探索云世界
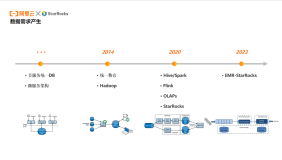
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。

本文展示了如何使用阿里云向量检索 Milvus 版和灵积(Dashscope)提供的通用千问大模型能力,快速构建一个基于专属知识库的问答系统。在示例中,我们通过接入灵积的通义千问 API 及文本嵌入(Embedding)API 来实现 LLM 大模型的相关功能。
阿里云计算平台事业部开源大数据产品总监陈守元围绕EMR、Flink Streaming Lakehouse、 Elasticsearch、Milvus等产品发布展开分享介绍。
本文根据 StarRocks Summit 2023 演讲实录整理而成,主要分享了基于 StarRocks 和 Paimon 打造湖仓分析方案及背后的技术原来和未来规划。
通过一系列优化,我们将 Paimon x Spark 在 TpcDS 上的性能提高了37+%,已基本和 Parquet x Spark 持平,本文对其中的关键优化点进行了详细介绍。

本文从轻喜到家的历史技术架构与痛点问题、架构升级需求与 OLAP 选型过程、最新技术架构及落地场景应用等方面,详细介绍了轻喜到家基于 EMR-StarRocks 构建实时湖仓分析平台实践经验。
EMR Notebook 是一个 Serverless 化的交互式数据分析和探索平台,满足大数据和 AI 融合下的数据处理需求,现已开启免费公测,欢迎体验!

本文从用友畅捷通公司介绍及业务背景;数据仓库技术选型、实际案例及未来规划等方面,分享了用友畅捷通基于阿里云 EMR StarRocks 搭建实时湖仓的实战经验。
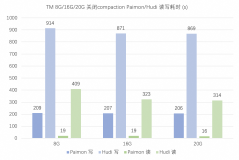
Apache Paimon 和 Apache Hudi 作为数据湖存储格式,有着高吞吐的写入和低延迟的查询性能,是构建数据湖的常用组件。本文在阿里云EMR上,针对数据实时入湖场景,对 Paimon 和 Hudi 的性能进行比对,并分别以 Paimon 和 Hudi 作为统一存储搭建准实时数仓。
1月20日深圳阿里中心,阿里云 x StarRocks 邀你现场体验云上极速湖仓实战营,从 0-1 轻松上手 StarRocks 湖仓分析。

阿里云 EMR Serverless Spark 版,以 Spark Native Engine 为基础,旨在提供一个全托管、一站式的数据开发平台。诚邀您参与 EMR Serverless Spark 版免费测试,体验 100% 兼容 Spark 的 Serverless 服务:https://survey.aliyun.com/apps/zhiliao/iscizrF54
本文根据 2023 云栖大会,阿里云资深技术专家、阿里云开源大数据平台EMR负责人李钰演讲实录整理而成。
10月14日13:00-17:30,Apache Kyuubi & Celeborn 社区将在杭州举办「Apache Kyuubi & Celeborn (Incubating) 助力 Spark 拥抱云原生」Meetup,欢迎报名参会!
背景:阿里云E-MapReduce集群(简称EMR集群)部分节点需要下线迁移,但集群资源常年跑满,诉求是节点下线迁移过程中不影响任一任务执行。 本次方案基于Yarn Node Labels的特性进行资源隔离后下线。 下期对官网Graceful Decommission of YARN Nodes的方案进行验证,参考:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html。
阿里云全链路数据湖开发治理解决方案能力持续升级,发布2.0版本。解决方案包含开源大数据平台E-MapReduce(EMR) , 一站式大数据数据开发治理平台DataWorks ,数据湖构建DLF,对象存储OSS等核心产品。支持EMR新版数据湖DataLake集群(on ECS)、自定义集群(on ECS)、Spark集群(on ACK)三种形态,对接阿里云一站式大数据开发治理平台DataWorks,沉淀阿里巴巴十多年大数据建设方法论,为客户完成从入湖、建模、开发、调度、治理、安全等全链路数据湖开发治理能力,帮助客户提升数据的应用效率。
8月17日19点,云原生湖仓线上Meetup,深入解析 StarRocks 存算分离,多位大咖分享,干货满满,快来报名!~

7月15日下午14:00-17:00,《上海线下Meetup I 云上StarRocks极速湖仓》,欢迎参加!

