
Pandas 比较日期差异
一、需求
两列数据A, B 分别表示两个时间,已用函数 pd.to_datetime() 做标准化时间处理,A - B 求两列的差值后,发现结果是 0 days 或 -1 days,如图所示:
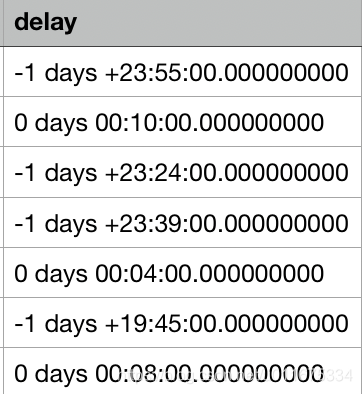
要求:挑选出 > 0 days的部分,其余不处理。
二、解决办法
主要思想是通过加一列 bool 列来判断 delay 列是否是 > 0 days,如果是,标记为True,否则为 False。
代码如下:
import pandas as pd file = pd.read_csv('test.csv') file['delay'] = outfile['A'] - outfile['B'] # 新加一列 islater 列 file['islater'] = (file['delay'].dt.days >= 0)
三、补充
以上代码即可满足需求。此处涉及到 dt.days,目的是取出天数:
1)如果 file['delay'] 是 Series类型,用 file['delay'].dt.days
2)如果 file['delay'] 是 Timedelta类型,用 file['delay'].days
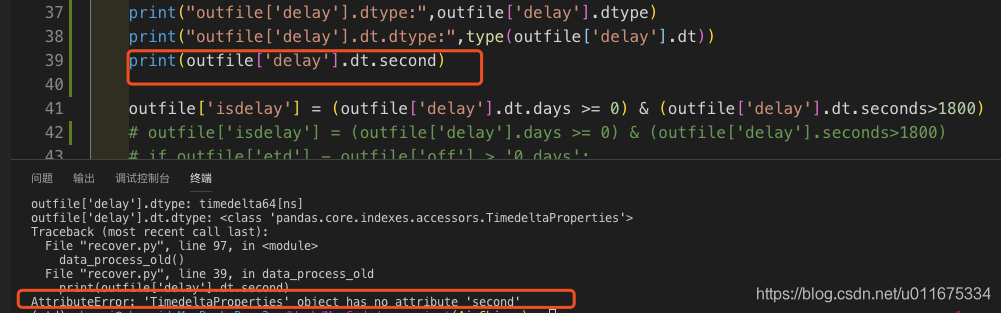
outfile['delay'] 是 timedelta64 组成的 series
timedelta64.dt 就是 timedeltaproperties
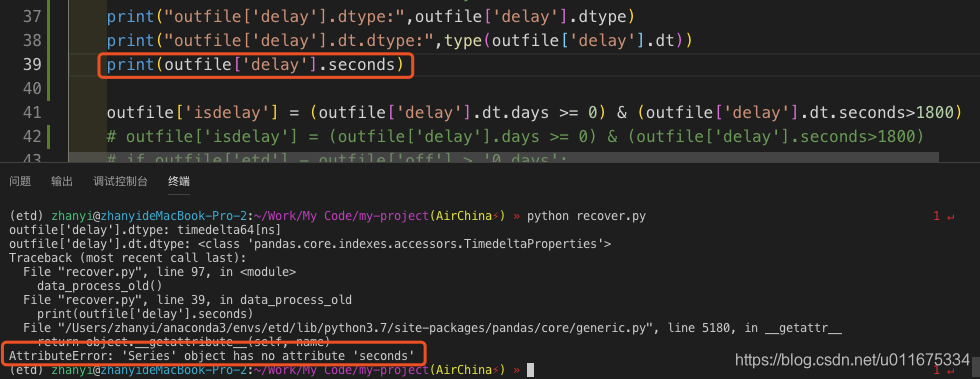
所以 outfile['delay'] 是 Series,具体能用什么函数取决于 Series 中变量的类型。
摘录pandas 文档如下:


