如何使用 Sora? Sora4000 字全面入门教程
Sora 目前还在内测中,以 GPTs 的经验,大概率需要 GPT4 才能开通,感兴趣的同学可以看看我的 GPT4 开通教程
GPT Plus 升级 | GPT 航海 (gpthanghai.com)
Sora 彻底出圈了
最近,相比大家都能看到「SORA」这个词在各大媒体出现,甚至让央视都专门做报道去报道这个模型,可想而知这个模型有多火。下面上几张图让大家感受下,来自媒体,大众以及专家的热度
1、央媒亲自下场报道:央视非常罕见的报道 OPENAI 的最新模型,甚至成立了专栏,专门邀请国内 AI 应用以及科学家进行圆桌讨论,讨论该模型的影响
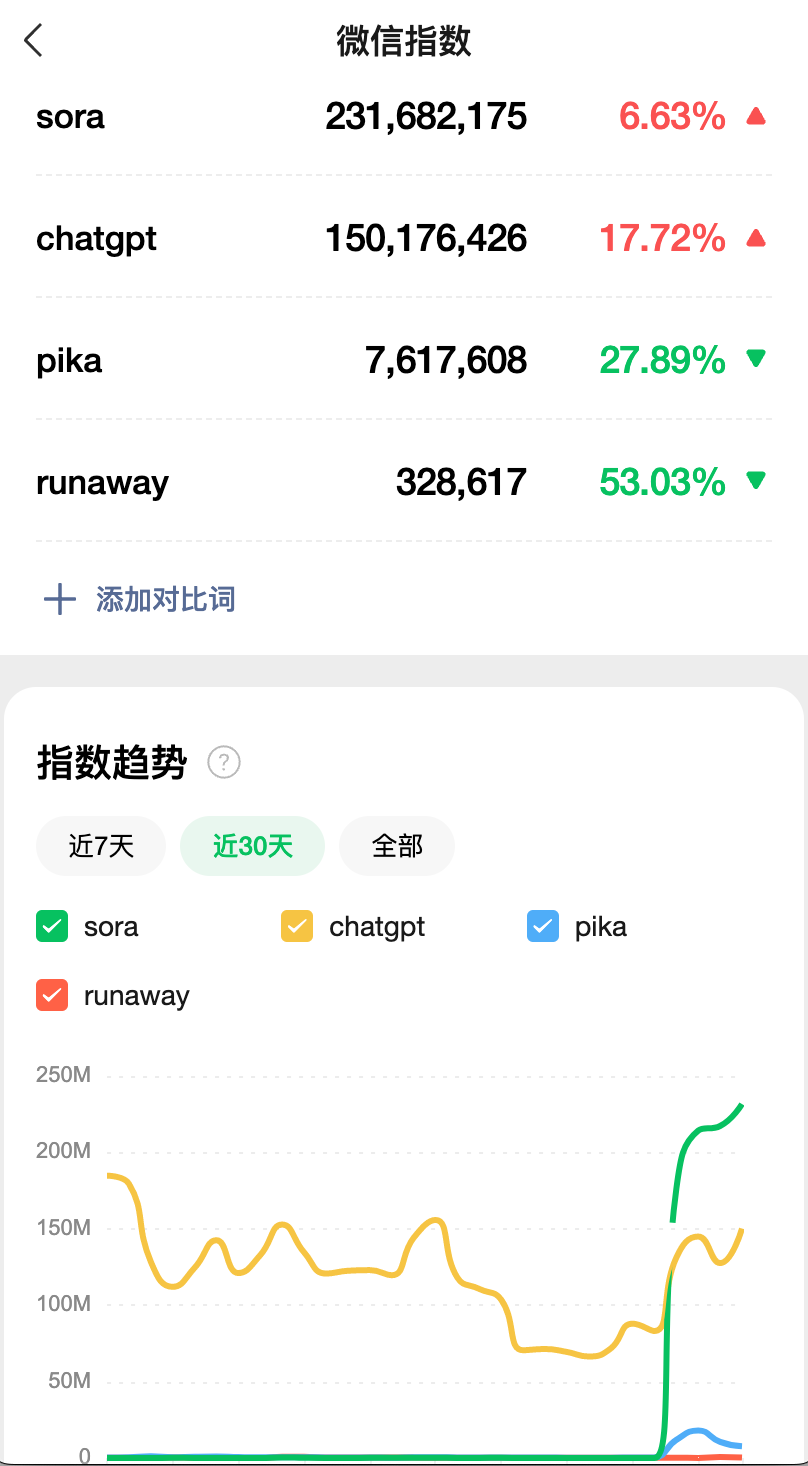
