简介
随着数据爆炸式的增长,传统的OLTP和OLAP解决方案基于简单的读写分离或ETL模型,将在线库的数据以T+1的方式抽取到数据仓库中进行计算,这种方案存在存储成本高、实时性差、链路和维护成本高等缺陷。 为应对数据爆炸式增长的挑战,PolarDB分布式版本基于对象存储设计了一套列存索引(Clustered Columnar Index,CCI)功能,支持将行存数据实时同步到列存存储上,并支持以下功能:
- 在线事务处理和实时数据分析的一体化能力,满足OLTP和OLAP混合场景的需求。
结合PolarDB分布式架构,列存索引支持智能路由和MPP查询加速技术。计算层会精确识别出TP和AP的流量,并智能地将TP和AP流量分别路由到不同的存储介质上,同时确保在AP链路上默认开启MPP并行查询技术扫描列存索引,从而提升查询分析的能力。
采用Delta+Main模型,满足秒级的实时更新,结合MVCC多版本技术,能确保在任何时刻都可以读取到一致性的快照数据。
PolarDB分布式版将给您提供低成本、实时性高,完全兼容MySQL的一体化透明的HTAP解决方案。
版本要求
仅企业版实例支持列存索引
实例版本需满足 >= polarx-kernel_5.4.19-16989811_xcluster-20231019
技术架构
行列混存
核心组件
计算节点(Compute Node,CN),计算节点是系统的入口,采用无状态设计,包括 SQL 解析器、优化器、执行器等模块。负责数据分布式路由、计算及动态调度,负责分布式事务 2PC 协调、全局二级索引维护等,同时提供 SQL 限流、三权分立等企业级特性。
存储节点 (Data Node,DN),存储节点负责数据的持久化(面相行存数据),基于多数派 Paxos 协议提供数据高可靠、强一致保障,同时通过 MVCC 维护分布式事务可见性,另外提供计算下推能力满足分布式的计算下推要求(比如Project/Filter/Join/Agg等下推计算)。
元数据服务(Global Meta Service,GMS),元数据服务负责维护全局强一致的 Table/Schema, Statistics 等系统 Meta 信息,维护账号、权限等安全信息,同时提供全局授时服务(即 TSO)。
日志节点(Change Data Capture,CDC),日志节点提供完全兼容 MySQL Binlog 格式和协议的增量订阅能力,提供兼容 MySQL Replication 协议的主从复制能力。
列存引擎 (Columnar),列存引擎提供持久化列存索引,实时消费分布式事务的binlog日志,基于对象存储介质构建列存索引,能满足实时更新的需求、以及结合计算节点可提供列存的快照一致性查询能力。
列存架构
架构理念
随着云原生技术的不断普及,以Snowflake为代表的新一代云原生数仓、以及数据库HTAP架构不断创新,可见在未来一段时间后行列混存HTAP会成为一个数据库的标配能力,需要在当前数据库列存设计中面相未来的低成本、易用性、高性能上有更多的思考
PolarDB-X提供列存索引的形态(Clustered Columnar Index,CCI),行存表默认有主键索引和二级索引,列存索引是一份额外基于列式结构的二级索引(覆盖行存所有列),一张表可以同时具备行存和列存的数据。
架构特点
1.云原生架构(存计分离、低成本)
PolarDB-X 列存索引,采用云原生对象存储OSS作为主要数据存储(成本仅为本地盘的1/6 ~ 1/10),同时结合列存数据本身的高压缩性(3~5倍),可以提供非常有竞争力的低成本优势。在构建HTAP行列混存的场景,额外的列存存储成本,可以控制在行存的存储成本5%~10%。
PolarDB-X 列存索引的存储采用Delta+Main(类LSM结构)二层模型 + 标记删除的技术,确保列存索引使用对象存储OSS也具备高并发更新能力。同时,在列存读取对象存储OSS的链路上,采用多层数据Local Cache、以及多级统计信息机制,尽量减少不必要的远端OSS存储访问。
2.分布式 (线性扩展)
传统分布式数据库,业界常见基于Paxos/Raft的多副本机制构建列存,但OLTP和OLAP各自的查询场景会有不同的诉求,对资源的依赖程度也不同,不同副本之间强一致分区策略/扩缩容机制,使得TP和AP的线性扩容能力容易相互制约,影响性能。
PolarDB-X 列存索引,基于分布式事务的binlog日志实时同步,实现行转列(M:N)的异构转换,同时可以定义列存索引特有的分布式分区键、排序键等,结合分布式的并行技术,提供列存查询的线性扩展能力。同时行存和列存存储介质相互隔离,存储和计算资源也更易弹性,在分布式背景下列存查询更易追求极致的线性扩展能力。
3.读写分离(serverless,按读的使用付费)
PolarDB-X 列存索引,采用组件写和读分离的架构设计,分为列存写和列存读。列存的写节点(Columnar节点),属于有状态的节点,并不直接对外提供写请求,通过Group Commit技术批量更列存索引数据。列存的读节点(CN节点),继承CN节点无状态的设计,通过GMS节点获取列存的元数据,直接访问OSS对象存储上的列存索引数据。
PolarDB-X 实例创建,系统会默认提供列存写的组件(Columnar节点,长期运行并同步列存索引),用户只需通过DDL语法创建列存索引后,列存索引数据就会自动构建并保持实时更新。业务可以通过主实例、或者购买新的只读实例(CN节点),就可以正常访问行存和列存索引,同时无状态的CN节点特别适合serverless模式,用户只需为列存读的使用付费。
