
Flink的DebeziumDeserializationSchema deserialize 无法执行什么原因?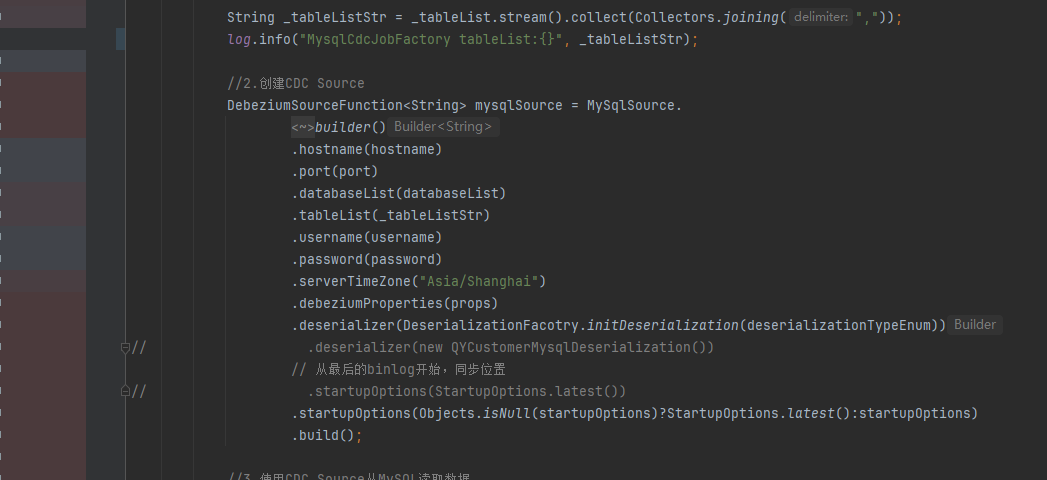
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink作业中使用DebeziumDeserializationSchema时遇到无法执行的情况,可能涉及多个原因,具体包括但不限于以下几点:
Schema不匹配问题:
'debezium.snapshot.mode'='never' 配置时,可能导致从Binlog起始处读取数据,而此时的表结构与当前实际表结构不一致,引发错误[1]。DEFAULT (now()),也会导致deserialization失败[1]。字段缺失问题:
网络或反压问题:
java.io.EOFException或Connection reset错误[1]。可以通过调整参数'debezium.connect.keep.alive.interval.ms' = '40000'来缓解网络问题,或优化作业解决反压问题。存储引擎不识别:
BLACKHOLE),或者在只读实例上读取数据,也可能引发异常[1]。Server-id冲突:
server-id与其他作业或工具冲突,将导致错误[1]。需确保为每个并行度配置全局唯一的server-id。特定字段解析错误:
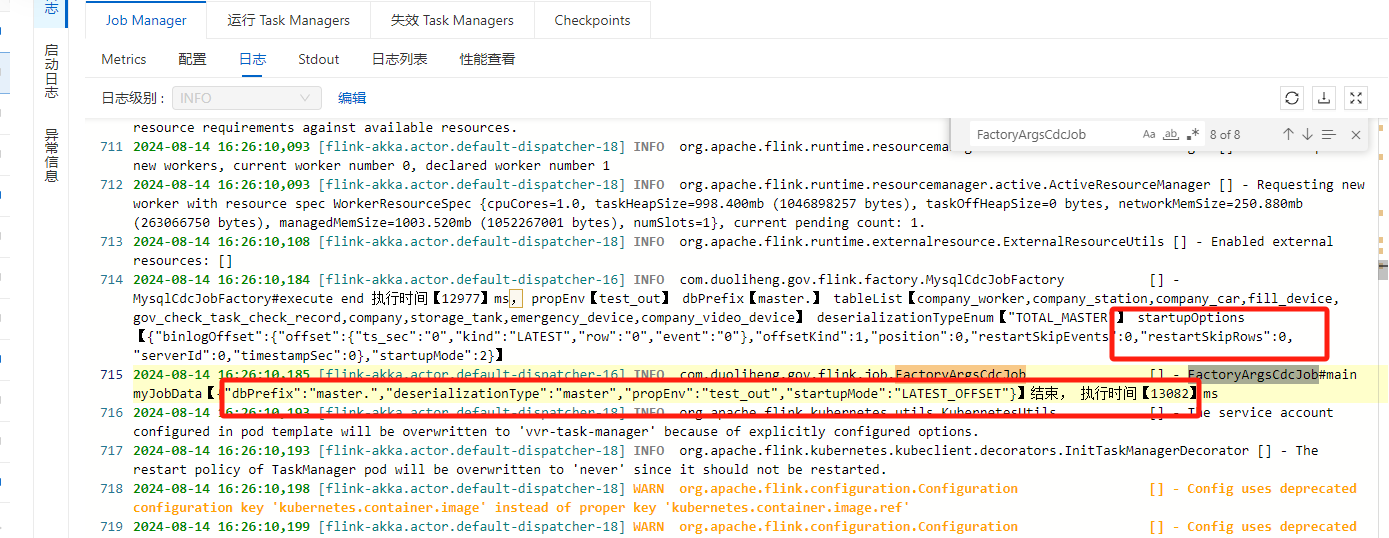
xxx is not a valid field name的错误,表明Debezium在处理Binlog事件时,遇到了在表结构中不存在的字段名称,这通常是因为DDL声明与实际表结构不匹配[1]。解决这些问题通常需要根据错误日志的具体提示,采取相应的措施,如调整配置参数、修正表结构一致性、优化网络条件或作业配置等。
相关链接
CDC问题 报错:Encountered change event for table xxx.xxx whose schema isn't known to this connector https://help.aliyun.com/zh/flink/support/faq-about-cdc
Debezium 配置选项 https://help.aliyun.com/zh/flink/developer-reference/debezium
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

