_find,因为有更多层要训练,而且已经训练了三个周期的权重,意味着我们之前找到的学习率不再合适:
learn.lr_find()
(1.0964782268274575e-05, 1.5848931980144698e-06)
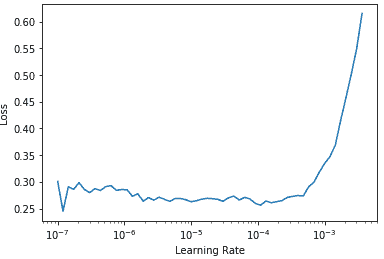
请注意,图表与随机权重时有所不同:我们没有那种表明模型正在训练的陡峭下降。这是因为我们的模型已经训练过了。在这里,我们有一个相对平坦的区域,然后是一个急剧增加的区域,我们应该选择在那个急剧增加之前的一个点,例如 1e-5。具有最大梯度的点不是我们在这里寻找的,应该被忽略。
让我们以适当的学习率进行训练:
learn.fit_one_cycle(6, lr_max=1e-5)
| epoch | train_loss | valid_loss | error_rate | time |
| 0 | 0.263579 | 0.217419 | 0.069012 | 00:24 |
| 1 | 0.253060 | 0.210346 | 0.062923 | 00:24 |
| 2 | 0.224340 | 0.207357 | 0.060217 | 00:24 |
| 3 | 0.200195 | 0.207244 | 0.061570 | 00:24 |
| 4 | 0.194269 | 0.200149 | 0.059540 | 00:25 |
| 5 | 0.173164 | 0.202301 | 0.059540 | 00:25 |
这稍微改进了我们的模型,但我们还可以做更多。预训练模型的最深层可能不需要像最后一层那样高的学习率,因此我们可能应该为这些层使用不同的学习率——这被称为使用区分性学习率。
区分性学习率
即使我们解冻后,我们仍然非常关心那些预训练权重的质量。我们不会期望那些预训练参数的最佳学习率与随机添加参数的学习率一样高,即使在我们为随机添加参数调整了几个轮数之后。请记住,预训练权重已经在数百个轮数中,在数百万张图像上进行了训练。
此外,您还记得我们在第一章中看到的图像吗?显示每个层学习的内容?第一层学习非常简单的基础知识,如边缘和梯度检测器;这些对于几乎任何任务都可能非常有用。后面的层学习更复杂的概念,如“眼睛”和“日落”,这些对您的任务可能完全没有用(也许您正在对汽车型号进行分类)。因此,让后面的层比前面的层更快地微调是有道理的。
因此,fastai 的默认方法是使用区分性学习率。这种技术最初是在我们将在第十章中介绍的 NLP 迁移学习的 ULMFiT 方法中开发的。就像深度学习中的许多好主意一样,这个方法非常简单:对神经网络的早期层使用较低的学习率,对后期层(尤其是随机添加的层)使用较高的学习率。这个想法基于Jason Yosinski 等人在 2014 年展示的见解,即在迁移学习中,神经网络的不同层应该以不同的速度训练,如图 5-4 所示。