4.行列混合 (易用性,一体化向量化SQL引擎)
PolarDB-X 复用CN节点自研的SQL引擎,提供了列存读的完整能力。构建面向行列混合场景的代价优化器,根据代价智能识别路由,将OLTP类查询转发给行存查询链路、以及将OLAP类查询转发列存查询链路,同时支持在SQL算子级别访问不同的行存和列存,全面落实HTAP的行列混合能力,支持一套SQL引擎的统一访问。
PolarDB-X 全面拥抱向量化,针对列存的TableScan读取,采用列式chunk的数据结构,后续中间的算子计算也全面继承chunk的内存列式结构,基于全链路的向量化提升查询性能。同时针对行存的TableScan也会动态转化为列式chunk,基于统一的数据结构实现行列混合查询。
5.库仓一站式(Zero-ETL)
传统数据仓库,会通过数据ETL方式同步数据,采用MPP/BSP等并行计算架构可以很好解决OLAP复杂查询,但面相高并发的数据在线查询(Serving场景)会有明显的资源并发瓶颈,会通过数据回流到OLTP数据库提供在线查询。
PolarDB-X结合ADB提供了库仓一站式的能力,基于“Zero-ETL”的设计理念,采用共享同一份列存索引的数据,基于ADB的数据仓库能力可以满足多方的数据汇总和数据关联查询,提供传统意义上的数仓和湖的分析。同时,针对在线数据的并发查询可以使用PolarDB-X的HTAP行列混合架构,整个过程可以避免传统的数据ETL。
技术原理
使用语法
PolarDB-X对MySQL DDL语法进行了扩展,增加定义CCI的语法,使用方式与在MySQL上创建索引一致,可以参考列存索引的语法文档

CLUSTERED COLUMNAR:关键字,用于指定添加的索引类型为CCI。
索引名:索引表的名称,用于在SQL语句中指定该索引。
排序键:索引的排序键,即数据在索引文件中按照该列有序存储。
索引分区子句:索引的分区算法,与CREATE TABLE中分区子句的语法一致。
实际例子:
# 先创建表
CREATE TABLE t_order (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`order_id` varchar(20) DEFAULT NULL,
`buyer_id` varchar(20) DEFAULT NULL,
`seller_id` varchar(20) DEFAULT NULL,
`order_snapshot` longtext DEFAULT NULL,
`order_detail` longtext DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `l_i_order` (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 partition by hash(`order_id`) partitions 16;
# 再创建列存索引
CREATE CLUSTERED COLUMNAR INDEX `cc_i_seller` ON t_order (`seller_id`) partition by hash(`order_id`) partitions 16;
主表:"t_order" 是分区表,分区的拆分方式为按照 "order_id" 列进行哈希。
列存索引:"cc_i_seller" 按照 "seller_id" 列进行排序,按照 "order_id" 列进行哈希。
索引定义子句:CLUSTERED COLUMNAR INDEX cc_i_seller ON t_order (seller_id) partition by hash(order_id) partitions 16。
列存索引的构建
列存索引是由列存引擎节点来构造的,构建的数据最终会以CSV+ORC两种数据格式,存储在共享对象上。其中CSV往往存储的是实时的增量数据,过多的增量数据会及时做compaction,转储成ORC格式。不管是CSV还是ORC格式,PolarDB分布式版本对两种存储格式都做了增强,既继承了原生格式的开源开放的特征,又确保了这两类格式可以完全表达MySQL的数据协议。
从数据同步去看,构建过程往往是由全量快照读取+增量同步两条并行的同步链路共同完成的。先建列存索引,再导数据,这个场景下只有增量数据同步,Columnar节点会同时消费Binlog数据,构建索引;先导入部分数据,再建列存索引,继续导数据,这个场景除了有增量同步链路,Columnar节点会同时消费已有的全量数据,增量和全量并行消费,提速列存构建的效率。
从层次结构去看,列存引擎节点采用Delta+Main(类LSM结构)二层模型,采用了标记删除的技术,确保了行存和列存之间实现低延时的数据同步,可以保证秒级的实时更新。数据实时写入到MemTable,在一个group commit的周期内,会将数据存储到一个本地csv文件,并追加到OSS上对应csv文件的尾部,这个文件称为delta文件。OSS对象存储上的.csv文件不会长期存在,而是由compaction线程不定期地转换成.orc文件。
查询加速技术
