
山顶夕景

已加入开发者社区1280天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝
游客u5i6ra5za62pm
游客u5i6ra5za62pm
游客jqnifbmbcdpuc
游客jqnifbmbcdpuc
ao7a3ape7gkcs
ao7a3ape7gkcs
玫瑰之约
玫瑰之约
蝈蝈996
蝈蝈996
1484505097339577
1484505097339577
游客3lz3gghg4ch7i
游客3lz3gghg4ch7i
1370492753863992
1370492753863992
游客doyztkmautjdi
游客doyztkmautjdi
wukong111-27690
wukong111-27690
游客hsnut2bst4tqi
游客hsnut2bst4tqi
nicholasm4
nicholasm4
技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
CSDN博客专家,华为云云享专家,阿里云专家博主,51CTO专家博主,现为推荐算法工程师,研究领域为AI推荐算法、NLP、图神经网络等,发表EI会议论文一篇,CSDN博客访问量破100万。 CSDN博客id:山顶夕景 微信公众号:古道西风瘦码 知识星球:AI算法乐园
暂无精选文章
暂无更多信息
2022年04月
-
04.24 02:10:58
 发表了文章
2022-04-24 02:10:58
发表了文章
2022-04-24 02:10:58
【PyTorch基础教程12】图像多分类问题
(1)本次图像多分类中的最后一层网络不需要加激活,因为在最后的Torch.nn.CrossEntropyLoss已经包括了激活函数softmax。这里注意softmax的dim参数问题,如下面这个是(3,2)的一个变量,dim = 0 实际上是对第一维的3个变量进行对数化,而dim = 1是对第二维进行操作。
-
04.24 01:26:52发表了文章
2022-04-24 01:26:52
【PyTorch基础教程8】dataset和dataloader
使用torch.nn创建神经网络,nn包会使用autograd包定义模型和求梯度。一个nn.Module对象包括了许多网络层,并且用forward(input)方法来计算损失值,返回output。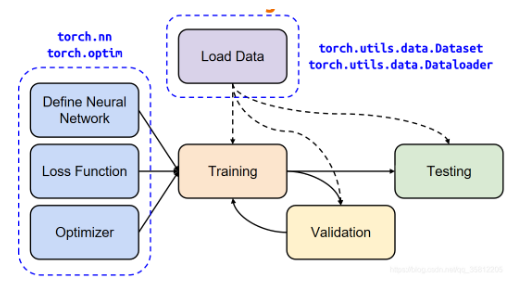
-
04.24 01:23:42发表了文章
2022-04-24 01:23:42
【PyTorch基础教程7】多维特征input
之前的一维特征input,只有一个x和权重w相乘,多维的情况则是xi依次与逐个wi相乘(ps:每行x都这样算,每行即每个样本),可以用向量形式表示: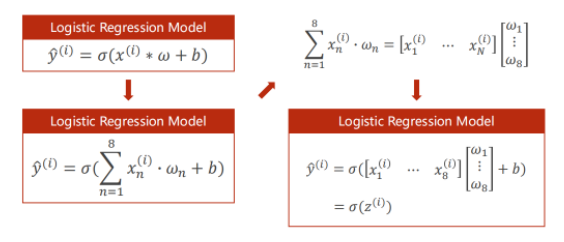
-
04.24 00:08:43发表了文章
2022-04-24 00:08:43
【PyTorch基础教程6】逻辑斯蒂回归
(1)和上一讲的模型训练是类似的,只是在线性模型的基础上加个sigmoid,然后loss函数改为交叉熵BCE函数(当然也可以用其他函数),另外一开始的数据y_data也从数值改为类别0和1(本例为二分类,注意x_data和y_data这里也是矩阵的形式)。 文章目录
