
✌ 独热编码和 LabelEncoder标签编码
1、✌ 介绍
对于一些特征工程,我们有时会需要使用OneHotEncoder和LabelEncoder两种编码
这是为了解决一些非数字分类问题。
比如说对于性别这个分类:male和female。这两个值可见是不能放入模型中的,所以就需要将其编码成数字。
例如:
| 特征 | 编码 |
| 男 | 1 |
| 女 | 0 |
| 女 | 0 |
| 男 | 1 |
| 女 | 0 |
| 男 | 1 |
对于LabelEncoder会将其转化成0、1这种数值分类,如果有三类就会变成0、1、2。
而利用OneHotEncoder就会转化成矩阵形式
| 特征 | Sex_男 | Sex_女 |
| 男 | 1 | 0 |
| 女 | 0 | 1 |
| 女 | 0 | 1 |
| 男 | 1 | 0 |
| 女 | 0 | 1 |
| 男 | 1 | 0 |
那么问题来了这两种方法都可以进行编码,有什么区别吗?
- 使用LabelEncoder该特征仍是一维,但是会产生0、1、2、3这种编码数字
- OneHotEncoder会产生线性无关的向量
如果对于红色、蓝色、绿色来说,编码后会产生0、1、2,这是就会产生新的数学关系,如绿色大于红色,绿色和红色的均值为蓝色,而这些类别是相互独立的类别,在转化之前是没有这些关系的。
但如果用OneHotEncoder,会产生多个线性无关的向量,解决了那种关系的问题,但是这样如果类别较多时,会使特征维度大大升高,造成资源浪费和运算时间长、矩阵过于稀疏等问题,但有些时候可以联系PCA进行使用。
2、✌ 代码测试
2.1 ✌ 导入相关库
import numpy as np import pandas as pd # 导入SVC模型 from sklearn.svm import SVC # 导入评分指标 from sklearn.metrics import accuracy_score from sklearn.metrics import roc_auc_score from sklearn.metrics import roc_curve # 编码库 from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder # 交叉验证 from sklearn.model_selection import cross_val_score
2.2 ✌ 读取数据
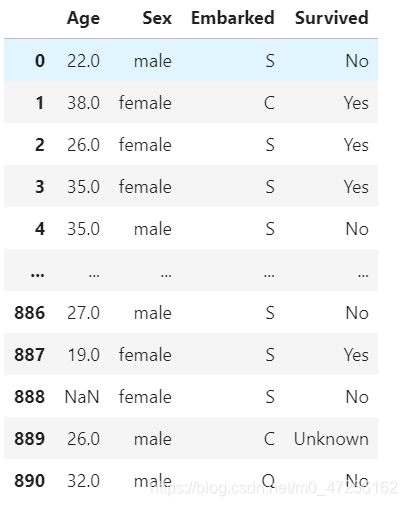
data=pd.read_csv('Narrativedata.csv',index_col=0) data
2.3 ✌ 查看缺失值

data.isnull().sum()
2.4 ✌ 利用中位数填补年龄

data['Age'].fillna(data['Age'].median(),inplace=True) data.isnull().sum()
2.5 ✌ 删除Embarked的缺失行

data.dropna(inplace=True) data.isnull().sum()
2.6 ✌ 查看每个特征的类别

display(np.unique(data['Sex'])) display(np.unique(data['Embarked'])) display(np.unique(data['Survived']))
x=data.drop(columns=['Survived']) y=data['Survived']
2.7 ✌ 对标签进行LabelEncoder编码

from sklearn.preprocessing import LabelEncoder y=LabelEncoder().fit_transform(y) y
2.8 ✌ 利用pandas的哑变量处理

y=data['Survived'] y=pd.get_dummies(y) y
2.9 ✌ 对特征进行哑变量处理
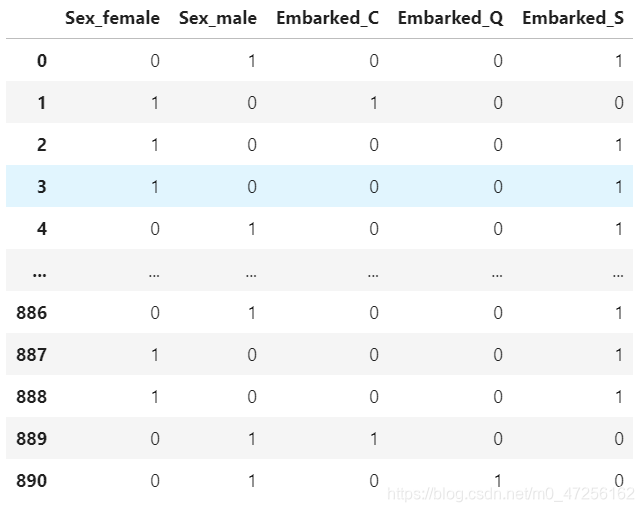
x=pd.get_dummies(x.drop(columns=['Age'])) x
2.10 ✌ 对特征进行独热编码

from sklearn.preprocessing import OneHotEncoder x=data.drop(columns=['Survived','Age']) x=OneHotEncoder().fit_transform(x).toarray() pd.DataFrame(x)
2.11 、✌ 模型测试
2.11.1 ✌ 独热编码
x=data.drop(columns=['Age','Survived']) y=data['Survived'] x=pd.get_dummies(x) x['Age']=data['Age'] y=LabelEncoder().fit_transform(y) # 模型测试 for kernel in ["linear","poly","rbf","sigmoid"]: clf = SVC(kernel = kernel ,gamma="auto" ,degree = 1 ,cache_size = 5000 ) score=cross_val_score(clf,x,y,cv=5,scoring='accuracy').mean() print('{:10s}:{}'.format(kernel,score))

2.11.2 ✌ LabelEncoder编码
x=data.drop(columns=['Age','Survived']) y=data['Survived'] df=pd.DataFrame() # 循环拼接特征矩阵 for i in x.columns: df=pd.concat([df,pd.DataFrame(LabelEncoder().fit_transform(x[i]))],axis=1) y=LabelEncoder().fit_transform(y) for kernel in ["linear","poly","rbf","sigmoid"]: clf = SVC(kernel = kernel ,gamma="auto" ,degree = 1 ,cache_size = 5000 ) score=cross_val_score(clf,df,y,cv=5,scoring='accuracy').mean() print('{:10s}:{}'.format(kernel,score))