2、全民狂热:不管是媒体铺天盖地的文章和技术测评,还是全民主动搜索意愿,都能说明大家都被他的效果震惊到了
微信指数:sora 最近这几天的热度已经超过了 gpt
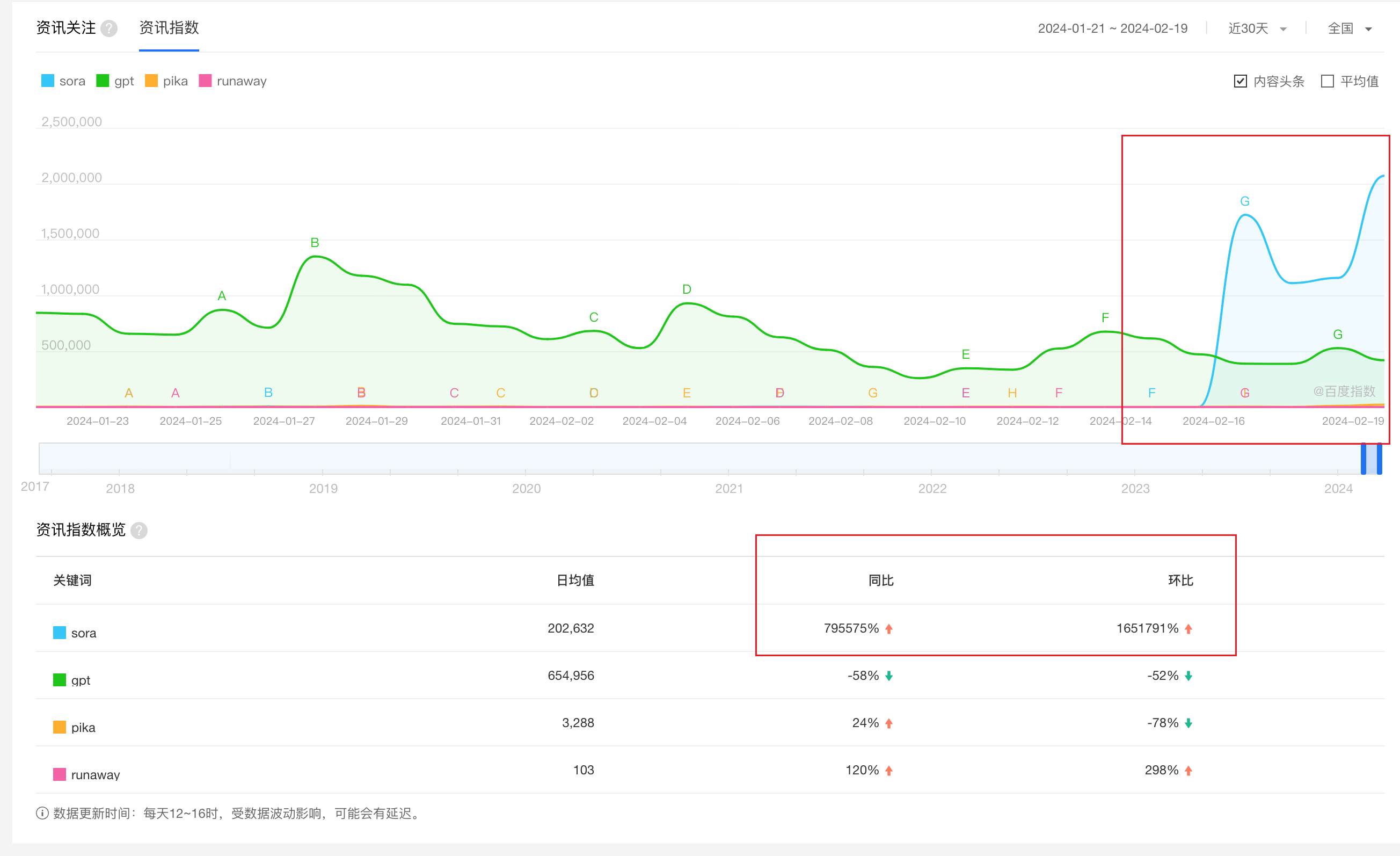
百度指数也侧面反映了 sora 的狂飙
3、媒体阅读量
AI 自媒体-卡兹克,凭借 SORA 的公众号文章,一篇文章一天突破了百万阅读
Sora 是什么
根据 OPENAI 的官网描述Sora (openai.com),SORA 是一个 文生视频的模型。
和之前的文生视频模型(pika,runaway,stable diffusion video)相比,他有两个最大的特点
- 可以生成一分钟的长视频(之前的生成大多数是 3-5s,这是 10 倍的飞跃!)