-
04.23 22:52:20发表了文章
2022-04-23 22:52:20
【PyTorch基础教程5】Pytorch完整小栗子(学不会来打我啊)
之前在【Pytorch基础教程1】也跑过线性模型的代码(没用框架),这次让我们以该模型为基础用pytorch走一遍一个完整流程。
-
04.23 22:44:49发表了文章
2022-04-23 22:44:49
【树模型与集成学习】(task2)代码实现CART树(更新ing)
输出结果如下,可见在误差范围内,实现的分类树和回归树均和sklearn实现的模块近似。
-
04.23 22:42:02发表了文章
2022-04-23 22:42:02
【PyTorch基础教程4】反向传播与计算图(学不会来打我啊)
一、基础回顾 1.1 正向传递(1)正向传递求loss,反向传播求loss对变量的梯度。求loss实际在构建计算图,每次运行完后计算图就释放了。 (2)Tensor的Grad也是一个Tensor。更新权重w.data = w.data - 0.01 * w.grad.data的0.01乘那坨其实是在建立计算图,而我们这里要乘0.01 * grad.data,这样是不会建立计算图的(并不希望修改权重w,后面还有求梯度)。 (3)下面的w.grad.item()是直接把w.grad的数值取出,变成一个标量(也是为了防止产生计算图)。总之,牢记权重更新过程中要使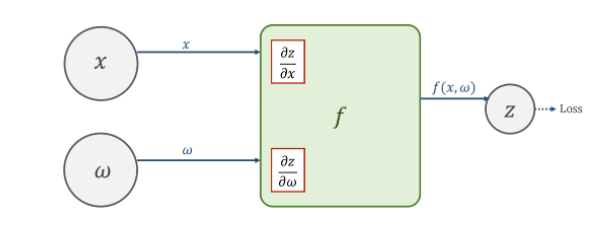
-
04.23 22:35:25发表了文章
2022-04-23 22:35:25
【PyTorch基础教程3】梯度下降
在Pytorch基础教程1中我们用的是基于【穷举】的思想,但如果在多维的情况下(即多个参数),会引起维度诅咒现象。 现在我们利用【分治法】,先对整体采样分割,在相对最低点进一步采样。需要求解使loss最小时的参数取值: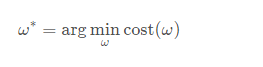
-
04.23 20:04:54发表了文章
2022-04-23 20:04:54
【PyTorch基础教程9】优化器和训练过程
(2)optimizer在一个神经网络的epoch中需要实现下面两个步骤: 梯度置零,梯度更新 -
04.23 19:15:19发表了文章
2022-04-23 19:15:19
【PyTorch基础教程3】梯度下降(学不会来打我啊)
在Pytorch基础教程1中我们用的是基于【穷举】的思想,但如果在多维的情况下(即多个参数),会引起维度诅咒现象。 现在我们利用【分治法】,先对整体采样分割,在相对最低点进一步采样。需要求解使loss最小时的参数取值: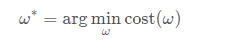
-
04.23 00:27:50发表了文章
2022-04-23 00:27:50
【PyTorch基础教程9】优化器和训练过程
1)每个优化器都是一个类,一定要进行实例化才能使用,比如: -
04.23 00:23:34发表了文章
2022-04-23 00:23:34
【PyTorch基础教程10】构建模型基础(学不会来打我啊)
PyTorch中神经网络构造一般是基于 Module 类的模型来完成的,它让模型构造更加灵活。Module 类是 nn 模块里提供的一个模型构造类,是所有神经网络模块的基类,我们可以继承它来定义我们想要的模型。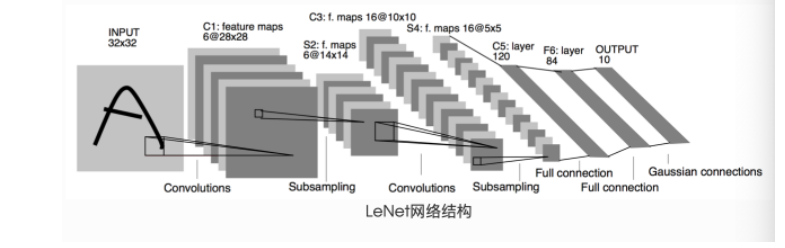
-
04.22 18:26:58发表了文章
2022-04-22 18:26:58
【PyTorch基础教程2】自动求导机制(学不会来打我啊)
回顾我们在完成一项机器学习任务时的步骤: (1)首先需要对数据进行预处理,其中重要的步骤包括数据格式的统一和必要的数据变换,同时划分训练集和测试集。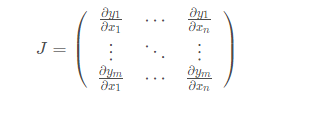
-
04.22 18:23:55发表了文章
2022-04-22 18:23:55
【王喆-推荐系统】特征工程篇-(task3)Embedding基础
(1)Word2vec 的研究中提出的模型结构、目标函数、负采样方法、负采样中的目标函数在后续的研究中被重复使用并被屡次优化。掌握 Word2vec 中的每一个细节成了研究 Embedding 的基础。
-
04.22 18:16:16发表了文章
2022-04-22 18:16:16
【树模型与集成学习】(task1)决策树(上)
类,目标就是将具有 P PP 维特征的 n nn 个样本分到 C CC 个类别中,相当于做一个映射 C = f ( n ) C = f(n)C=f(n) ,将样本经过一种变换赋予一个 l a b e l labellabel。可以把分类的过程表示成一棵树,每次
-
04.22 18:01:23发表了文章
2022-04-22 18:01:23
【PyTorch基础教程11】CNN的细节(学不会来打我啊)
在上面的全连接层中是将input的图像拉成一个向量,但是这样可能会导致:某两个相邻的点在处理后的向量中确实间距很远,这样就会丧失原有的空间结构。而CNN是直接按照图像的空间结构进行保存。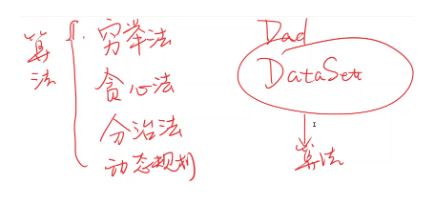
-
04.22 17:50:54发表了文章
2022-04-22 17:50:54
【PyTorch基础教程1】线性模型(学不会来打我啊)
不要小看简单线性模型哈哈,虽然这讲我们还没正式用到pytorch,但是用到的前向传播、损失函数、两种绘loss图等方法在后面是很常用的。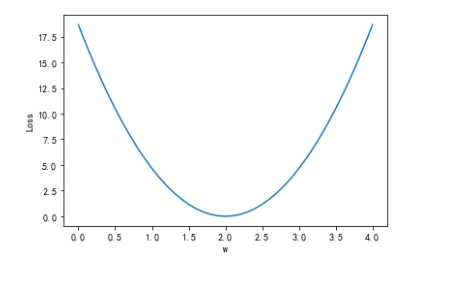
-
04.22 17:47:29发表了文章
2022-04-22 17:47:29
【LeetCode470】用 Rand7() 实现 Rand10()(拒绝采样)
已知 rand_N() 可以等概率的生成[1, N]范围的随机数 那么: (rand_X() - 1) × Y + rand_Y() => 可以等概率的生成[1, X * Y]范围的等概率随机数 即实现了 rand_XY()
-
04.22 17:45:47发表了文章
2022-04-22 17:45:47
【论文代码】GraphSAGE(更新ing)