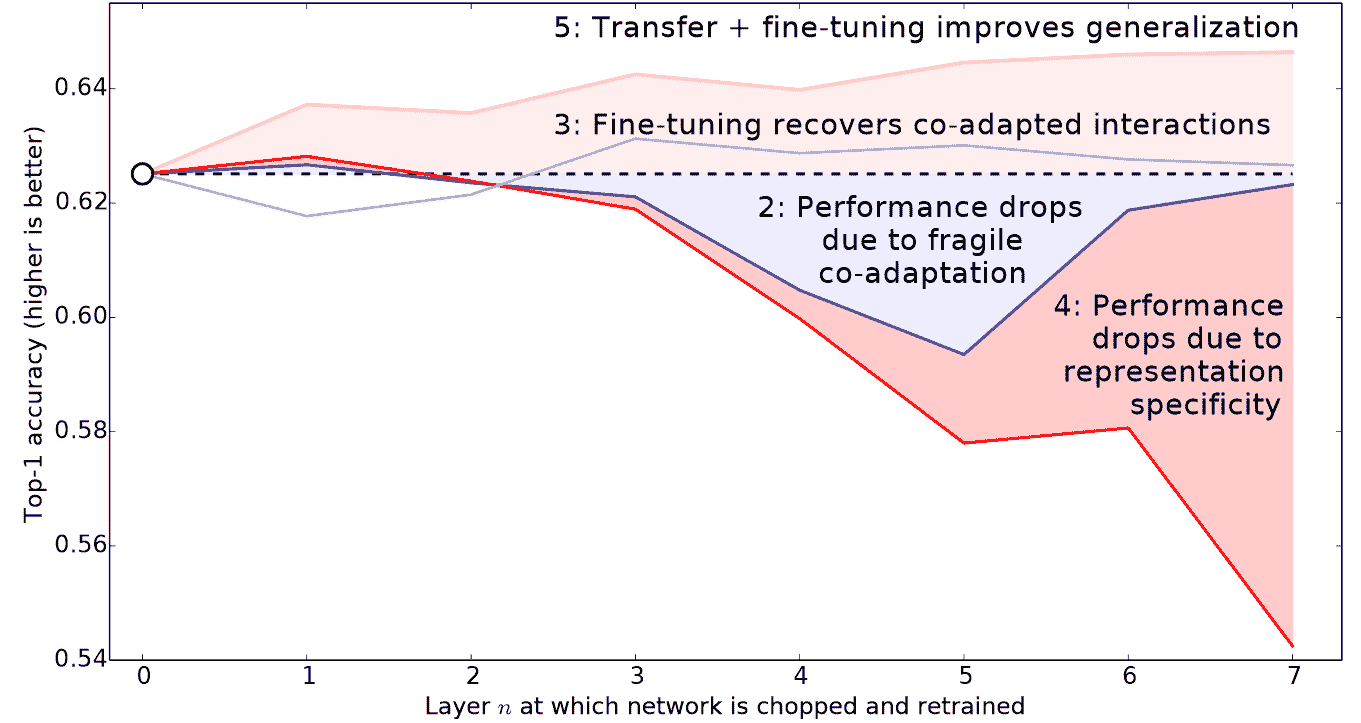
图 5-4。不同层和训练方法对迁移学习的影响(由 Jason Yosinski 等人提供)
fastai 允许您在任何需要学习率的地方传递 Python slice对象。传递的第一个值将是神经网络最早层的学习率,第二个值将是最后一层的学习率。中间的层将在该范围内等距地乘法地具有学习率。让我们使用这种方法复制先前的训练,但这次我们只将我们网络的最低层的学习率设置为 1e-6;其他层将增加到 1e-4。让我们训练一段时间,看看会发生什么:
learn = cnn_learner(dls, resnet34, metrics=error_rate) learn.fit_one_cycle(3, 3e-3) learn.unfreeze() learn.fit_one_cycle(12, lr_max=slice(1e-6,1e-4))
| 轮数 | 训练损失 | 验证损失 | 错误率 | 时间 |
| 0 | 1.145300 | 0.345568 | 0.119756 | 00:20 |
| 1 | 0.533986 | 0.251944 | 0.077131 | 00:20 |
| 2 | 0.317696 | 0.208371 | 0.069012 | 00:20 |
| 轮数 | 训练损失 | 验证损失 | 错误率 | 时间 |
| — | — | — | — | — |
| 0 | 0.257977 | 0.205400 | 0.067659 | 00:25 |
| 1 | 0.246763 | 0.205107 | 0.066306 | 00:25 |
| 2 | 0.240595 | 0.193848 | 0.062246 | 00:25 |
| 3 | 0.209988 | 0.198061 | 0.062923 | 00:25 |
| 4 | 0.194756 | 0.193130 | 0.064276 | 00:25 |
| 5 | 0.169985 | 0.187885 | 0.056157 | 00:25 |
| 6 | 0.153205 | 0.186145 | 0.058863 | 00:25 |
| 7 | 0.141480 | 0.185316 | 0.053451 | 00:25 |
| 8 | 0.128564 | 0.180999 | 0.051421 | 00:25 |
| 9 | 0.126941 | 0.186288 | 0.054127 | 00:25 |
| 10 | 0.130064 | 0.181764 | 0.054127 | 00:25 |
| 11 | 0.124281 | 0.181855 | 0.054127 | 00:25 |
现在微调效果很好!