- 维持视频的高质量(最大感觉就是,保持时间的连续性,以及在远近景变换的时候,物体能够维持特性)
Sora 对语言有着深刻的理解,能够精准地捕捉到用户的需求,并创造出充满生命力、情感丰富的角色。此外,Sora 还能在同一视频中创造出多个画面,同时保持角色和视觉风格的一致性。
SORA 模型视频(官网有更全的视频,下面我截取其中几个视频)
Prompt:A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.
这是一个电影预告片的描述,讲述了一位 30 岁太空人的冒险故事,他戴着一顶红色羊毛编织的摩托车头盔,在蓝天和盐沼的背景下,采用电影风格,使用 35 毫米胶片拍摄,色彩鲜艳。
Prompt:Animated scene features a close-up of a short fluffy monster kneeling beside a melting red candle. The art style is 3D and realistic, with a focus on lighting and texture. The mood of the painting is one of wonder and curiosity, as the monster gazes at the flame with wide eyes and open mouth. Its pose and expression convey a sense of innocence and playfulness, as if it is exploring the world around it for the first time. The use of warm colors and dramatic lighting further enhances the cozy atmosphere of the image.
动画场景,特色是一个矮小、毛茸茸的怪物跪在一支融化的红色蜡烛旁的特写镜头。艺术风格是三维且逼真,重点在于光照和质地。画面的氛围充满了惊奇和好奇,因为怪物睁大眼睛、张开嘴巴凝视着火焰。它的姿势和表情传达了一种天真和顽皮感,仿佛它是第一次探索周围的世界。温暖的色彩使用和戏剧性的光照进一步增强了图片的舒适氛围。
Sora 和其他模型的区别
最大的区别就是,SORA 可以生成 1 分钟的稳定长视频,而且生成的画面质量远高于其他模型
大家可以通过以下两个维度自己去判断 Sora 模型和其他模型的区别
- 生成画面的质量:Sora 肉眼可见的生成了非常高质量的的画面,无论是时间上的连续性还是空间上的连续性(不同分镜下人物/物体的统一性)
- 视频的长度:Sora 大概是 1min,而其他模型基本是 3-4s
Sora:什么 pika,runaway 的,都给我跪下!

话不多说,直接上一段视频让大家感受一下 SORA 对比其他模型的区别
Sora 原理概述(可跳过)
非技术向的同学可以先跳过,这里简单介绍 SORA 的原理,感兴趣的同学,我会在后面出一篇文章介绍技术原理和相关的论文。
下面的原理来源于官网的技术报告,感兴趣的同学可以直接阅读原文:Video generation models as world simulators (openai.com)
核心 1:视觉数据(图像/视频)表示成成「patch」
借鉴与大语言模型通过 token 来处理数据,SORA 把视频数据进行统一编码,引入了 patch 的概念。patch 在技术报告中被证明了是一种很好的「表征视频/图像数据」的一种表示方法
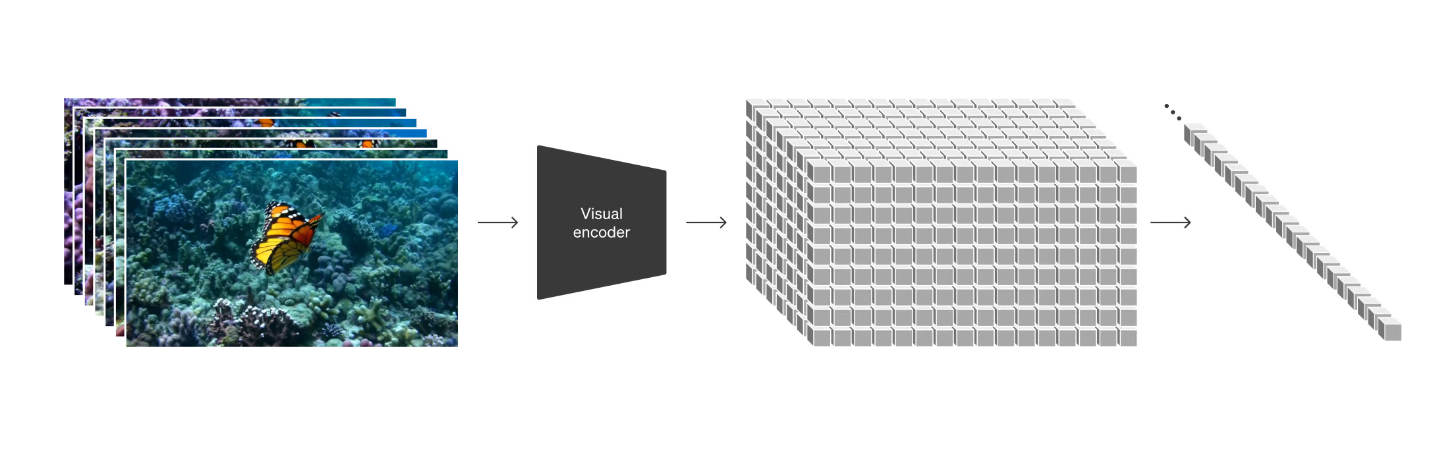
核心 2:视频压缩网络
这是一种可以减少视频数据维度的神经网络,通俗理解,就是把高维数据降到低维,可以减少训练量和推理的成本。最终是成对的,一个是编码器,另一个是解码器,目的是为了在训练的时候减少成本
编码:
输入:原来的视频
输出:在潜空间(latent space)的视频表示
解码