(4)root_weight (bool, optional): If set to :obj:False, the layer will not add transformed root node features to the output.(default: :obj:True) (5)bias (bool, optional): If set to :obj:False, the layer will not learn an additive bias. (default: :obj:True) (6)**kwargs (optional): Additional arguments
-
04.22 17:41:52发表了文章
2022-04-22 17:41:52
解决报错:‘NoneType‘ object has no attribute ‘origin‘
在跑几个月前跑过PyG的GNN模型时,突然当头一棒报错:'NoneType' object has no attribute 'origin',不要慌,赶紧百度 一顿操作猛如虎,发现没几个帖子讲这个,然后发现google后git
-
04.22 17:06:49发表了文章
2022-04-22 17:06:49
【从0到1开发一个初级DBMS】(task2)数据库的存储结构
大多数计算机系统中都存在多种数据存储类型,根据不同存储介质的速度和成本,可以把它们按层次结构组织起来,如图2-1所示。位于顶部的存储设备是最接近CPU的,其存取速度最快,但是容量最小,价格也最昂贵。离CPU越远,存储设备的容量就越大,不过速度也越慢,每比特的价格也越便宜。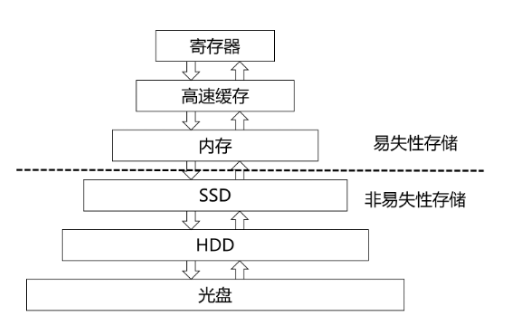
-
04.22 16:57:44发表了文章
2022-04-22 16:57:44
【从0到1开发一个初级DBMS】(task1)DBMS简述
作为数据库系统的核心和基础,数据库管理系统(Data Base Management System,DBMS)应用广泛。DBMS帮助用户实现对共享数据的高效组织、存储、管理和存取,经过数十年的研究发展,已经成为继操作系统之后最复杂的系统软件。
-
04.22 16:52:32发表了文章
2022-04-22 16:52:32
【论文翻译】GCN-Semi-Supervised Classification with Graph Convolutional Networks(ICLR) ———————————————— 版权声明:本文为CSDN博主「山顶夕景」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_35812205/article/details/120575563
基于图的半监督学习:给定的图结构的数据中,只有少部分节点是有标记(label)的,任务就是预测出未标记节点的label。 1.1 经典的分类方法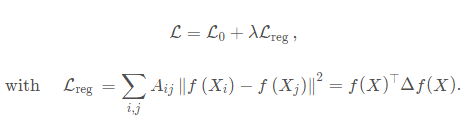
-
04.22 16:36:49发表了文章
2022-04-22 16:36:49
解决:IDEA无法识别maven项目和加载包
