 封神
封神
封神_个人页
封神


文章
37
问答
259
视频
0
个人介绍
专注在大数据分布式计算、数据库及存储领域,拥有13+年大数据引擎、数据仓库、宽表引擎、平台研发经验,6年云智能大数据产品技术一号位经验,10年技术团队管理经验;云智能技术架构/云布道师; 研发阿里历代的大数据技术产品包括ODPS、DLA、ADB,最近五年主导宽表引擎研发、DLA、ADB湖仓研发;
擅长的技术
- Java
- 数据库
- 数据仓库
- Cloud Native
- Serverless
- 大数据
- 数据处理
- 分布式计算
- OLAP
- NoSQL
获得更多能力

通用技术能力:
暂时未有相关通用技术能力~
云产品技术能力:
-
ACP
-
阿里云数据仓库工程师ACP认证(Alibaba Cloud Certified Professional - Data Warehouse)
获得于2022-04-12 21:29:49
-
阿里云数据仓库工程师ACP认证(Alibaba Cloud Certified Professional - Data Warehouse)
-
ACA
-
阿里云云数据库助理工程师认证(ACA)
获得于2021-04-28 17:30:12
-
阿里云云数据库助理工程师认证(ACA)
阿里云技能认证
详细说明-
发表了文章 2016-04-20
2012年阿里技术嘉年华会后感
这个周末参加了《阿里技术嘉年华》,这个可以说算是国内一流的免费交流会了。多个公司的技术牛人聚集在杭州共同探讨IT技术。当然很多是阿里的同学,不过也有百度、腾讯、网易,甚至还有小米、360、证劵交易所公司的同学。阿里提供了这个么好的舞台,非常感谢。也期待更多的公司来参加举行嘉年华。
-
 提交了问题
2016-04-19
提交了问题
2016-04-19
在e-mapreduce跑spark streaming,计划1分钟打印一条日志发现没有打印
-
提交了问题
2016-04-18
在e-mapreduce执行hive(hadoop)脚本,出现问题permisson denied:user=root,access=EXECUTE
-
提交了问题
2016-04-18
在E-Mapreduce运行hadoop job失败,java.lang.reflect.InvocationTargetException
-
提交了问题
2016-04-16
创建e-mapreduce集群后,无法ping通master主机
-
提交了问题
2016-04-15
在e-mapreduce跑hadoop mr报错,com.aliyun.oss.OSSException: AccessDenied
-
发表了文章 2016-04-14
阿里封神谈hadoop生态学习之路
在大数据时代,要想个性化实现业务的需求,还是得操纵各类的大数据软件,如:hadoop、hive、spark等。笔者(阿里封神)混迹Hadoop圈子多年,经历了云梯1、ODPS等项目,目前base在E-Mapreduce。在这,笔者尽可能梳理下hadoop的学习之路。
-
提交了问题
2016-04-14
hadoop hive任务失败,原因是GC overhead limit exceeded (OOM)
-
提交了问题
2016-04-14
hadoop hive 任务失败,终端提示 FAILED: Execution Error, return code 1?
-
提交了问题
2016-04-13
使用emapreduce时,提交的hadoop yarn的job,JOB状态一直是ACCEPTED状态
-
发表了文章 2016-04-12
YARN(hadoop2)框架的一些软件设计模式
yarn版本的hadoop无论是从架构上面还是软件设计的层面上面都比原始的hadoop版本有较大的改进。在架构方面,我们认为yarn模式是新一代的框架,这个在官方等丛多的资料中说明得很详细了。在软件设计方面,我认为主要有以下的一些大的方面的改进:服务生命周期管理模式、事件驱动模式、状态驱动模式
-
提交了问题
2016-04-12
hadoop mapreduce与spark,我该如何选择呢?
-
提交了问题
2016-04-12
hadoop mapreduce遍历的目录含有子目录报错
-
提交了问题
2016-04-11
如果E-mapreduce的master 密码忘了的话,我怎么找回来呢
-
提交了问题
2016-04-11
hadoop mr EOFException的常见原因
-
提交了问题
2016-04-11
hadoop mr 遇到ShuffleRefusedException怎么办?
-
提交了问题
2016-04-11
hadoop mr Task process exit with nonzero status of 134
-
提交了问题
2016-04-11
hadoop mr java.io.IOException: The temporary job-output directory xxx/path/_temporary doesn't exist!
-
提交了问题
2016-04-11
请问hadoop mr Task attempt_xxx_xx_xx failed to report status for 605 seconds. Killing!是什么原因
-
提交了问题
2016-04-11
为什么我的hadoop作业中有一个reduceTask运行时间明显比其他reduceTask长?