fastai 可以展示训练和验证损失的图表:
learn.recorder.plot_loss()

正如你所看到的,训练损失一直在变得越来越好。但请注意,最终验证损失的改善会减缓,有时甚至会变得更糟!这是模型开始过拟合的时候。特别是,模型开始对其预测变得过于自信。但这并不意味着它一定变得不准确。看一下每个 epoch 的训练结果表,你会经常看到准确率持续提高,即使验证损失变得更糟。最终,重要的是你的准确率,或者更一般地说是你选择的指标,而不是损失。损失只是我们给计算机的函数,帮助我们优化。
在训练模型时,你还需要做出的另一个决定是训练多长时间。我们将在下面考虑这个问题。
选择 epochs 的数量
通常情况下,你会发现在选择训练多少个 epochs 时,你受到的限制更多是时间,而不是泛化和准确性。因此,你训练的第一步应该是简单地选择一个你愿意等待的时间内可以完成的 epochs 数量。然后查看训练和验证损失图,特别是你的指标。如果你看到它们甚至在最后几个 epochs 中仍在变得更好,那么你就知道你没有训练得太久。
另一方面,你可能会发现你选择的指标在训练结束时确实变得更糟。记住,我们不仅仅是在寻找验证损失变得更糟,而是实际的指标。你的验证损失在训练过程中会先变得更糟,因为模型变得过于自信,只有后来才会因为错误地记忆数据而变得更糟。在实践中,我们只关心后一种情况。记住,我们的损失函数是我们用来让优化器有东西可以区分和优化的,实际上我们关心的不是这个。
在 1cycle 训练出现之前,通常会在每个 epoch 结束时保存模型,然后从所有保存的模型中选择准确率最高的模型。这被称为早停。然而,这不太可能给出最好的答案,因为那些中间的 epochs 出现在学习率还没有机会达到小值的情况下,这时它才能真正找到最佳结果。因此,如果你发现你过拟合了,你应该重新从头开始训练模型,并根据之前找到最佳结果的地方选择一个总的 epochs 数量。
如果你有时间训练更多的 epochs,你可能会选择用这段时间来训练更多的参数,也就是使用更深的架构。
更深的架构
一般来说,具有更多参数的模型可以更准确地对数据进行建模。(对于这个泛化有很多很多的例外情况,这取决于你使用的架构的具体情况,但现在这是一个合理的经验法则。)对于我们将在本书中看到的大多数架构,你可以通过简单地添加更多层来创建更大的版本。然而,由于我们想使用预训练模型,我们需要确保选择已经为我们预训练的层数。
这就是为什么在实践中,架构往往只有少数几种变体。例如,在本章中使用的 ResNet 架构有 18、34、50、101 和 152 层的变体,都是在 ImageNet 上预训练的。一个更大的(更多层和参数;有时被描述为模型的容量)ResNet 版本总是能够给我们更好的训练损失,但它可能更容易过拟合,因为它有更多参数可以过拟合。
总的来说,一个更大的模型能够更好地捕捉数据的真实基本关系,以及捕捉和记忆你个别图像的具体细节。
然而,使用更深的模型将需要更多的 GPU 内存,因此你可能需要降低批量大小以避免内存不足错误。当你尝试将太多内容装入 GPU 时,就会发生这种情况,看起来像这样:
Cuda runtime error: out of memory
当发生这种情况时,你可能需要重新启动你的笔记本。解决方法是使用较小的批量大小,这意味着在任何给定时间通过你的模型传递较小的图像组。你可以通过使用bs=创建你想要的批量大小来调用。
更深层次架构的另一个缺点是训练时间要长得多。一个可以大大加快速度的技术是混合精度训练。这指的是在训练过程中尽可能使用不那么精确的数字(半精度浮点数,也称为 fp16)。截至 2020 年初,几乎所有当前的 NVIDIA GPU 都支持一种特殊功能,称为张量核心,可以将神经网络训练速度提高 2-3 倍。它们还需要更少的 GPU 内存。要在 fastai 中启用此功能,只需在创建Learner后添加to_fp16()(你还需要导入模块)。
你实际上无法提前知道适合你特定问题的最佳架构——你需要尝试一些训练。所以现在让我们尝试使用混合精度的 ResNet-50:
from fastai2.callback.fp16 import * learn = cnn_learner(dls, resnet50, metrics=error_rate).to_fp16() learn.fine_tune(6, freeze_epochs=3)
| epoch | train_loss | valid_loss | error_rate | time |
| 0 | 1.427505 | 0.310554 | 0.098782 | 00:21 |
| 1 | 0.606785 | 0.302325 | 0.094723 | 00:22 |
| 2 | 0.409267 | 0.294803 | 0.091340 | 00:21 |