之前没用过IDEA,最近因为要跑一个推荐系统模型,线上部分都是java代码,用IEDA时发现即使import项目选了maven,后面还是识别不了maven项目(run不了),于是乎找到本地项目的pom.xml文件,右键点击maven的reinport后又发现速度是真滴龟速,折腾下发现可以通过设置阿里源仓库提速: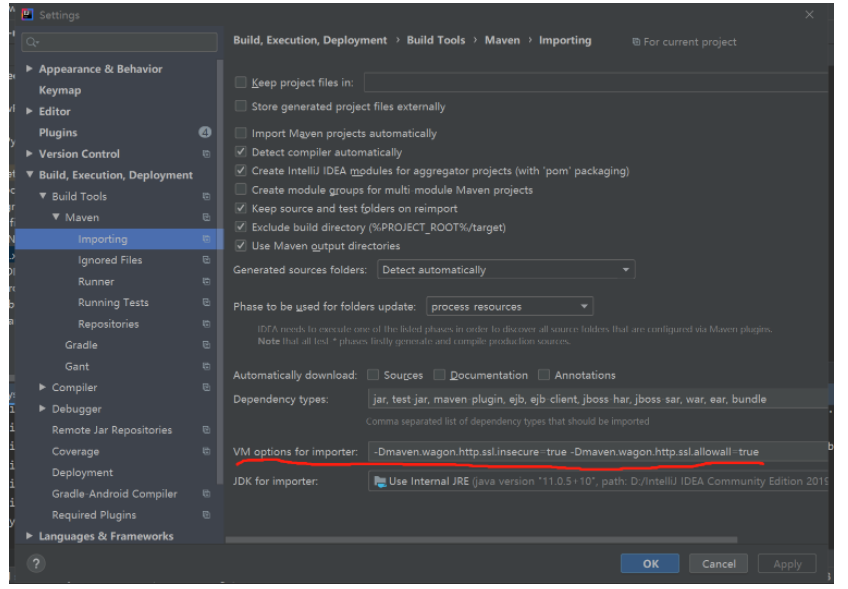
-
04.22 16:34:59发表了文章
2022-04-22 16:34:59
【基础题】不用pandas读取csv文件的成绩数据处理题
(1)用for的i默认是从0开始,如果想要要从1开始遍历,可以对后面的range处理 (2)题目是不用pandas对csv文件(数据之间是逗号间隔)处理,所以需要利用open后readlines后的每行数据,依次找到当前的第一个,位置,然后将前面用过的数据去掉。如下如处理: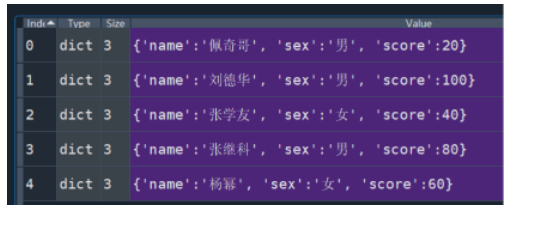
-
04.22 16:26:44发表了文章
2022-04-22 16:26:44
【Pandas】concat用法和栗子
比赛中经常用到数据处理,当需要对某些表的列数据进行拼接时则会用到concatAPI,关于直观上的图形拼接栗子可以参考pandas的concat函数和append方法。 -
04.22 16:24:39发表了文章
2022-04-22 16:24:39
【王喆-推荐系统】开篇词
在所有业界巨头的推荐引擎都由深度学习驱动的今天,作为一名推荐系统从业者,我们不应该止步于: (1)不能满足于继续使用协同过滤、矩阵分解这类传统方法,而应该加深对深度学习模型的理解;加强对大数据平台的熟悉程度,培养结合业务和模型的技术直觉,提高我们整体的技术格局。
-
04.22 16:23:22发表了文章
2022-04-22 16:23:22
【集成学习】(task4)分类问题(逻辑回归、概率分类、决策树、SVM)(更新ing)
【集成学习】(task4)分类问题(逻辑回归、概率分类、决策树、SVM)(更新ing) 步骤1:收集数据集并选择合适的特征: 在数据集上我们使用我们比较熟悉的IRIS鸢尾花数据集。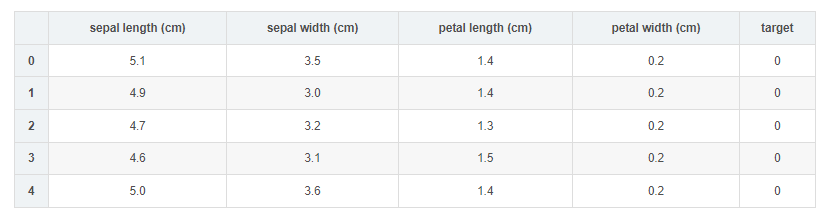
-
04.22 15:43:17发表了文章
2022-04-22 15:43:17
【论文翻译】DeepWalk: Online Learning of Social Representations
本文提出DeepWalk算法——一种用于学习网络中顶点的潜在表示的新方法,这些潜在表示将社会关系编码到连续的向量空间中,以至于能容易地用到统计模型中。DeepWalk将语言建模和无监督特征学习(或深度学习)的最近进展,从单词序列推广到图中。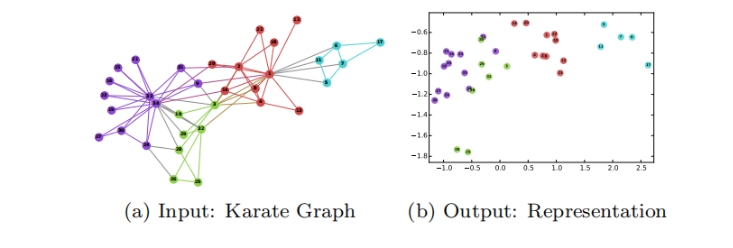
-
04.22 14:42:56发表了文章
2022-04-22 14:42:56
【词的分布式表示】点互信息PMI和基于SVD的潜在语义分析
为了解决上面的数据稀疏问题,传统的方法是引入特征(提取更多和词相关的泛化特征,如词性特征、词义特征和词聚类特征等),但是这类做法耗时耗力;所以到了我们今天的主题——词的分布式表示:
-
04.22 14:28:26发表了文章
2022-04-22 14:28:26
【Pandas】常用基本操作