-
提交了问题
2016-04-11
为什么我的hadoop作业中某些mapTask成功了却还会重跑?
-
提交了问题
2016-04-11
E-Mapreduce如何处理RDS的数据
-
提交了问题
2016-04-08
我的hadoop mapreduce Job有killed tasks,是怎么回事
-
提交了问题
2016-04-08
hadoop mapreduce运行job task报OutOfMemoryError错误
-
提交了问题
2016-04-08
Streaming/Hive作业在调用Python脚本时报错
-
提交了问题
2016-04-08
为什么在hadoop Shell终端停不了job?
-
发表了文章 2016-04-08
E-Mapreduce如何处理RDS的数据
目前网站的一些业务数据存在了数据库中,这些数据往往需要做进一步的分析,如:需要跟一些日志数据关联分析,或者需要进行一些如机器学习的分析。在阿里云上,目前E-Mapreduce可以满足这类进一步分析的需求。
-
提交了问题
2016-04-08
E-mapreduce是否提供实时计算的功能
-
发表了文章 2016-03-31
阿里封神-大数据处理技术漫谈
以前一篇博客,从宏观描述了云梯1当时整体生态,年底了,笔者再梳理下软件栈,主要以开源软件为主,闭源不谈。大数据发展至今,开源软件层出不穷,也去解决了不同的问题,笔者试图去弄清楚这些,分门别类,后面也可以参照下。由于笔者知识面有限,难免会出现一些偏颇,不全,不正确,还请指正。后面也会有很多新的软件出现
-
提交了问题
2016-03-25
spark1.6连接cassandra报错
-
发表了文章 2016-03-10
为什么选择ali-E-MapReduce
E-MapReduce是构建于阿里云ECS弹性虚拟机之上,利用开源大数据生态系统,包括但不限于Hadoop、Spark、Hbase,为用户提供集群、作业、数据等管理的一站式大数据处理分析服务。我们提供的软件基本都是开源的软件,会有一些性能的优化,但是绝对不引入任何不兼容的改动。
暂无更多信息
-
 发表了文章
2023-05-22
发表了文章
2023-05-22
离在线一体化云原生数仓发展思考
-
发表了文章
2023-05-06
读书笔记《数据密集型应用系统设计》- 数据存储与检索
-
发表了文章
2023-05-04
读书笔记《数据密集型应用系统设计》- 高可靠性、高可展性、可维护性 & 数据模型与查询语言
-
发表了文章
2019-06-21
欢迎加盟云智能数据库BigData NoSQL团队
-
发表了文章
2018-11-27
HBase实战 | HBase在人工智能场景的使用
-
发表了文章
2018-11-06
HBase多模式
-
发表了文章
2018-04-17
云HBase集群的规划
-
发表了文章
2018-03-21
再谈全局网HBase八大应用场景
-
发表了文章
2017-09-22
学术界关于HBase在物联网/车联网/互联网/金融/高能物理等八大场景的理论研究
-
发表了文章
2017-09-01
ApsaraDB for HBase - 规格的的选择
-
发表了文章
2017-08-13
HBase全网最佳学习资料汇总
-
发表了文章
2017-05-18
HBase Phoenix助力海量数据实时分析
-
发表了文章
2017-05-17
欢迎加入阿里云 HBase+Spark技术交流群
-
发表了文章
2017-03-13
云HBase建设之开篇
-
发表了文章
2017-03-13
云HBase助力物联网建设
-
发表了文章
2017-02-23
云时代的大数据存储-云HBase
-
发表了文章
2017-01-19
Hadoop黑客赎金事件解读及防范
-
发表了文章
2016-12-22
分布式(hadoop)内核研发面试指南
-
发表了文章
2016-12-01
ROLAP与大数据
-
发表了文章
2016-10-27
阿里云开源大数据内核团队招聘人才
滑动查看更多
-
 回答了问题
2020-03-22
回答了问题
2020-03-22
请问java有必要转大数据吗?
目前大数据基本是用java的。不过java要必要转大数据吗,看起来就不太懂大数据。 大数据其实分很多领域:有基础组件、有大数据业务系统、也有机器学习等。 就看题目理解的大数据是什么,想做什么。
赞0 踩0 评论0 -
回答了问题
2020-03-22
能不能使用 Presto 实现 C* 的表关联?