喜马拉雅和阿里云的合作,正走在整个互联网行业的最前沿,在新的数据底座之上,喜马拉雅的AI、大数据应用也将大放光彩。本文摘自《云栖战略参考》

网易数帆软件工程师潘成,在 ASF CommunityOverCode Asia 2023(北京)的分享。
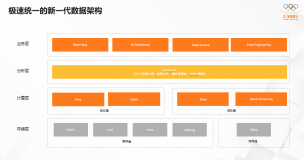
EMR Serverless StarRocks + DataWorks ,开启极速分析体验
阿里云向量检索 Milvus 版正式开启公测,诚邀广大开发者及企业用户参与公测,赋能智能检索,解锁 AI 潜能。
Json实现根据关键词搜索请求淘宝商品列表数据方法,淘宝商品列表数据接口,淘宝API接口申请指南

10月14日14:00-17:30,Apache Kyuubi & Celeborn 社区将在杭州举办「Apache Kyuubi & Celeborn (Incubating) 助力 Spark 拥抱云原生」Meetup,本次 Meetup 邀请到阿里云、网易数帆、Cisco、丁香园、Shopee 等技术大咖深入探讨交流基于 Apache Kyuubi & Celeborn 的技术实践,助力 Spark 拥抱云原生!讲师/嘉宾简介周克勇(一锤):阿里云 EMR Spark 引擎负责人,Apache Celeborn (Incubating) 的发起人潘成:网易数帆大数据技术专家,Apache Kyuubi PMC Member,Apache Celeborn (Incubating) PPMC Member朱夷(AngersZhuuuu):Shopee 技术专家, Spark PIC。 Apache Celeborn(Incubating) PPMC/Apache Spark active Contributor/ Apache HDFS/YARN contributorHe Zhao:Data Engineer at CiscoPengqi Li:Data Engineer at Cisco陈福:Apache Kyuubi PMC Member / Apache Celeborn (Incubating) Committer / 丁香园大数据基础平台负责人
阿里云 EMR OLAP 团队与 StarRocks 社区联合出品,玩转云上 StarRocks3.0 湖仓分析训练营,围绕 StarRocks3.0 系列解读、EMR Serverless StarRocks 存算分离功能与应用场景介绍,开启数据分析新范式!
Json实现根据商品ID请求1688商品详情数据方法,1688商品详情API接口,1688API接口申请指南
Json实现根据商品ID请求京东商品详情数据方法,京东商品详情API接口,京东API接口申请指南
Json实现根据商品ID请求亚马逊商品详情数据方法,亚马逊商品详情API接口,亚马逊API接口申请指南
阿里云开源大数据 EMR 在 CommunityOverCode Asia 的精彩分享。
本次测评报告我将从功能、稳定性、性能、运维、成本和收益等方面对EMR Serverless StarRocks进行评估,以确保该产品能够满足业务需求并提供有用的参考信息。通过本次测评,我希望能够为用户提供有用的参考信息,帮助他们做出明智的决策。
随着信息技术的发展和网络应用在我国的普及,针对我国境内信息系统的恶意网络攻击也越来越多,并且随着黑客攻击技术的不断地更新,网络犯罪行为变得越来越难以应对,用户日常访问的网站是否安全对于普通网民而言难以辨别,保护人民不受不法侵害也是难上加难。如何识别网站的潜在危险性,以及网站出现安全性问题该如何防御,尽可能减少网站被攻击后造成的实际损失,是目前迫切需要解决的难题。 本文使用VMware虚拟机技术模拟真实的网络环境,使用渗透测试技术对模拟网络进行薄弱点测试信息收集、攻击测试等,再现了渗透测试的重要流程和技术方法。在对目标主机实施渗透测试时,会从系统层面和Web层面两个维度进行测试,扫描出存在的漏洞
低代码是一个新兴的技术,有着非常明确而鲜明的技术特点,比如:拖拽组件、可视化编程、零代码编程等等。但传统软件企业在进行技术融合时却往往是困难重重,旧有的技术积累很难能继承应用过来。本文作为一组技术分析,来逐一分解低代码背后的支撑技术。今天我们给大家带来的一个专题分析是,低代码平台的专有存储技术。