另一个重要的数据对象是数据框,他的属性包括index、列名和值。由于数据框是更为广泛的一种数据组织形式,许多外部数据文件读取到Python中大部分会采用数据框的形式进行存取,比如数据库、excel和TXT文本。
-
04.22 14:24:43发表了文章
2022-04-22 14:24:43
【LeetCode42】接雨水(dp或双指针or单调栈)
应该学会如何一步步找到优化解,面试时候也是这样(需要体现一个思考的过程): (1)最简单的思路(会超时)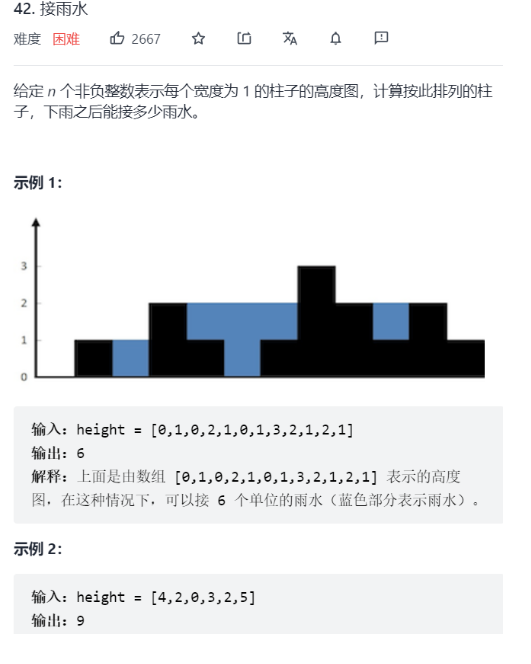
-
04.22 14:22:35发表了文章
2022-04-22 14:22:35
Python求解拉普拉斯矩阵及其特征值
一、背景介绍 1.1 图论基础 定义一(图的邻接矩阵):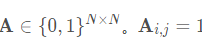
-
04.21 17:26:05发表了文章
2022-04-21 17:26:05
【NLP】(task7)Transformers完成序列标注任务
本文涉及的jupter notebook在篇章4代码库中。如果您正在google的colab中打开这个notebook,您可能需要安装Transformers和🤗Datasets库。将以下命令取消注释即可安装。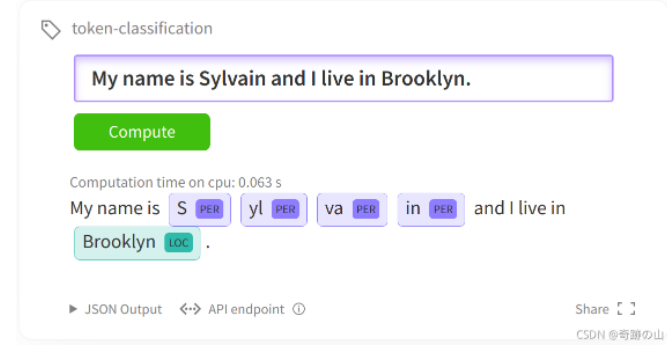
-
04.21 17:07:48发表了文章
2022-04-21 17:07:48
【NLP】(task6)Transformers解决文本分类任务 + 超参搜索
篇章4代码库,也支持使用google colab notebook打开本教程,下载相关数据集和模型。如果在google的colab中打开这个notebook,需要安装Transformers和🤗Datasets库。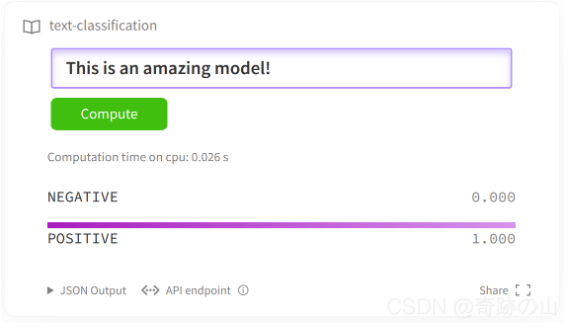
-
04.21 16:31:53发表了文章
2022-04-21 16:31:53
【NLP】(task4)编写BERT模型
(1)通过pycharm、vscode等工具对bert源码进行单步调试,调试到对应的模块再对比看本章节的讲解。 (2)涉及到的jupyter可以在代码库:篇章3-编写一个Transformer模型:BERT (3)本篇章将基于HHuggingFace/Transformers进行学习。
-
04.21 16:10:19发表了文章
2022-04-21 16:10:19
【NLP】(task3下)预训练语言模型——GPT-2
OpenAI GPT-2( https://openai.com/blog/better-language-models/)表现出了令人印象深刻的能力,它能够写出连贯而充满激情的文章,这超出了我们当前对语言模型的预期效果。GPT-2 不是一个特别新颖的架构,而是一种与 Transformer 解码器非常类似的架构。不过 GPT-2 是一个 巨大的、基于 Transformer 的语言模型(只有 Decoder 的 Transformer),它是在一个巨大的数据集上训练的。
-
04.21 15:44:16发表了文章
2022-04-21 15:44:16