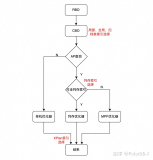
PolarDB分布式版本的流量是由计算节点(CN)承担,做查询分析。
从上图可以看整个查询加速链条分为优化器、执行器、存储引擎三个层面。 从优化器看,PolarDB分布式版本提供了面向行列混合场景的代价优化器,根据代价智能识别路由,将TP类查询转发给行存查询链路;将AP类查询转发列存查询链路。
从执行器看,PolarDB分布式提供的是面向行列混合场景的一体化执行器,一套执行器同时支持HTAP场景。同时算子层做了向量化改造,支持了MPP加速加速技术,在复杂查询场景中,可以充分利用多节点资源并行计算,保证了高吞吐的复杂查询需求。
为了抵消存储计算分离架构带来的网络延迟,执行器层也引入了本地缓存技术,将热数据实时加载到本地磁盘,保证了低延迟的查询需求。 从存储引擎看,列存索引的构建保证了事务提交的原子性,确保查询上可以查询到事务级别一致性的数据。
产品形态

在引入了列存引擎后,PolarDB分布式版本在原有的主实例和只读实例产品规格之外,增加了列存只读实例产品规格。
主实例:默认只能查询行存数据,配合只读实例,其提供的主实例集群地址,可以提供透明强一致性的读写分离能力。主实例上保留了直接查询列存数据的能力,后面也会逐步放开智能路由、以及行列混合查询能力。
只读实例:支持查询行存只读、以及列存索引的数据,提供了独立的只读连接地址,可以由应用单独连接,由应用侧自主做读写分离。
列存只读实例:仅能查询列存索引的数据,提供了独立的只读连接地址,由应用单独连接。列存只读实例仅包含CN计算节点,有更好的价格优势,可以参考列存只读实例产品定价。
适用场景
PolarDB 分布式版的列存索引特性提供了一站式HTAP产品体验,可以应用于多种业务场景:
对在线数据有秒级的实时数据分析需求的场景,如实时报表业务;
专用数据仓库场景:依托PolarDB分布式提供的海量数据存储能力,汇聚多个上游数据源,将其作为专用数据仓库使用;
ETL计算场景:依托PolarDB分布式基于列存索引提供的强大而灵活的计算能力。
PolarDB分布式版本结合列存索引特性,其优势不仅仅在于一套数据库产品可以同时解决TP和AP的混合场景需求,同时基于云原生的对象存储和智能路由技术,给用户提供的是透明的低成本的HTAP解决方案。
- 性能数据
测试集:TPC-H 100GB 硬件环境
- CPU:Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
软件
- OS版本:Linux version 5.10.134-15.al8.x86_64
涉及TPC-H的表,在线增加列存索引,整个测试操作可以参考列存索引TPC-H性能白皮书
create clustered columnar index `nation_col_index` on nation(`n_nationkey`) partition by hash(`n_nationkey`) partitions 1;
create clustered columnar index `region_col_index` on region(`r_regionkey`) partition by hash(`r_regionkey`) partitions 1;
create clustered columnar index `customer_col_index` on customer(`c_custkey`) partition by hash(`c_custkey`) partitions 24;
create clustered columnar index `part_col_index` on part(`p_size`) partition by hash(`p_partkey`) partitions 24;
create clustered columnar index `partsupp_col_index` on partsupp(`ps_partkey`) partition by hash(`ps_partkey`) partitions 24;
create clustered columnar index `supplier_col_index` on supplier(`s_suppkey`) partition by hash(`s_suppkey`) partitions 24;
create clustered columnar index `orders_col_index` on orders(`o_orderdate`,`o_orderkey`) partition by hash(`o_orderkey`) partitions 24;
create clustered columnar index `lineitem_col_index` on lineitem(`l_shipdate`,`l_orderkey`) partition by hash(`l_orderkey`) partitions 24;
基于列存索引的TPC-H运行,以下结果的时间单位为:秒(s)

上表展示了列存索引 TPC-H 100G 的性能随着规格等比变化的提升比例,体现了分布式的线性扩展能力。
数据库PolarDB-X新人入门一站式页面,快速体验集中分布式一体化新特性!