可以参考使用阿里云的数据湖分析服务:https://www.aliyun.com/product/datalakeanalytics
赞0 踩0 评论0 -
回答了问题
2020-03-22
RDS如何做大数据分析
可以参考使用阿里云数据湖分析服务DLA
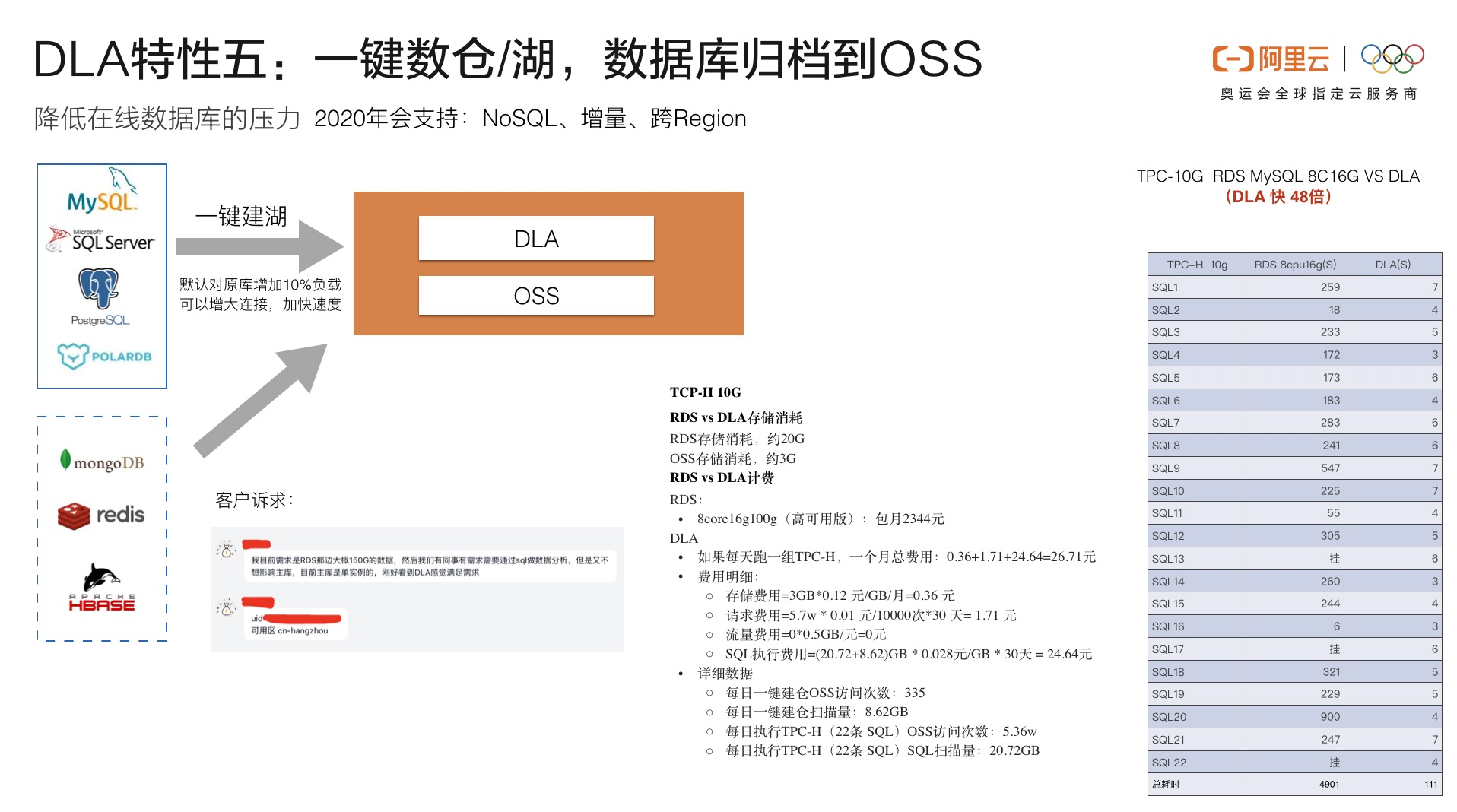
具体参考:https://help.aliyun.com/document_detail/129965.html?spm=a2c4g.11186623.6.592.1cf6d4fbVj5JL0
赞0 踩0 评论0 -
回答了问题
2020-03-22
如何进行探索性数据分析(EDA)?
可以使用阿里云数据湖分析服务DLA来做探索性的分析。
赞0 踩0 评论0 -
回答了问题
2020-03-22
重置了 dla 的主用户密码, 用 mysql client 连接不了数据库, 这个怎么处理?