【NLP】(task3上)预训练语言模型——BERT
将Transformer模型结构发扬光大的一个经典模型:BERT。 BERT在2018年出现。2018 年是机器学习模型处理文本(或者更准确地说,自然语言处理或 NLP)的转折点。我们对这些方面的理解正在迅速发展:如何最好地表示单词和句子,从而最好地捕捉基本语义和关系?此外,NLP 社区已经发布了非常强大的组件,你可以免费下载,并在自己的模型和 pipeline 中使用。
-
04.21 15:32:41发表了文章
2022-04-21 15:32:41
【李宏毅深度学习CP20】GPT3模型
GPT要做的任务是,预测接下来,会出现的token是什么。举例来说,假设你的训练资料裡面,有一个句子是台湾大学,那GPT拿到这一笔训练资料的时候,它做的事情是这样。你给它BOS这个token,然后GPT output一个embedding,然后接下来,你用这个embedding去预测下一个,应该出现的token是什么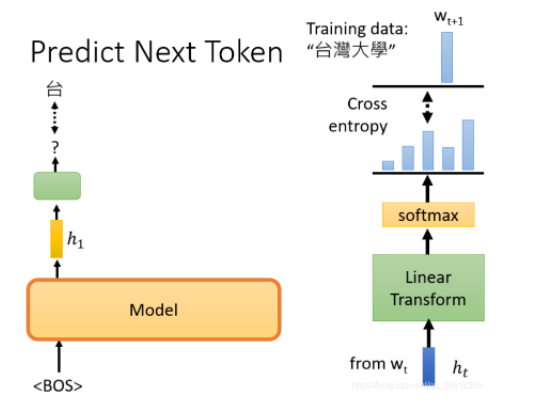
-
04.21 15:15:27发表了文章
2022-04-21 15:15:27
【李宏毅深度学习CP18-19】自监督学习之BERT
BERT的神奇之处在于,在你预训练了一个填空的模型BERT之后,经过微调(Fine-tune),它还可以用于其他完全不同的任务(称为Downstream Tasks下游任务,即实际自己关心的任务),如本次学习介绍的Extraction-based Question Answering (QA)和Natural Language Inference(都是两个句子作输入,前者是一个是文章,一个是问题;后者是一个是前提,一个是结论/假设)。为了看BERT有多牛逼,通常看模型在任务集基准GLUE(9个任务)的平均准确率。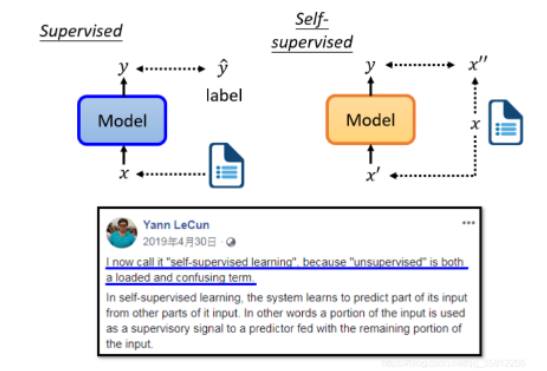
-
04.21 14:25:35发表了文章
2022-04-21 14:25:35
【李宏毅机器学习CP4】(task2)回归+Python Basics with Numpy
第一部分:回归栗子 ps:CP3的部分在上一篇笔记中【李宏毅机器学习】CP1-3笔记了。 1.问题描述 现在假设有10个x_data和y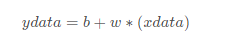
-
04.21 01:50:19发表了文章
2022-04-21 01:50:19
【LeetCode112】路径总和
(1)边界条件: root为NULL要return,root左右子树为NULL时要判断是否为sum (2)递归式:递归遍历左子树和右子树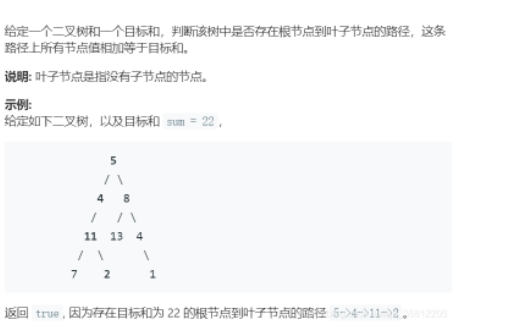
-
04.20 23:30:01发表了文章
2022-04-20 23:30:01
Django框架进阶(大型施工现场。。)
路由是关联URL及其处理函数关系的过程 settings.py文件中ROOT_URLCONF变量指定全局路由文件名称
-
04.20 23:27:40发表了文章
2022-04-20 23:27:40
《The Moon and Sixpence》Day 46
