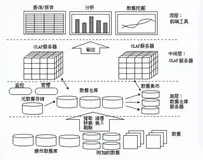
随着互联网的迅猛发展和各类传感器的普及,数据量呈指数级增长。按照国际数据公司(IDC)的预测,到2025年,全球数据总量将达到175ZB(1 ZB = 10^21字节)。这个庞大的数据量为我们提供了无限的机遇,但同时也带来了前所未有的挑战。
首先,数据的增长速度远远超过了传统数据处理工具的处理能力。单台服务器或单个计算节点很难处理如此庞大的数据集。因此,分布式计算成为了解决大规模数据处理的重要手段之一。通过将任务划分为多个子任务,并在多台计算节点上并行处理,分布式计算系统可以显著提高数据处理的效率和速度。
其次,数据的多样性和复杂性也给数据处理带来了挑战。传统上,数据处理主依赖于结构化数据,如关系型数据库中的表格数据。然而,大规模数据处理需要同时处理结构化数据、半结构化数据和非结构化数据,如文本、图像、音频和视频等。这就需要采用新的技术和算法,如自然语言处理、图像识别和深度学习等,来处理和分析这些不同类型的数据。
另外,数据的质量和准确性也是大规模数据处理的关键问题。随着数据量的增加,数据中可能存在噪声、缺失和错误等问题,这会对数据分析和决策造成严重影响。因此,数据清洗和数据质量控制成为了大规模数据处理的重要环节。通过采用数据清洗、异常检测和数据校验等技术手段,可以提高数据的质量和准确性,从而更可靠地进行数据分析和应用。
此外,云计算的兴起也为大规模数据处理提供了新的解决方案。云计算平台提供了弹性计算资源和灵活的数据存储服务,可以根据需求动态分配计算资源,从而满足大规模数据处理的需求。通过将数据存储在云端,并利用云计算平台的高性能计算能力,可以实现快速、高效的数据处理和分析。
最后,人工智能技术的发展也为大规模数据处理带来了新的机遇和突破。人工智能算法可以通过学习和推理来自动分析和挖掘庞大的数据集,从而发现隐藏在数据背后的规律和模式。例如,机器学习算法可以通过训练模型来预测销售趋势、用户行为和市场需求等重要信息,为决策提供有力支持。
综上所述,大规模数据处理是当今数字化时代面临的重要挑战之一。通过采用分布式计算、云计算和人工智能等技术手段,我们可以有效地处理和分析海量数据,并从中获得更多的机遇和创新。未来,随着技术的不断发展和创新,大规模数据处理将继续演进,为各个领域带来更大的发展潜力。