这个账号没有权限的,文中有一些提示的。
赞0 踩0 评论0 -
回答了问题
2020-03-22
针对高校大数据解决方案有哪些?
hadoop 还是过于复杂,可以考虑 阿里云数据湖分析服务DLA。大数据的能力、数据库的体验。
赞0 踩0 评论0 -
回答了问题
2020-03-22
你眼里的大数据是什么?
未来的大数据一定的按需付费Serverless化的。当前很多项目的大数据的实施成本过高。
赞0 踩0 评论0 -
回答了问题
2020-03-22
您有大数据相关经验吗?如果有,请分享一下。
最近几年业内分享大数据的技术与案例比较多,不过大数据发展还是比较快的。 从10年前的google三篇论文,到最近的 很火的Serverless的数据湖分析服务,发展还是相当快的。
赞0 踩0 评论0 -
回答了问题
2020-03-22
大数据和python有什么区别
核心在于科学家及分析师需要一种简单实用的语言,而Python比较合适,或者Python后续的设计就倾向于此。
赞0 踩0 评论0 -
回答了问题
2020-03-22
Apache spark如何在数据湖中更新海量原始数据?
hudi的出现确实为了解决类似的问题
赞0 踩0 评论0 -
回答了问题
2020-03-22
为什么Hadoop可用于大数据分析?
哲学的回答:因为hadoop设计就是为了解决大数据分析问题,如果不能解决就没有hadoop 实际的原因:hadoop核心分为3个层次:存储hdfs、计算mr&tez、调度yarn 不过最近随着社区及云的发展,慢慢演变为:存储HDFS换成了S3或者OSS,调度Yarn换成了k8s,再计算引擎百花齐放,比如spark、比如各家云产商提供的数据湖分析服务,bigquery,阿里云数据湖分析dla等。
赞0 踩0 评论0 -
回答了问题
2020-03-22
Flink相比Spark Streaming有什么区别?
简单讲:flink是实时流,Spark Streaming是用批模拟流。
赞0 踩0 评论0 -
回答了问题
2020-03-22
Spark 的提交方式?
还有一种主流的方式,是直接提交到k8s
赞0 踩0 评论0 -
回答了问题
2020-03-22
如何排查伸缩活动异常?
一般需要有监控的服务,设定一定的预期,后续检测是否符合预期。
一般情况下,弹性伸缩都有一定的度,比如min ~ max ,如果不在此区间视为异常。
赞0 踩0 评论0 -
回答了问题
2020-03-22
如何使用数据湖分析DLA分析JSON的数据?
可以参考:https://help.aliyun.com/document_detail/109858.html?spm=a2c4g.11186623.6.626.13cf7aaebUvMd1
赞0 踩0 评论0 -
提交了问题
2020-03-22
如何使用数据湖分析DLA分析JSON的数据?
-
回答了问题
2020-03-22
serverless云数据库如何调用
阿里云有一款数据湖分析DLA:https://www.aliyun.com/product/datalakeanalytics 是Serverless的数据湖分析服务 可以了解下
赞0 踩0 评论0 -
回答了问题
2020-03-22
什么是云计算?什么是大数据?二者有何联系?
云计算与大数据在网上单独讲的挺多的,可以看看。我讲下我的理解: 从业务层面看:云计算与大数据是两个业务,在公司很小,业务量很小的时候。往往是没有大数据的。在ecs上买几个机器就可以解决问题。当数据量多了以后,慢慢会有云计算的技术。 从技术层面看:云计算往往是IAAS层的,大数据一般是在PAAS层,PAAS层使用IAAS的技术。不过有一些大数据到业务层面,就直接到SAAS层了。
今天 AI大数据云计算 是非常能代表未来的词汇,所以就用这个这些词汇了。假以时日,可能会出现其他的此。
赞0 踩0 评论0 -
回答了问题
2020-03-22
弹性伸缩如何事件通知?
一般是调度程序在添加服务器时,主动推送一个消息到MQ。另外一种是主动轮询,一般效率相对低一点。不过 如果不敏感的业务,其实也是可以解决问题的。
赞0 踩0 评论0 -
回答了问题
2020-03-22
为什么RDS那么贵?
RDS是多种规格的,在一般的mysql的基础之上提供了很多好用的功能。 - 保障性能与稳定性肯定是必要的 - 提供HA切换机制,很多是2台起步的 - 支持性能分析 - 提供数据备份的机制 - 支持跟数据湖分析DLA一起联合分析 等等
赞0 踩0 评论0
滑动查看更多
暂无更多信息