作者在旅途中反复琢磨Charles这样做的冬季和对世俗观点毫不在乎的态度。最后,作者回到伦敦去给Mrs.Strickland汇报在巴黎的情况。作者告诉Mrs.Strickland他在巴黎见到了Charled并且他的离开是因为他想画画,Mrs.Strickkland大吃一惊,丝毫不信。 3.好词佳句 -
04.20 23:27:10发表了文章
2022-04-20 23:27:10
《The Moon and Sixpence》Day 45
relentless adj 顽强的,持续的,坚定地,冷酷的 cuckoo n杜鹃鸟,布谷鸟 v杜鹃叫,不断重复 -
04.20 23:26:46发表了文章
2022-04-20 23:26:46
《The Moon and Sixpence》Day 44
作者和Charles来到一家咖啡厅,作者尝试用情感道义去规劝感化他,也朝他大加嘲讽试图骂醒他但都无济于事。最后,Charles告诉作者他来巴黎的原因是因为他想画画,想成为一个画家。
-
发表了文章
2022-04-28
【推荐算法课程】CS246 大数据挖掘
-
发表了文章
2022-04-28
年轻人创业最关心的13个问题
-
发表了文章
2022-04-28
【AI基础】AUC/ROC指标
-
发表了文章
2022-04-28
【LeetCode剑指offer65】不用加减乘除做加法(位运算)
-
发表了文章
2022-04-28
【LeetCode168】Excel表列名称(从1开始的进制转换)
-
发表了文章
2022-04-28
【LeetCode剑指offer】二叉搜索树的最近公共祖先(迭代or递归)
-
发表了文章
2022-04-28
【LeetCode24】两两交换链表中的节点(递归)
-
发表了文章
2022-04-28
【LeetCode剑指offer12】矩阵中的路径(dfs回溯)
-
发表了文章
2022-04-28
【LeetCode剑指offer47】礼物的最大价值(简单dp)
-
发表了文章
2022-04-28
【kaggle】特征工程 trick
-
发表了文章
2022-04-28
【Spark】(task4)SparkML基础(数据编码)
-
发表了文章
2022-04-28
【LeetCode剑指offer34】二叉树中和为某一值的路径(dfs回溯)
-
发表了文章
2022-04-28
【Pytorch基础教程27】DeepFM推荐算法
-
发表了文章
2022-04-28
【LeetCode163】缺失的区间(to_string)
-
发表了文章
2022-04-28
【LeetCode剑指offer57 II】和为s的连续正数序列(用vector模拟滑动窗口)
-
发表了文章
2022-04-28
【Airflow】工作流自动化和调度系统
-
发表了文章
2022-04-28
【LeetCode剑指offer26】树的子结构(递归)
-
发表了文章
2022-04-28
【PyTorch基础教程23】可视化网络和训练过程
-
发表了文章
2022-04-28
【AI基础】bias和variance的奇妙关系
-
发表了文章
2022-04-28
【LeetCode剑指offer04】二维数组中的查找(简单数学)
滑动查看更多
暂无更多信息
暂无更多信息