输入:在潜空间(latent space)的视频表示
输出:原来的视频
核心 3:时空的潜在(latent)patch 表示
类似 token 在 llm 是最小单元一样,在视频中,patch 就是最小处理单元。这里需要注意的是,作者支出,图像就是一帧的视频,这里蕴含的意义很大,意味着图像和视频一样,都可以用来训练和处理!!
核心 4:Transformer
Sora 是一个 diffusion 模型,通过接收带有噪声的图像块作为输入,训练预测清晰的图像块。
那么在图像/视频领域,最新处理单元变成了 patch,输入就是 带有噪声的 patch,输出组成视频块的 patch。
而这里作者发现,大力出奇迹在视频模型仍然使用!

技术文章科普
后续技术补充讨论:
sora vs runaway 技术架构区别:https://weibo.com/1727858283/O10mdso29
patch
Patch 只是预测生成结果的最小单位,一个 patch 可以只有几个画面帧中的一小点,不是说得一镜到底才行,类似于一个 token 只是一个单词或者半个单词
patch 还是很好翻译的,图像块。如果你学过图像处理的话,分块操作是十分常见的。分块好固定尺寸,方便写代码中的 for 循环。
感觉 patch 就是非常非常小的视频,小到像素级别就是颜色的连续变化,这些作为视频训练和生成的最小单位太合适了,因为里面天然就包含了连续变化的信息,这些连续变化的像素点的信息被学习后就可以被重新组装成更大的完整的视频
sora 技术推演:一文看 Sora 技术推演 (qq.com)
关于 patch:万字长文深度解析 Sora 的核心技术,解密 OpenAI 掌控时空的秘密武器 (weibo.com)
Sora 使用
目前使用 Sora 的唯一渠道就是 OpenAI,请大家以第一手信息为准,
Sora 变现
Sora 这次之所以引起这么大的轰动,还是因为效果太震撼了,看起来有非常多的应用场景,这里列出部分变现案例,拓宽大家的思路
售卖 Sora 账号或者邀请码
这是永恒不变的道理,每次技术浪潮下,就和淘金热一样,卖铲子永远是一个风险更低,且有一定收益的行为
售卖高质量的视频生成 prompt
类似 midjouyney 一样,早期模型的能力肯定还没到一句话生成高质量视频的情况,类比到 stable diffusion,此时一个模板市场能够很好的降低创作门槛
制作/代生成 ai 视频
这是基于 2 的延伸,需求永远都在,当技术的进步和成本的降低到达阈值,就会有人付费
使用 Sora 生成的视频,做个人的自媒体账号
现在是创意更重要,创意落地的过程被大大简化了,只需要博主/自媒体从业主有个好点子,点子 -> 视频的门槛也被降低了。
不只是视频,利用图片生成能力(midjourney & sd)在小红书上做 ai 头像定制,婴儿预测,以及模特换装的,都有不少人已经拿到结果了
电商:围绕 sora 搜索词做生意
信息差永远存在,围绕 sora 去做生意,找到对 ai 感兴趣的用户,具体的载体可以是课程,账号等。最重要是发现需求,以及确定潜在用户群体的付费意愿
sora 套壳网站
对于普通人门槛较高,但是对于程序员来说算是比较好的选择。
可以基于 sora 做个套壳网站,然后先套用其他生成视频的 api,先抢占流量,让客户付费,等 sora 真正推出 api 的时候在进行切换、
最新跟进:
- sora & elevenlab 生成有声视频 :https://weibo.com/1727858283/O1faAsWWw
非技术人员如何应对这次浪潮
- 不必过度焦虑:技术的替代往往都是 S 型发展,产业级别的替代需要成本和效率的双重考虑,所以并不会像某些自媒体所说「不用就会被淘汰」
- 尽快开始使用 sora,了解这个模型的能力和边界
- 结合自己的工作流,想下是否有可以结合的点,给自己的工作流提效
- 保持开放的心态:保持对模型的关注,可以多和周围相关的朋友一起探讨可以用来做什么,聚合多个人的想法,取长补短
Sora FAQ
Q:Sora 免费吗?
