
不同方向的陡峭度是不一样的,即不同维度的数值大小是不同。也就是说梯度下降的快慢是不同的:
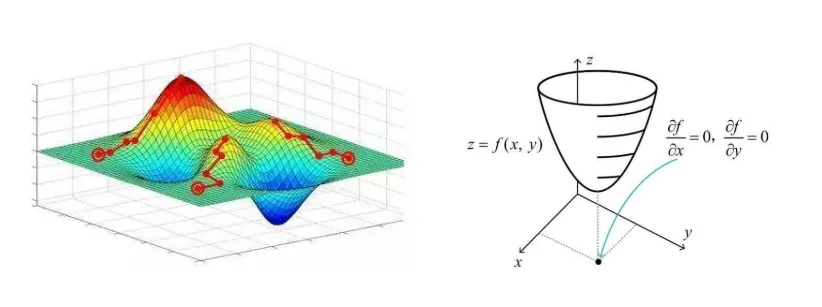
如果维度多了,就是超平面(了解一下霍金所说的宇宙十一维空间),很难画出来了。
如果拿多元线性回归举例的话,因为多元线性回归的损失函数 MSE 是凸函数,所以我们可以把损失函数看成是一个碗。然后下面的图就是从碗上方去俯瞰!哪里是损失最小的地方呢?当然对应的就是碗底的地方!所以下图碗中心的地方颜色较浅的区域就是损失函数最小的地方。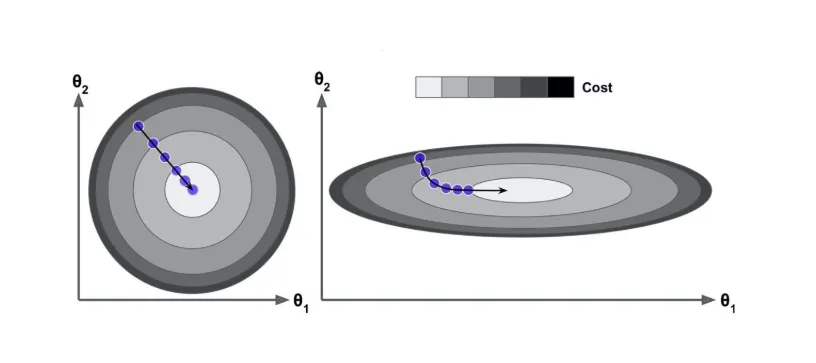
上面两张图都是进行梯度下降,你有没有发现,略有不同啊?两张图形都是鸟瞰图,左边的图形做了归一化处理,右边是没有做归一化的俯瞰图。
啥是归一化呢?请带着疑问跟我走~
我们先来说一下为什么没做归一化是右侧图示,举个例子假如我们客户数据信息,有两个维度,一个是用户的年龄,一个是用户的月收入,目标变量是快乐程度。
| name | age | salary | happy |
|---|---|---|---|
| 路博通 | 36 | 7000 | 100 |
| 马老师 | 42 | 20000 | 180 |
| 赵老师 | 22 | 30000 | 164 |
| …… | …… | …… | …… |
我们可以里面写出线性回归公式, $y = \theta_1x_1 + \theta_2x_2 + b$ ,那么这样每一条样本不同维度对应的数量级不同,原因是每个维度对应的物理含义不同嘛,但是计算机能理解 36 和 7000 分别是年龄和收入吗?计算机只是拿到一堆数字而已。
我们把 $x_1$ 看成是年龄,$x_2$ 看成是收入, y 对应着快乐程度。机器学习就是在知道 X,y的情况下解方程组调整出最优解的过程。根据公式我们也可以发现 y 是两部分贡献之和,按常理来说,一开始并不知道两个部分谁更重要的情况下,可以想象为两部分对 y 的贡献是一样的即 $\theta_1x_1 = \theta_2x_2$ ,如果 $x_1 \ll x_2$ ,那么最终 $\theta_1 \gg \theta_2$ (远大于)。
这样是不是就比较好理解为什么之前右侧示图里为什么 $\theta_1 > \theta_2$ ,看起来就是椭圆。再思考一下,梯度下降第 1 步的操作,是不是所有的维度 $\theta$ 都是根据在期望 $\mu$ 为 0 方差 $\sigma$ 为 1 的正太分布随机生成的,说白了就是一开始的 $\theta_1$ 和 $\theta_2$ 数值是差不多的。所以可以发现 $\theta_1$ 从初始值到目标位置 $\theta_1^{target}$ 的距离要远大于 $\theta_2$ 从初始值到目标位置$\theta_2^{target}$。
因为 $x_1 \ll x_2$,根据梯度公式 $gj= (h{\theta}(x) - y)x_j$ ,得出 $g_1 \ll g_2$。根据梯度下降公式:$\theta_j^{n+1} = \theta_j^n - \eta * g_j$ 可知,每次调整 $\theta_1$ 的幅度 $\ll$ (远小于) $\theta_2$ 的调整幅度。
总结一下 ,根据上面得到的两个结论 ,它俩之间是互相矛盾的 ,意味着最后 $\theta_2$ 需要比 $\theta_1$ 更少的迭代次数就可以收敛,而我们要最终求得最优解,就必须每个维度 $\theta$ 都收敛才可以,所以会出现 $\theta_2$ 等待 $\theta_1$ 收敛的情况。讲到这里对应图大家应该可以理解为什么右图是先顺着 $\theta_2$ 的坐标轴往下走再往右走的原因了吧。
结论:
归一化的一个目的是,使得梯度下降在不同维度 $\theta$ 参数(不同数量级)上,可以步调一致协同的进行梯度下降。这就好比社会主义,一小部分人先富裕起来了,先富带后富,这需要一定的时间,先富的这批人等待其他的人富裕起来;但是,更好途经是实现共同富裕,最后每个人都不能落下, 优化的步伐是一致的。
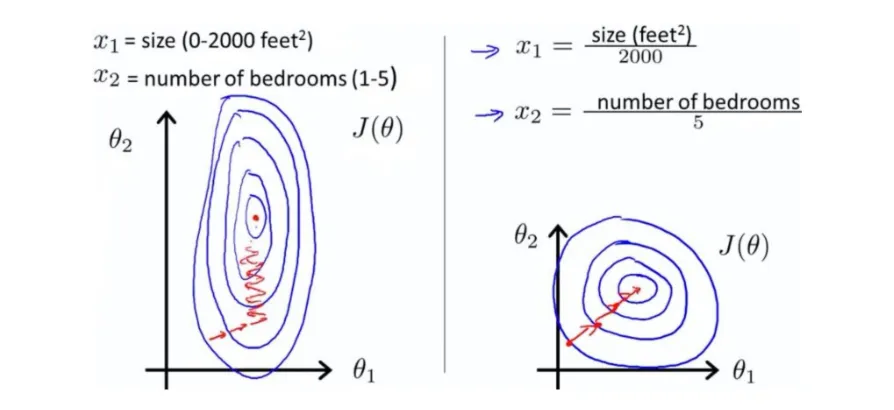
经过归一化处理,收敛的速度,明显快了!