| epoch | train_loss | valid_loss | error_rate | time |
| — | — | — | — | — |
| 0 | 0.261121 | 0.274507 | 0.083897 | 00:26 |
| 1 | 0.296653 | 0.318649 | 0.084574 | 00:26 |
| 2 | 0.242356 | 0.253677 | 0.069012 | 00:26 |
| 3 | 0.150684 | 0.251438 | 0.065629 | 00:26 |
| 4 | 0.094997 | 0.239772 | 0.064276 | 00:26 |
| 5 | 0.061144 | 0.228082 | 0.054804 | 00:26 |
你会看到我们又回到使用fine_tune,因为它非常方便!我们可以传递freeze_epochs告诉 fastai 在冻结时训练多少个周期。它将自动为大多数数据集更改学习率。
在这种情况下,我们没有从更深的模型中看到明显的优势。这是值得记住的——对于你的特定情况,更大的模型不一定是更好的模型!确保在扩大规模之前尝试小模型。
结论
在本章中,你学到了一些重要的实用技巧,既可以为建模准备图像数据(预调整大小,数据块摘要),也可以为拟合模型(学习率查找器,解冻,区分性学习率,设置周期数,使用更深的架构)。使用这些工具将帮助你更快地构建更准确的图像模型。
我们还讨论了交叉熵损失。这本书的这部分值得花费大量时间。在实践中,你可能不太可能需要自己从头开始实现交叉熵损失,但你需要理解该函数的输入和输出,因为它(或它的变体,正如我们将在下一章中看到的)几乎在每个分类模型中使用。因此,当你想要调试一个模型,或将一个模型投入生产,或提高一个模型的准确性时,你需要能够查看其激活和损失,并理解发生了什么以及为什么。如果你不理解你的损失函数,你就无法正确地做到这一点。
如果交叉熵损失函数还没有“点亮”你的灯泡,不要担心——你会理解的!首先,回到前一章,确保你真正理解了mnist_loss。然后逐渐地通过本章的笔记本单元格,逐步了解交叉熵损失的每个部分。确保你理解每个计算在做什么以及为什么。尝试自己创建一些小张量,并将它们传递给函数,看看它们返回什么。
记住:在实现交叉熵损失时所做的选择并不是唯一可能的选择。就像我们在回归中可以在均方误差和平均绝对差(L1)之间进行选择一样,这里也可以改变细节。如果您对可能有效的其他函数有其他想法,请随时在本章的笔记本中尝试!(但要注意:您可能会发现模型训练速度较慢,准确性较低。这是因为交叉熵损失的梯度与激活和目标之间的差异成比例,因此 SGD 始终会为权重提供一个很好的缩放步长。)
问卷调查
- 为什么我们首先在 CPU 上调整大小到较大尺寸,然后在 GPU 上调整到较小尺寸?
- 如果您不熟悉正则表达式,请查找正则表达式教程和一些问题集,并完成它们。查看书籍网站以获取建议。
- 对于大多数深度学习数据集,数据通常以哪两种方式提供?
- 查阅
L的文档,并尝试使用它添加的一些新方法。 - 查阅 Python
pathlib模块的文档,并尝试使用Path类的几种方法。 - 给出两个图像转换可能降低数据质量的示例。
- fastai 提供了哪种方法来查看
DataLoaders中的数据? - fastai 提供了哪种方法来帮助您调试
DataBlock? - 在彻底清理数据之前,是否应该暂停训练模型?
- 在 PyTorch 中,交叉熵损失是由哪两个部分组合而成的?
- softmax 确保的激活函数的两个属性是什么?为什么这很重要?
- 何时可能希望激活函数不具有这两个属性?
- 自己计算图 5-3 中的
exp和softmax列(即在电子表格、计算器或笔记本中)。 - 为什么我们不能使用
torch.where为标签可能有多于两个类别的数据集创建损失函数? - log(-2)的值是多少?为什么?
- 选择学习率时有哪两个好的经验法则来自学习率查找器?
fine_tune方法执行了哪两个步骤?- 在 Jupyter Notebook 中,如何获取方法或函数的源代码?
- 什么是区分性学习率?
- 当将 Python
slice对象作为学习率传递给 fastai 时,它是如何解释的? - 为什么在使用 1cycle 训练时,提前停止是一个不好的选择?
resnet50和resnet101之间有什么区别?to_fp16是做什么的?
进一步研究
- 找到 Leslie Smith 撰写的介绍学习率查找器的论文,并阅读。
- 看看是否可以提高本章分类器的准确性。您能达到的最佳准确性是多少?查看论坛和书籍网站,看看其他学生在这个数据集上取得了什么成就以及他们是如何做到的。
FastAI 之书(面向程序员的 FastAI)(三)(3)https://developer.aliyun.com/article/1483221