A:目前仅针对部分艺术家免费,可以填表格申请
We’ll be taking several important safety steps ahead of making Sora available in OpenAI’s products. We are working with red teamers — domain experts in areas like misinformation, hateful content, and bias — who will be adversarially testing the model.
附录:SORA 技术论文
Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhudinov. "Unsupervised learning of video representations using lstms." International conference on machine learning. PMLR, 2015.↩︎
Chiappa, Silvia, et al. "Recurrent environment simulators." arXiv preprint arXiv:1704.02254 (2017).↩︎
Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 (2018).↩︎
Vondrick, Carl, Hamed Pirsiavash, and Antonio Torralba. "Generating videos with scene dynamics." Advances in neural information processing systems 29 (2016).↩︎
Tulyakov, Sergey, et al. "Mocogan: Decomposing motion and content for video generation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.↩︎
Clark, Aidan, Jeff Donahue, and Karen Simonyan. "Adversarial video generation on complex datasets." arXiv preprint arXiv:1907.06571 (2019).↩︎
Brooks, Tim, et al. "Generating long videos of dynamic scenes." Advances in Neural Information Processing Systems 35 (2022): 31769-31781.↩︎
Yan, Wilson, et al. "Videogpt: Video generation using vq-vae and transformers." arXiv preprint arXiv:2104.10157 (2021).↩︎
Wu, Chenfei, et al. "Nüwa: Visual synthesis pre-training for neural visual world creation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.↩︎
Ho, Jonathan, et al. "Imagen video: High definition video generation with diffusion models." arXiv preprint arXiv:2210.02303 (2022).↩︎
Blattmann, Andreas, et al. "Align your latents: High-resolution video synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.↩︎
Gupta, Agrim, et al. "Photorealistic video generation with diffusion models." arXiv preprint arXiv:2312.06662 (2023).↩︎
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).↩︎↩︎
Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.↩︎↩︎
Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).↩︎↩︎
Arnab, Anurag, et al. "Vivit: A video vision transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.↩︎↩︎
He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.↩︎↩︎
Dehghani, Mostafa, et al. "Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution." arXiv preprint arXiv:2307.06304 (2023).↩︎↩︎
Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.↩︎
Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).↩︎
Sohl-Dickstein, Jascha, et al. "Deep unsupervised learning using nonequilibrium thermodynamics." International conference on machine learning. PMLR, 2015.↩︎
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in neural information processing systems 33 (2020): 6840-6851.↩︎
Nichol, Alexander Quinn, and Prafulla Dhariwal. "Improved denoising diffusion probabilistic models." International Conference on Machine Learning. PMLR, 2021.↩︎
Dhariwal, Prafulla, and Alexander Quinn Nichol. "Diffusion Models Beat GANs on Image Synthesis." Advances in Neural Information Processing Systems. 2021.↩︎
Karras, Tero, et al. "Elucidating the design space of diffusion-based generative models." Advances in Neural Information Processing Systems 35 (2022): 26565-26577.↩︎
Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.↩︎
Chen, Mark, et al. "Generative pretraining from pixels." International conference on machine learning. PMLR, 2020.↩︎
Ramesh, Aditya, et al. "Zero-shot text-to-image generation." International Conference on Machine Learning. PMLR, 2021.↩︎
Yu, Jiahui, et al. "Scaling autoregressive models for content-rich text-to-image generation." arXiv preprint arXiv:2206.10789 2.3 (2022): 5.↩︎
Betker, James, et al. "Improving image generation with better captions." Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8↩︎↩︎
Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.↩︎
Meng, Chenlin, et al. "Sdedit: Guided image synthesis and editing with stochastic differential equations." arXiv preprint arXiv:2108.01073 (2021).↩︎